目录
本篇文章主要讲解使用YOLOx训练自己数据集,其中包括数据集格式转换~
目录
一、数据集处理
第一步:将yolo格式的数据集转换成VOC格式
转换脚本:txt_to_xml.py
python
from xml.dom.minidom import Document
import os
import cv2
# def makexml(txtPath, xmlPath, picPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
def makexml(picPath, txtPath, xmlPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
在自己的标注图片文件夹下建三个子文件夹,分别命名为picture、txt、xml
"""
dic = {'0': "youlun", # 创建字典用来对类型进行转换
'1': "youting",
'2': "zhou",
'3': "fengfan",# 此处的字典要与自己的classes.txt文件中的类对应,且顺序要一致
}
files = os.listdir(txtPath)
for i, name in enumerate(files):
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile = open(txtPath + name)
txtList = txtFile.readlines()
img = cv2.imread(picPath + name[0:-4] + ".jpg")
Pheight, Pwidth, Pdepth = img.shape
folder = xmlBuilder.createElement("folder") # folder标签
foldercontent = xmlBuilder.createTextNode("driving_annotation_dataset")
folder.appendChild(foldercontent)
annotation.appendChild(folder) # folder标签结束
filename = xmlBuilder.createElement("filename") # filename标签
filenamecontent = xmlBuilder.createTextNode(name[0:-4] + ".jpg")
filename.appendChild(filenamecontent)
