数据来源:
python
https://www.cngold.org/img_date/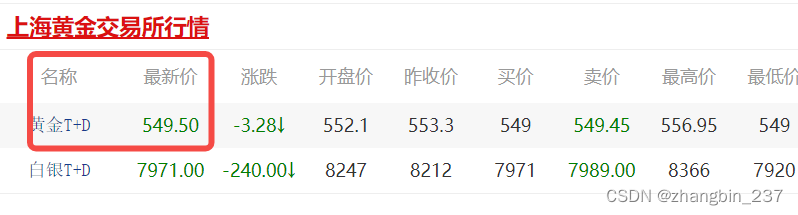
因为这个网站是数据随时变动的,用requests、BeautifulSoup的方式解析html的话,数据的位置显示的是"--",并不能取到数据。

所以采用webdriver访问网站,然后从界面上获取金价。
1、建表
在本地(服务器)上的mysql上建表,主要字段:sku、date_time、price,分别对应产品(也就是黄金)、时间、价格
2、读取金价函数
这个函数主要就是读取金价,并调用插入sql的函数:
python
def extract_info(url,id):
print('开始')
chrome_options = Options()
chrome_options.add_argument('--disable-infobars')
chrome_options.add_argument('--window-size=1920,1080') # 可以设置浏览器窗口大小
chrome_options.add_argument('--start-maximized') # 可以让浏览器窗口最大化
chrome_options.add_argument('--disable-extensions') # 禁用扩展
chrome_options.add_argument('--no-sandbox') # 以最高权限运行
chrome_options.add_argument('--disable-dev-shm-usage') # 用于解决Chrome crash问题
chrome_options.add_argument('--disable-browser-side-navigation') # 禁用浏览器端导航
chrome_options.add_argument('--enable-automation') # 允许自动化
chrome_options.add_argument("--headless") # 设置Chrome无头模式
print('过程1')
driver=webdriver.Chrome(options=chrome_options)
driver.get(url)
print('过程2')
driver.maximize_window()
#time.sleep(5)
text_list=driver.find_element(by=webdriver.common.by.By.XPATH,value='//html/body/div[3]/div/div[2]/div/div[3]/table/tbody/tr/td[2]/font')
price_hour=text_list.text
sql = 'insert into reptile.gold_price_log values("' + str(id) + '","' + datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S') + '",' + str(price_hour) + ');'
print(sql)
sql_insert(sql, id)数据插入函数:
python
def sql_insert(sql,id):
sql=sqlalchemy.text(sql)
print(sql_getcnt(id))
if sql_getcnt(id) == 0:
try:
con.execute(sql)
con.commit()
except:
print('执行失败')
print(sql)3、数据验证函数
因为爬取数据的目标是每个小时记录一次,为了避免测试、调试的数据干扰,做一个验证的方法,如果这个小时已经有数据了,就不再运行上个函数了:
python
def sql_getcnt(id):
g_sql = '''
select
count(*) as cnt
from reptile.gold_price_log
where sku="黄金"
and date_format(date_time,'%Y-%m-%d %H:00:00')="''' + datetime.datetime.now().strftime('%Y-%m-%d %H:00:00') + '''"
order by sku desc
,date_time desc
'''
g_sql = sqlalchemy.text(g_sql)
data = pd.read_sql_query(sql=g_sql, con=con, index_col=['cnt'])
cnt = list(data.index)[0]
#print(cnt)
return cnt4、主方法
python
url_list=['https://www.cngold.org/img_date/']
sku_list=['黄金']
for i in range(len(sku_list)):
print(sql_getcnt(sku_list[i]))
if sql_getcnt(sku_list[i])>100:
time.sleep(random.uniform(1, 5))
print(str(sku_list[i])+'已存在')
else:
url_id=url_list[i]
extract_info(url_id,sku_list[i])有些写法是之前脚本复制过来的,所以偶尔会有些奇怪哈哈哈。
5、配置每小时调用
因为这个脚本是设置在了云服务器上,所以要在linux服务器上设置定时执行,我这边的逻辑是shell脚本调用python脚本,然后定时执行shell脚本。
shell脚本内容:
然后:
bash
crontab -e
这样,就可以每小时记录金价了。