本文将介绍基于深度学习YOLOv8\YOLOv5+PySide6+SQLite的花卉检测与识别系统,该系统基于YOLOv8算法,并与YOLOv5版本进行比较,该系统不仅实现了对花卉的精准识别和分类,还提供了包括用户认证管理、模型快速切换及界面个性化定制在内的多项功能,获取方式如下。
wx供重浩:创享日记
那边对话框发送:花卉61
获取完整源码源文件+数据集+训练好模型+配置和修改文档+配套设计说明文章+远程操作等
一、项目效果展示
基于深度学习YOLOv8\YOLOv5+PySide6的花卉识别鲜花识别检测系统设计
二、设计系统介绍
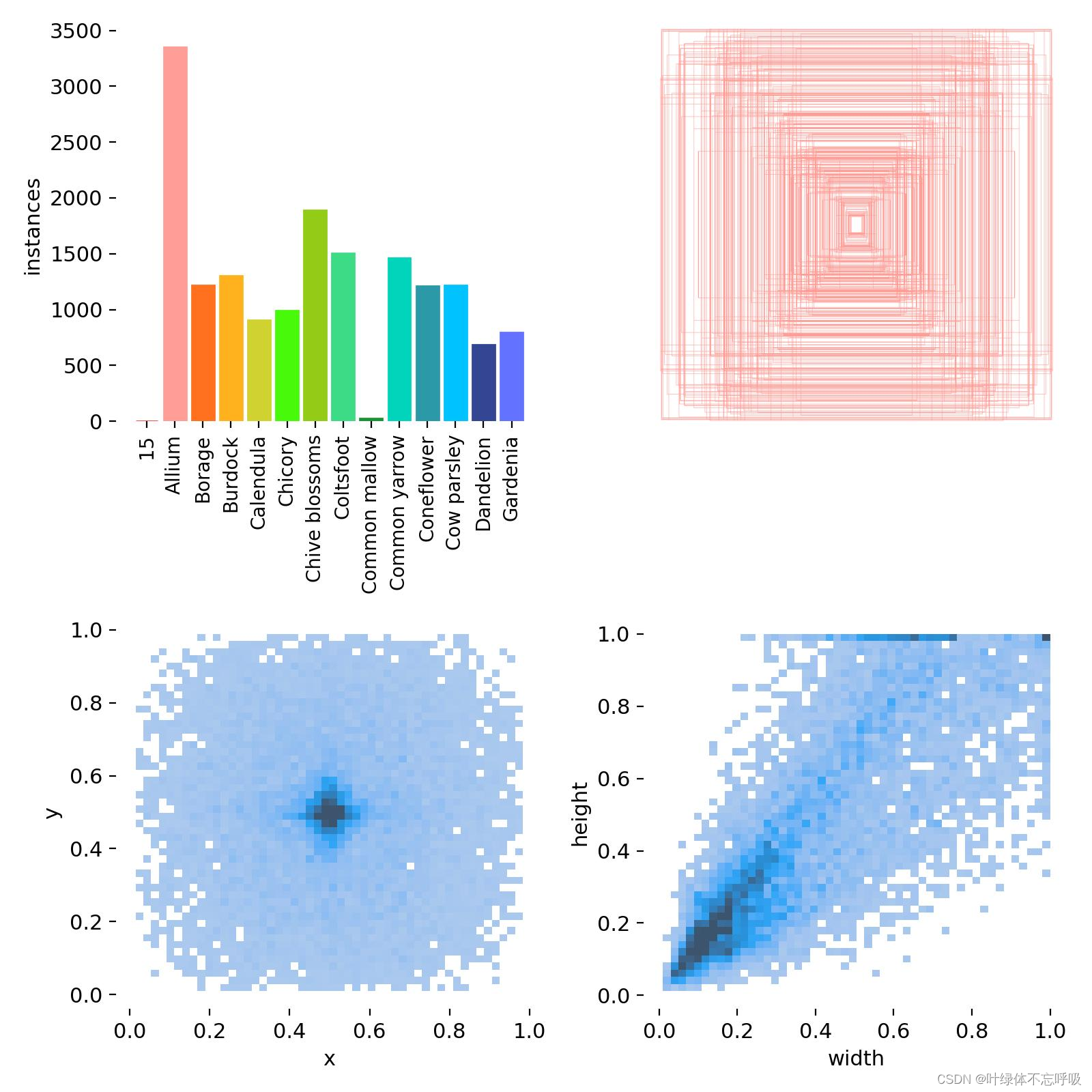
1、数据集介绍
在花卉识别研究中,一个精心设计的数据集是训练精确AI模型的基石。我们创建了一个包含10513张花卉图片的数据集,旨在推动该领域的技术发展。该数据集分为训练集、验证集和测试集,分别为9131张、919张和463张,确保模型在多样化数据上的训练和独立数据上的验证。
每张图片都经过了严格的预处理,包括方向校正、去除EXIF信息、统一分辨率调整至640x640像素,并应用自适应均衡化技术增强对比度,以突出花卉特征,优化模型学习效果。
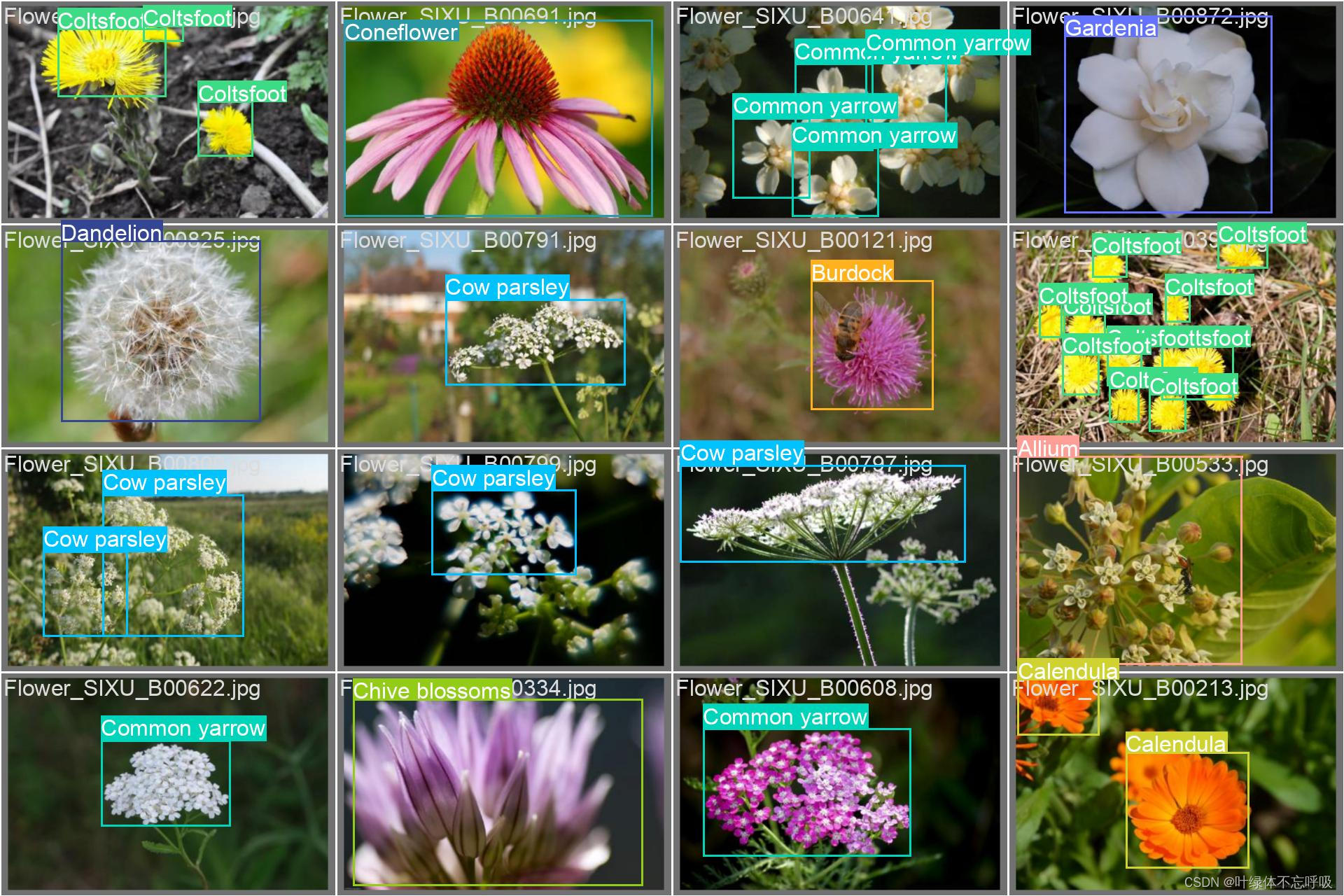
该数据集中有13个类,即该模型能识别分类13种花卉,对应关系如下:'Allium': "大葱花", 'Borage': "琉璃苣", 'Burdock': "牛蒡", 'Calendula': "金盏花", 'Chicory': "菊苣", 'Chive blossoms': "韭菜花", 'Coltsfoot': "款冬", 'Common mallow': "锦葵",'Common yarrow': "洋蓍草", 'Coneflower': "金光菊", 'Cow parsley': "欧芹", 'Dandelion': "蒲公英",'Gardenia': "栀子花"。