annotation.appendChild(filename) # filename标签结束
size = xmlBuilder.createElement("size") # size标签
width = xmlBuilder.createElement("width") # size子标签width
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width) # size子标签width结束
height = xmlBuilder.createElement("height") # size子标签height
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height) # size子标签height结束
depth = xmlBuilder.createElement("depth") # size子标签depth
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth) # size子标签depth结束
annotation.appendChild(size) # size标签结束
for j in txtList:
oneline = j.strip().split(" ")
object = xmlBuilder.createElement("object") # object 标签
picname = xmlBuilder.createElement("name") # name标签
namecontent = xmlBuilder.createTextNode(dic[oneline[0]])
picname.appendChild(namecontent)
object.appendChild(picname) # name标签结束
pose = xmlBuilder.createElement("pose") # pose标签
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose) # pose标签结束
truncated = xmlBuilder.createElement("truncated") # truncated标签
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated) # truncated标签结束
difficult = xmlBuilder.createElement("difficult") # difficult标签
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult) # difficult标签结束
bndbox = xmlBuilder.createElement("bndbox") # bndbox标签
xmin = xmlBuilder.createElement("xmin") # xmin标签
mathData = int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin) # xmin标签结束
ymin = xmlBuilder.createElement("ymin") # ymin标签
mathData = int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin) # ymin标签结束
xmax = xmlBuilder.createElement("xmax") # xmax标签
mathData = int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax) # xmax标签结束
ymax = xmlBuilder.createElement("ymax") # ymax标签
mathData = int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax) # ymax标签结束
object.appendChild(bndbox) # bndbox标签结束
annotation.appendChild(object) # object标签结束
f = open(xmlPath + name[0:-4] + ".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
if __name__ == "__main__":
picPath = "F:/project/liuxin/chuan_nc4/chuan_nc4/images/val/" # 图片所在文件夹路径,后面的/一定要带上
txtPath = "F:/project/liuxin/chuan_nc4/chuan_nc4/labels/val/" # txt所在文件夹路径,后面的/一定要带上
xmlPath = "F:/project/liuxin/chuan_nc4/chuan_nc4/xml/val/" # xml文件保存路径,后面的/一定要带上
makexml(picPath, txtPath, xmlPath)第二步:更改xml文件中属性值
用这个代码可以任意改变xml里的属性值,比如你想把xml文件中类别名称改变,参考以下代码:
python
# 这里只修改folder部分
import os
import os.path
import xml.dom.minidom
path = "F:/project/liuxin/chuan_nc4/chuan_nc4/xml/"
files = os.listdir(path) # 得到文件夹下所有文件名称
for xmlFile in files: # 遍历文件夹
if not os.path.isdir(xmlFile): # 判断是否是文件夹,不是文件夹才打开
print(xmlFile)
# 将获取的xml文件名送入到dom解析
dom = xml.dom.minidom.parse(os.path.join(path, xmlFile)) # 输入xml文件具体路径
root = dom.documentElement
# 获取标签<name>以及<folder>的值
name = root.getElementsByTagName('name')
folder = root.getElementsByTagName('folder')
# 对每个xml文件的多个同样的属性值进行修改。此处将每一个<folder>属性修改为VOC2007
for i in range(len(folder)):
print(folder[i].firstChild.data)
folder[i].firstChild.data = 'VOC2007'
print(folder[i].firstChild.data)
# 将属性存储至xml文件中
with open(os.path.join(path, xmlFile), 'w') as fh:
dom.writexml(fh)
print('已写入')这里修改folder部分,效果如下:

第三步:自己制作trainval.txt,里面存储自己的待训练图片名称,记住不要带.jpg后缀,代码如下:
python
# !/usr/bin/python
# -*- coding: utf-8 -*-
import os
import random
trainval_percent = 0.8 #trainval占比例多少
train_percent = 0.7 #test数据集占比例多少
xmlfilepath = '/root/faster-rcnn/data/VOCdevkit2007/VOC2007/Annotations/'