在对数据集进行详尽分析后,我们发现了一些关键的分布特点。类别的不平衡性是一个显著的问题,这可能导致模型偏向于识别数量较多的类别。例如,Allium类花卉在数据集中占比较高,而Gardenia类则较少。为了解决这一问题,我们采用马赛克9数据增强技术,具体的数据集特性指标如下(在源码中有这些图表),具体代表什么可以详见配套论文。
2、系统介绍
深度学习技术栈:YOLOv8、YOLOv5
GUI(可视化操作界面)技术栈:PySide6
数据库技术栈:SQLite
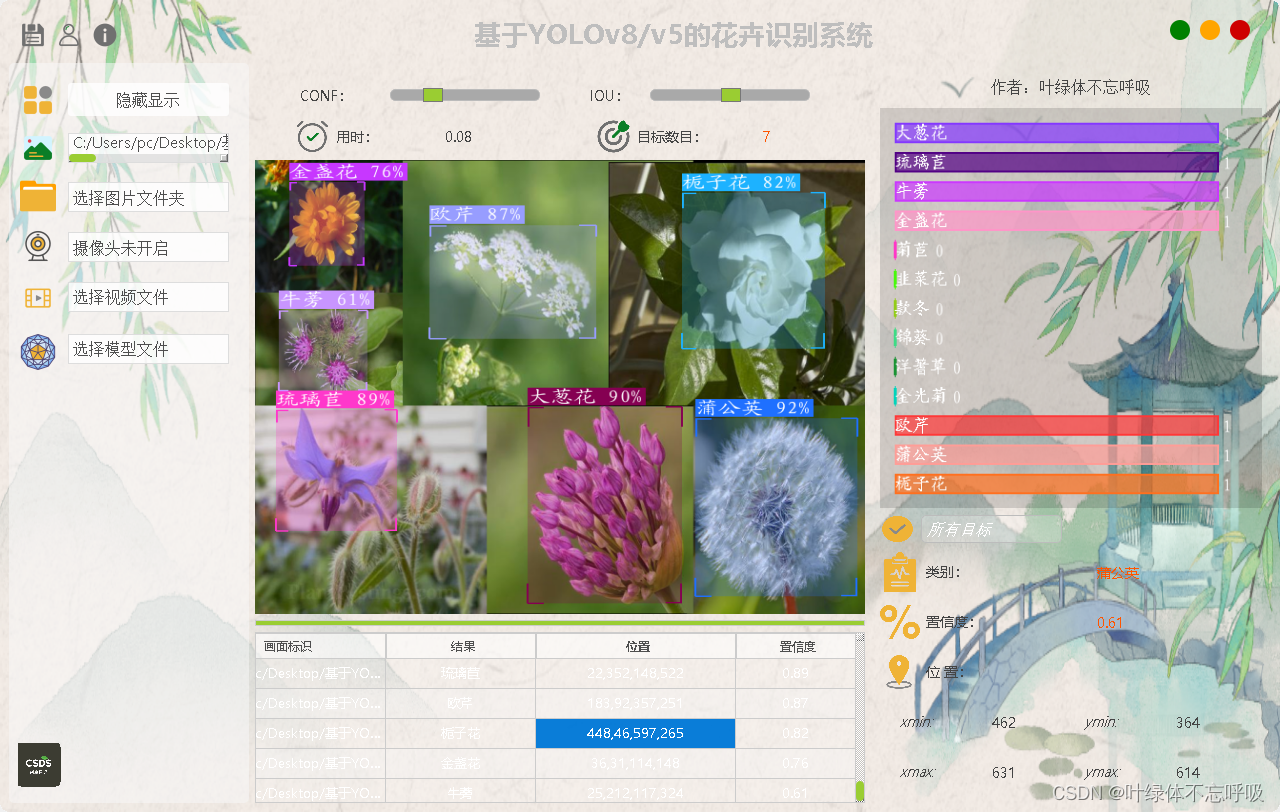
(1)本系统引入了SQLite数据库支持的注册与登录机制。新用户需在注册页面填写用户名和密码,系统随后将这些信息存储于SQLite数据库。注册完成后,用户便可通过输入用户名和密码在登录页面进行验证。这样的设计旨在提升系统安全,同时为未来拓展个性化服务提供了便利。(所有的背景图标均可个性化修改)
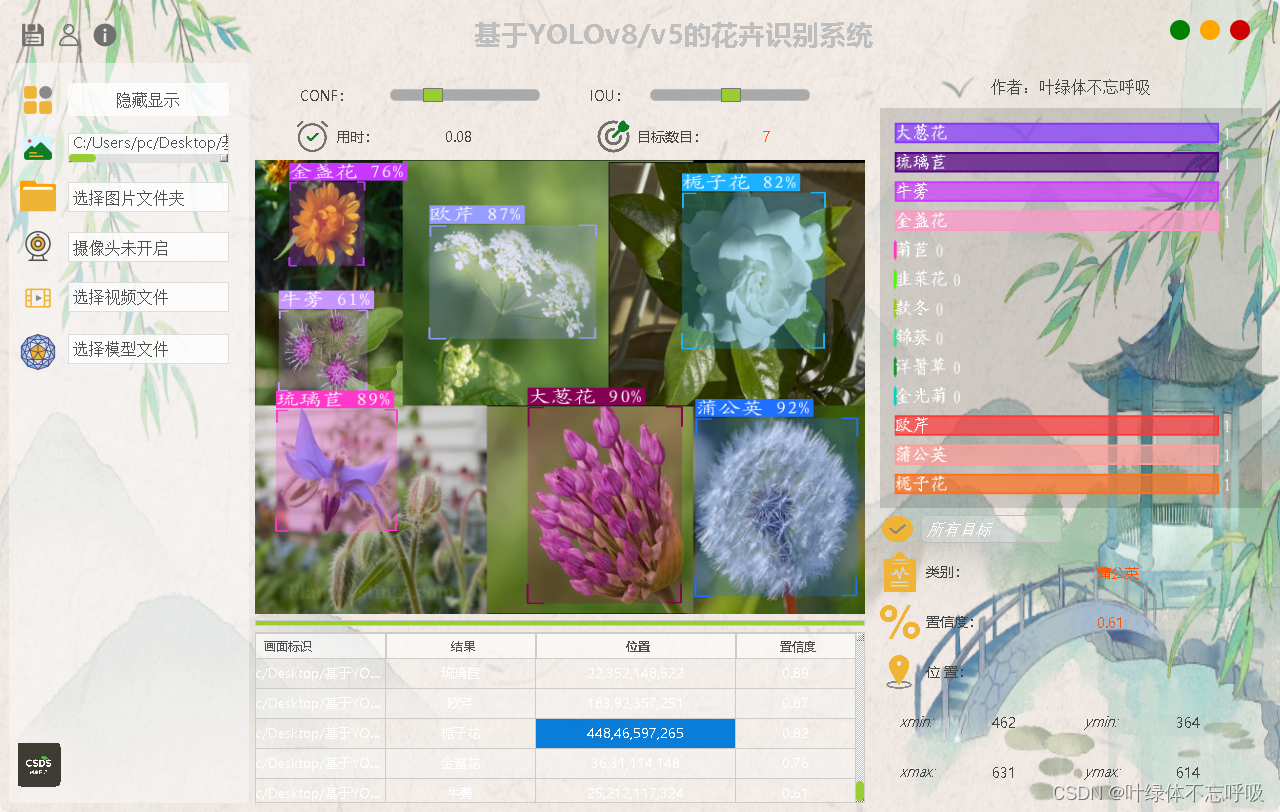
(2)系统主界面提供了多样化的输入选项,包括图片、视频、实时摄像头以及批量文件上传功能,用户可以轻松点击相应按钮,选取进行花卉识别的素材,或启动摄像头进行实时识别。与此同时,还可以设定置信度和IOU,保留符合要求的识别结果。在识别过程中,系统不仅实时展示识别结果(包含类别、位置、置信度等),还将所有识别记录自动存储于数据库中,方便后续查询和管理。
系统还提供了一键切换YOLOv8/v5模型的功能,用户可通过点击"更换模型"按钮,轻松选择不同的YOLOv8模型进行检测。同时,系统内置的数据集可用于重新训练模型,满足用户在多样化场景下的检测需求。