txtsavepath = '/root/faster-rcnn/data/VOCdevkit2007/VOC2007/ImageSets/Main/'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('/root/faster-rcnn/data/VOCdevkit2007/VOC2007/ImageSets/Main/trainval.txt', 'w')
ftest = open('/root/faster-rcnn/data/VOCdevkit2007/VOC2007/ImageSets/Main/test.txt', 'w')
ftrain = open('/root/faster-rcnn/data/VOCdevkit2007/VOC2007/ImageSets/Main/train.txt', 'w')
fval = open('/root/faster-rcnn/data/VOCdevkit2007/VOC2007/ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close() 第四步:将处理好的数据按照以下文件夹命名格式上传
python
VOCdevkit2007
└── VOC2007
├── Annotations
├── ImageSets
│ └── Main
│ ├── test.txt
│ ├── train.txt
│ ├── trainval.txt
│ └── val.txt
└── JPEGImages二、环境配置
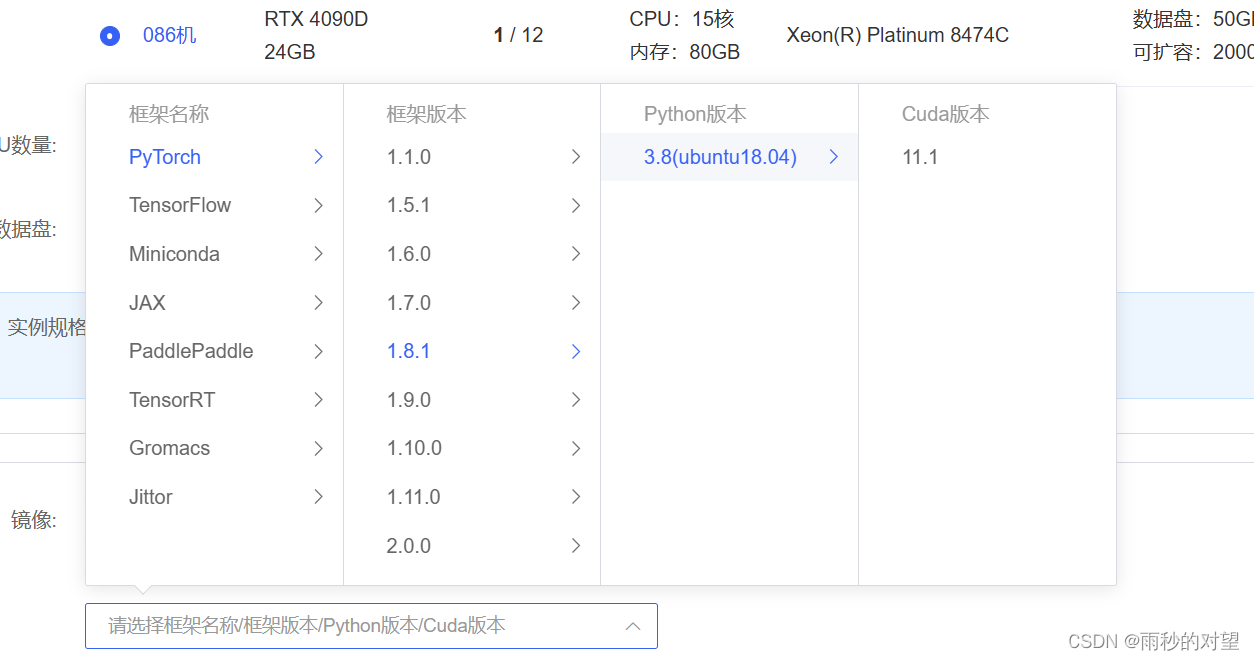
第一步:配置基础镜像
第二步:安装依赖
python
git clone git@github.com:Megvii-BaseDetection/YOLOX.git
cd YOLOX
pip3 install -U pip && pip3 install -r requirements.txt
pip3 install -v -e . # or python3 setup.py develop(1)apex安装
python
git clone https://github.com/NVIDIA/apex
cd apex
# RTX3090 ,CUDA11.1安装的时候需要将 apex/setup.py中的
def check_cuda_torch_binary_vs_bare_metal(cuda_dir):
return # 也就是这里直接进行返回,不进行下面的操作,否则无法安装成。
pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./(2)安装pycocotools
python
pip3 install cython;
pip3 install 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'报错:

解决:将第二行输入指令换成以下内容
python
pip install "git+https://gitee.com/wsyin/cocoapi.git#subdirectory=PythonAPI"三、配置文件修改
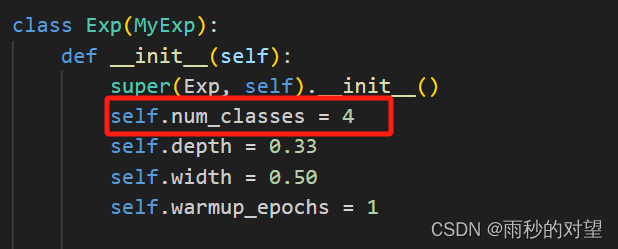
1、YOLOX/exps/example/yolox_voc/yolox_voc_s.py
a)类别
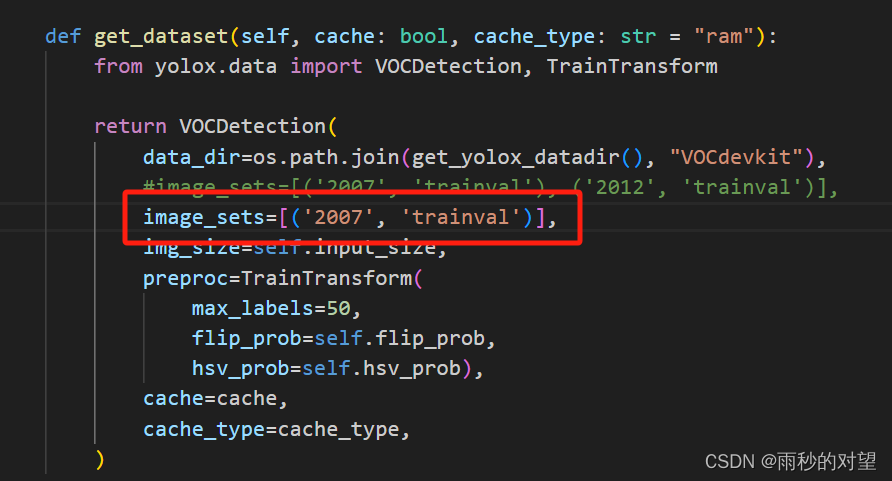
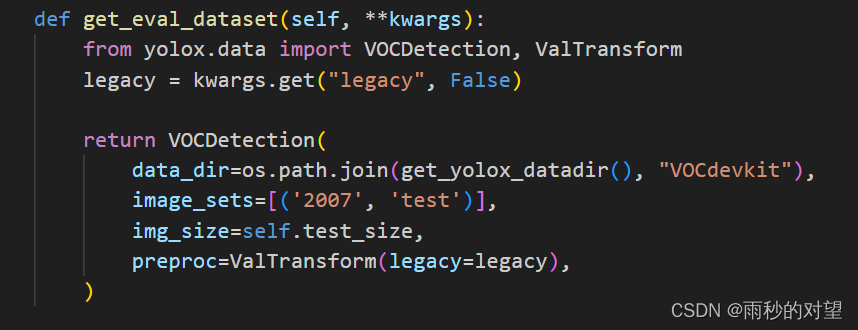
b)image_sets
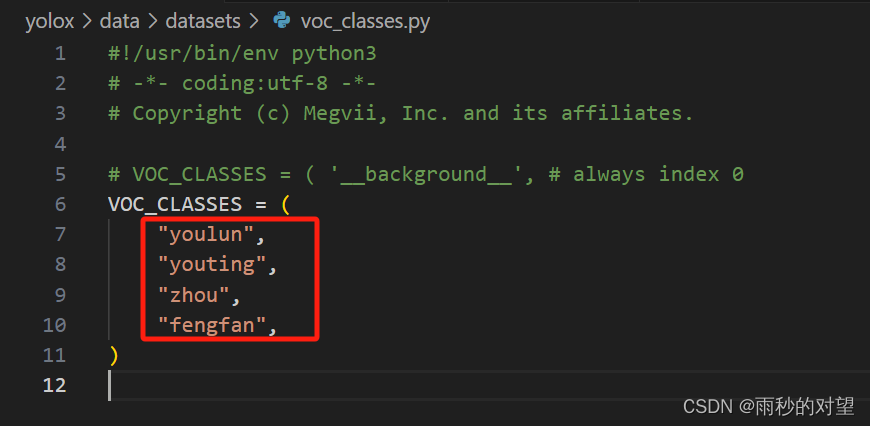
2、YOLOX/yolox/data/datasets/voc_classes.py
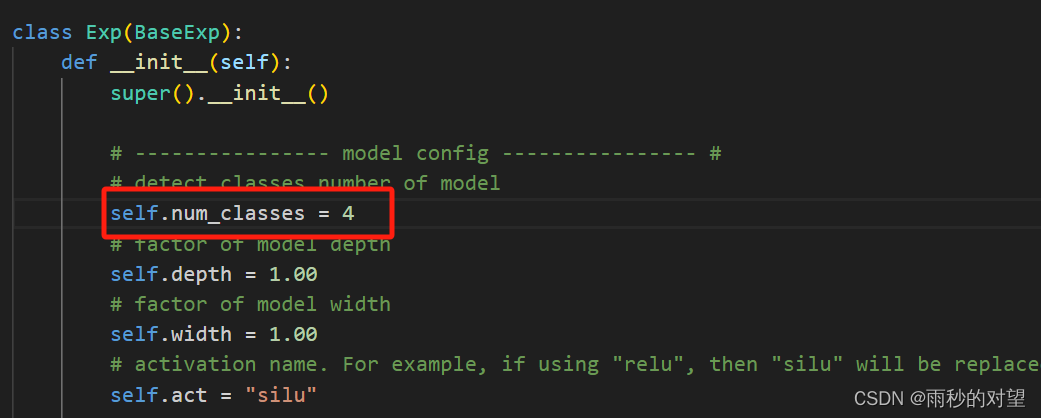
3、YOLOX/yolox/exp/yolox_base.py
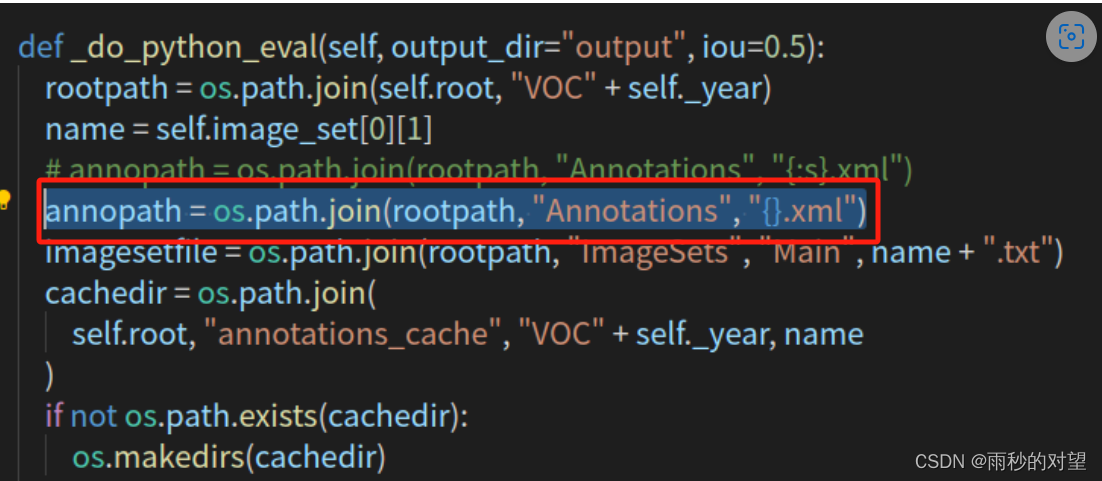
4、修改YOLOX/yolox/data/datasets/voc.py 文件下的_do_python_eval 函数
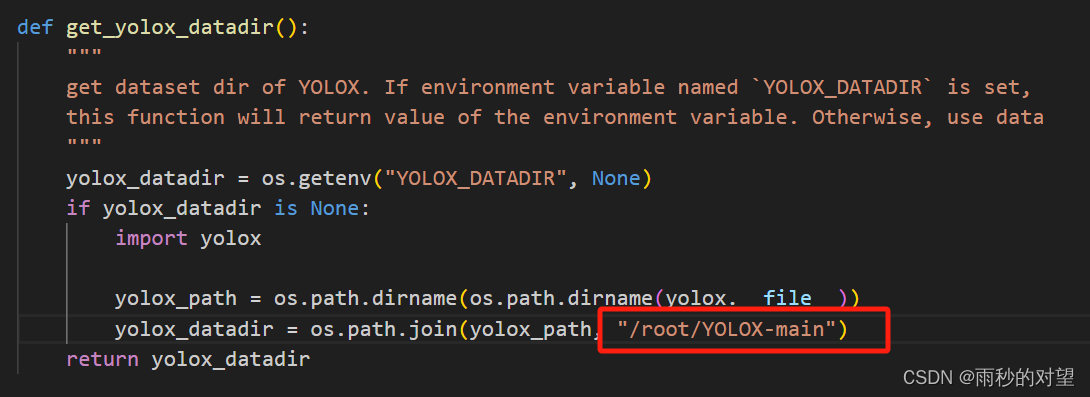
5、yolox/data/dataloading.py-自己的路径
6、/yolox/data/datasets/voc.py
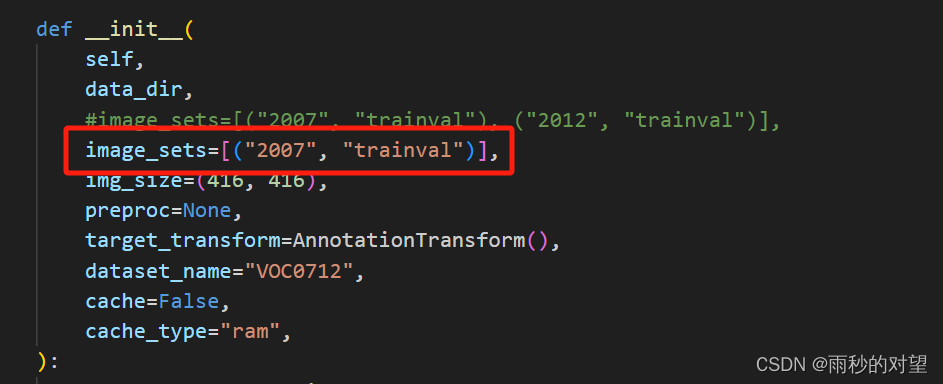
7、在YOLOX/yolox/exp/yolox_base.py 文件中配置相关训练参数
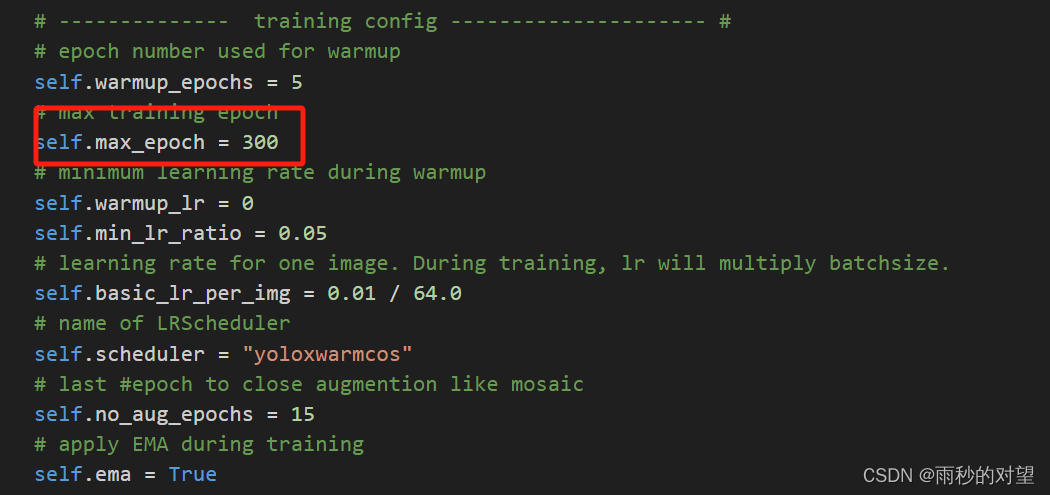
四、开始训练
训练指令:
python
python tools/train.py -f exps/example/yolox_voc/yolox_voc_s.py -d 0 -b 8 --fp16 -o -c ./yolox_x.pth 报错:
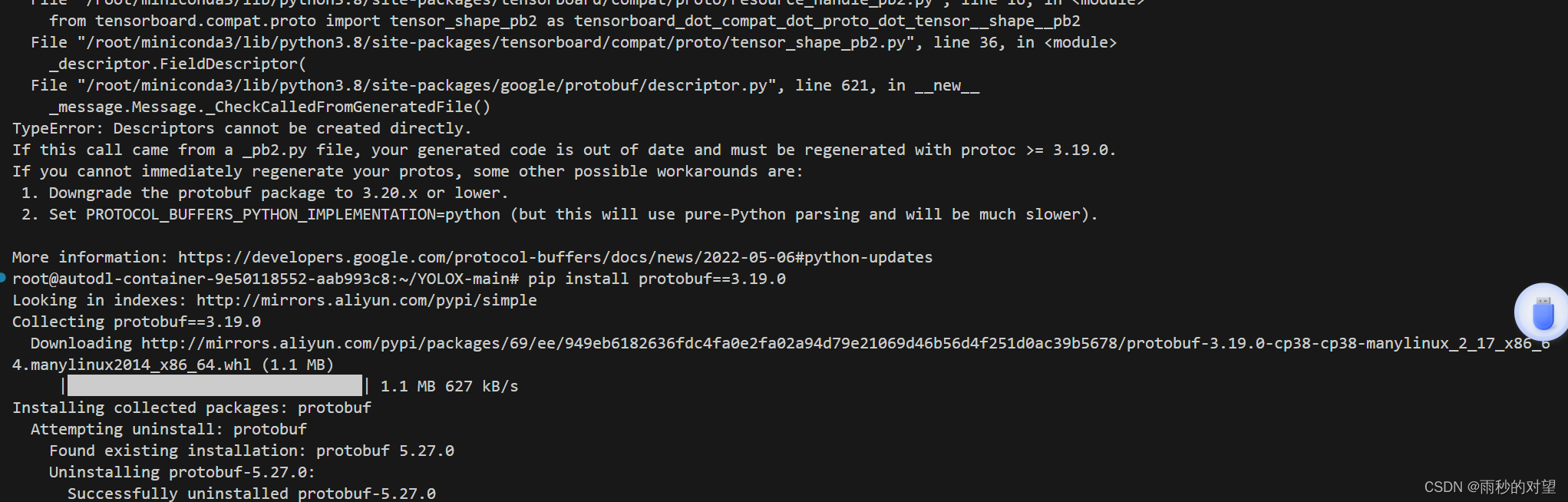
解决:
python
pip install protobuf==3.19.0运行成功,效果如下!