为了打造个性化的使用体验,系统还支持界面自定义。用户可以根据自己的喜好,自由调整界面的图标、文字等元素。无论是选择个性化的图标风格,还是修改界面的文字描述,用户都可以根据详细的代码注释和说明文档轻松实现,享受定制化的操作体验。

3、模型介绍
YOLOv5和YOLOv8是目标检测领域的两个重要算法,它们分别代表了YOLO系列的第五代和第八代产品。
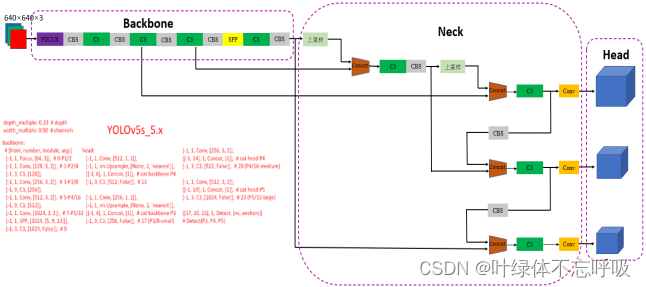
YOLOv5是由Glenn Jocher等人研发的,是Ultralytics公司的开源项目。YOLOv5根据参数量分为了n、s、m、l、x五种类型,参数量依次上升,效果也随之提升。从2020年6月发布至2022年11月已经更新了7个大版本,在v7版本中还添加了语义分割的功能。YOLOv5算法主要分为三个部分:Backbone网络、Neck网络和Head网络。其中,Backbone网络是整个算法的核心部分,通过多个卷积层和池化层对输入图像进行特征提取。Neck网络则负责对融合后的特征进行加强,使用SPP结构在不同尺度下应用池化操作。而Head网络则通过分类分支和回归分支两个部分来对融合后的特征进行分类和定位。
YOLOv8是Ultralytics公司在2023年1月10号开源的YOLOv5的下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务。YOLOv8是一个SOTA模型,它建立在以前YOLO版本的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性。具体创新包括一个新的骨干网络、一个新的Anchor-Free检测头和一个新的损失函数,可以在从CPU到GPU的各种硬件平台上运行。YOLOv8的开源库的两个主要优点是融合了众多当前SOTA技术于一体,未来将支持其他YOLO系列以及YOLO之外的更多算法。