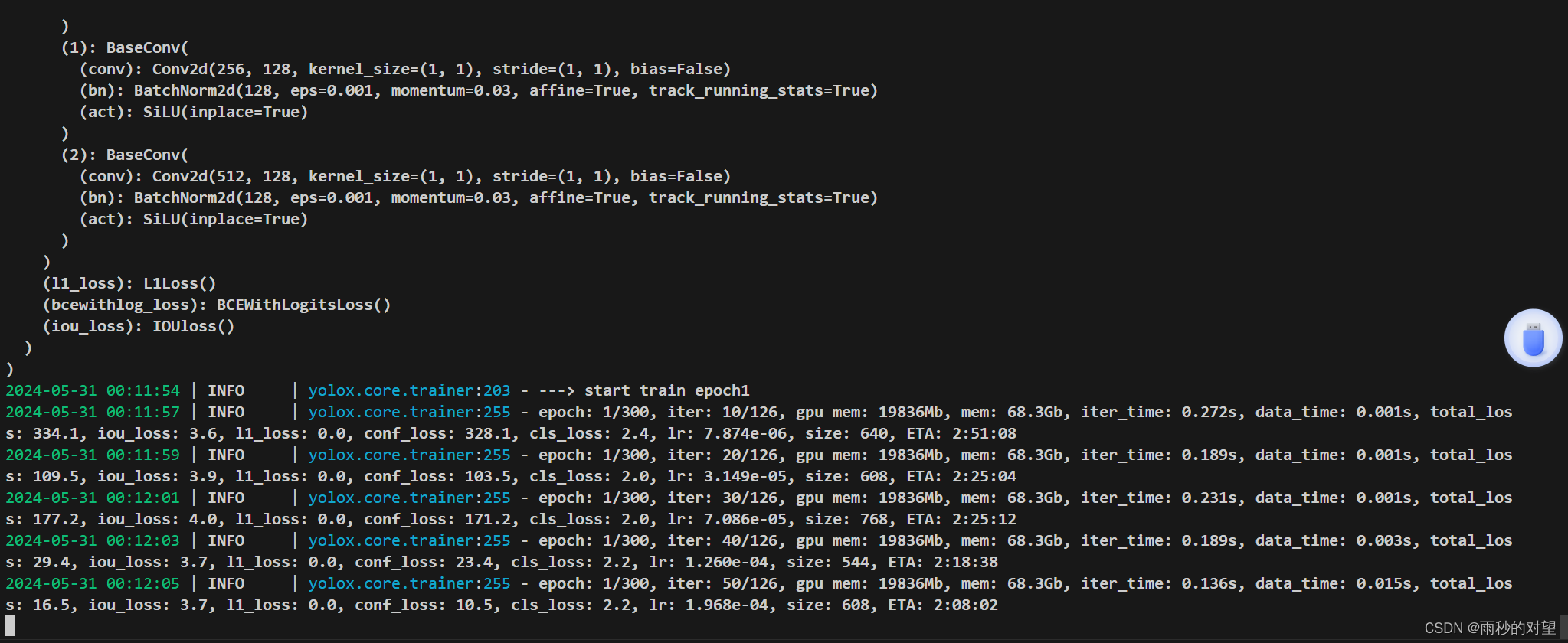
五、开始验证
python
python -m yolox.tools.eval -f exps/example/yolox_voc/yolox_voc_s.py -c