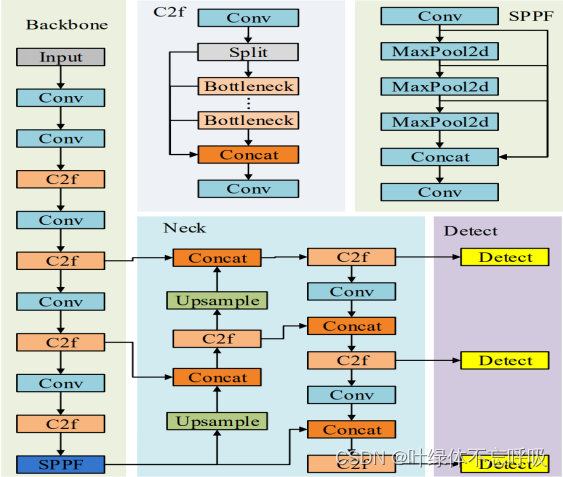
YOLOv8相比YOLOv5精度提升非常多,但是相应的参数量和FLOPs也增加了不少,从性能曲线也可以看出相比YOLOv5大部分模型推理速度变慢了。YOLOv8提供了一个全新的SOTA模型,包括P5 640和P6 1280分辨率的目标检测网络和基于YOLACT的实例分割模型。和YOLOv5一样,基于缩放系数也提供了N/S/M/L/X尺度的不同大小模型,用于满足不同场景需求。
总的来说,YOLOv5和YOLOv8都是目标检测领域的重要算法,YOLOv5以其优异的检测速度和精度平衡而广泛应用,而YOLOv8则在YOLOv5的基础上引入更多创新,性能进一步提升,是YOLO系列的最新成果。
(1)模型训练:运行run_train_model.py文件可以进行训练; 本项目中已经保存了训练 好的模型和训练结果,可以不用再次训练而直接使用。run_train_model.py文件如下。
python
import os
import torch
import yaml
from ultralytics import YOLO # 导入YOLO模型
from QtFusion.path import abs_path
device = "0" if torch.cuda.is_available() else "cpu"
if __name__ == '__main__': # 确保该模块被直接运行时才执行以下代码
workers = 1
batch = 8
data_name = "Flower"
data_path = abs_path(f'datasets/{data_name}/{data_name}.yaml', path_type='current') # 数据集的yaml的绝对路径
unix_style_path = data_path.replace(os.sep, '/')
# 获取目录路径
directory_path = os.path.dirname(unix_style_path)
# 读取YAML文件,保持原有顺序
with open(data_path, 'r') as file:
data = yaml.load(file, Loader=yaml.FullLoader)
# 修改path项
if 'path' in data:
data['path'] = directory_path
# 将修改后的数据写回YAML文件
with open(data_path, 'w') as file:
yaml.safe_dump(data, file, sort_keys=False)
model = YOLO(abs_path('./weights/yolov8n.pt'), task='detect') # 加载预训练的YOLOv8模型
results2 = model.train( # 开始训练模型
data=data_path, # 指定训练数据的配置文件路径
device=device, # 自动选择进行训练
workers=workers, # 指定使用2个工作进程加载数据
imgsz=640, # 指定输入图像的大小为640x640
epochs=150, # 指定训练150个epoch
batch=batch, # 指定每个批次的大小为8
name='train_v8_' + data_name # 指定训练任务的名称
)
model = YOLO(abs_path('./weights/yolov5nu.pt', path_type='current'), task='detect') # 加载预训练的YOLOv5模型
# model = YOLO('./weights/yolov5.yaml', task='detect').load('./weights/yolov5nu.pt') # 加载预训练的YOLOv5模型
# Training.
results = model.train( # 开始训练模型
data=data_path, # 指定训练数据的配置文件路径
device=device, # 自动选择进行训练
workers=workers, # 指定使用2个工作进程加载数据
imgsz=640, # 指定输入图像的大小为640x640
epochs=150, # 指定训练150个epoch
batch=batch, # 指定每个批次的大小为8
name='train_v5_' + data_name # 指定训练任务的名称
)
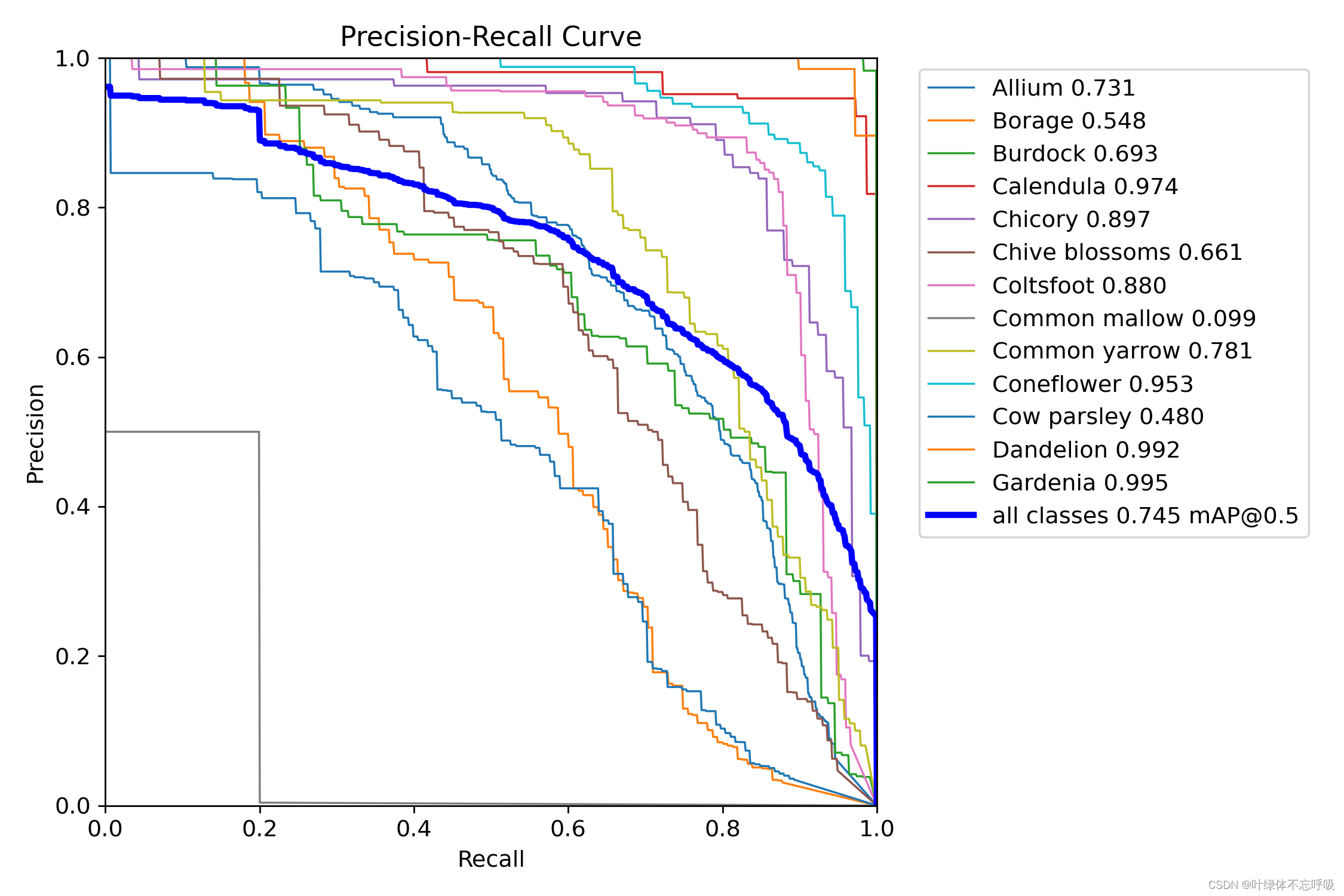
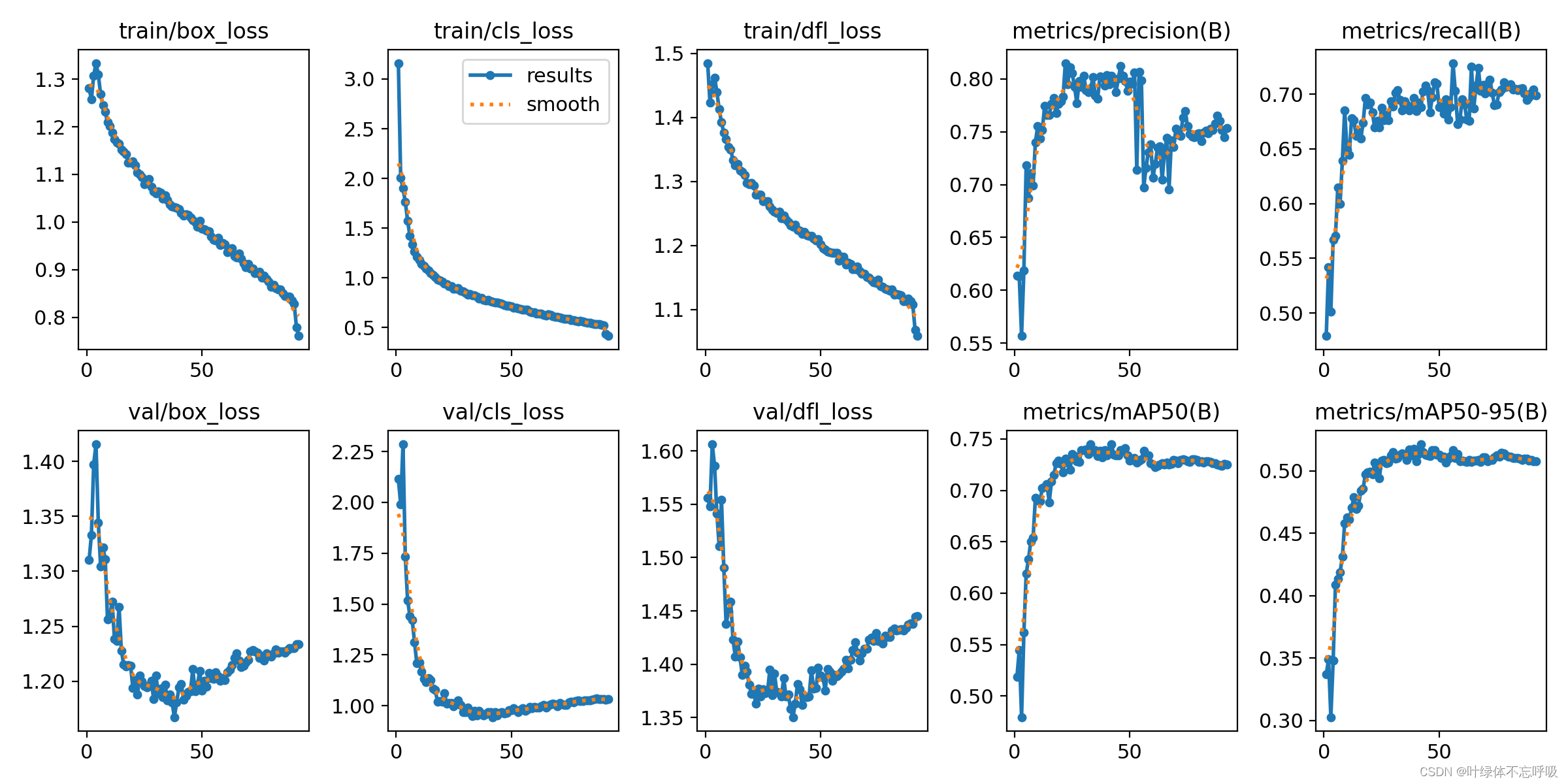
(2)模型指标:训练好的模型指标图表数据等均在run文件夹里面,可以根据需要使用,具体代表什么可以详见配套论文或网上查看。如下展示YOLOv8模型部分指标。