YOLOX_outputs/yolox_voc_s/best_ckpt.pth -b 64 -d 0 --conf 0.001 [--fp16] [--fuse]结果如下:
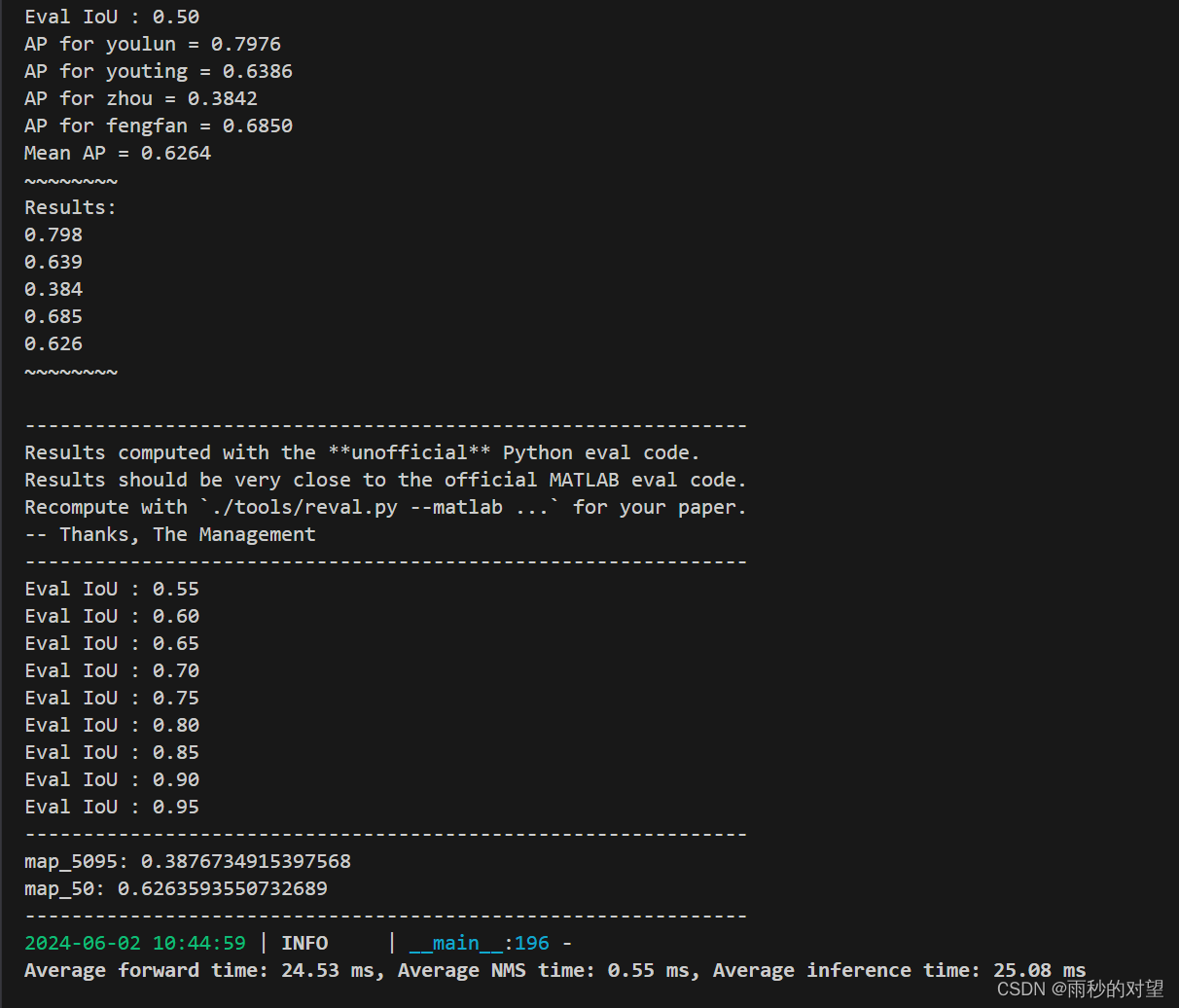
完结撒花!