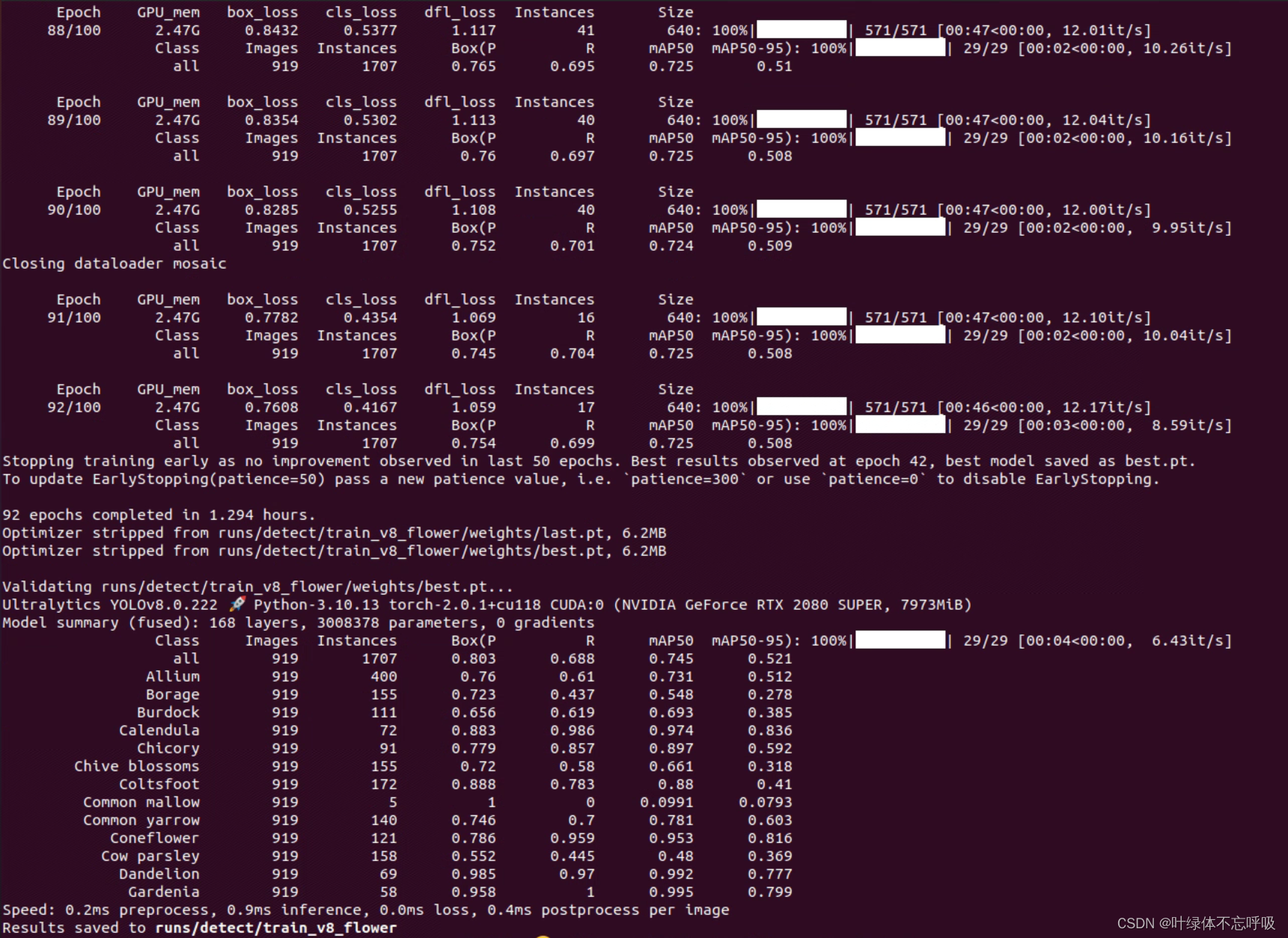
(3)模型推理识别:首先导入了OpenCV库和YOLO模型。OpenCV库是一个开源的计算机视觉和机器学习软件库,包含了众多的视觉处理函数,使用它来读取和处理图像;YOLO模型则是要用到的目标检测模型。 接着,加载自己训练好的YOLO模型,可以直接用于目标检测任务。然后,使用OpenCV读取了一个图像文件,这个图像文件作为要进行目标检测的图像输入。在读取了图像文件之后,就可以使用加载的模型对图像进行预测了。(这就是这个系统的核心)
三、项目环境配置


获取以上完整资料和服务详见博客文字开头第二段