我们上一节课写的tcp我们发现只有第一个与之连接的人才能收发信息。他又很多的不足
高性能网络服务器
- 通过fork实现高性能网络服务器
我们通过fork进行改装之后就可以成百上千的用户进行连接访问,对于每一个用户来说我们都fork一个子进程。让后让每一个子进程都是与服务器端的一个对应关系。这样并行的进行处理。但是还是有很多的不足之处。 - 通过select实现高性能网络服务器
通过IO复用的方式来实现多个客户端与服务器端进行通信。 - 通过epoll实现高性能网络服务器
也是通过IO复用的方式来实现多个客户端与服务器端进行通信,但是他比select更加高效。它通过底层内核级事件,更高校 - 利用I/O事件处理库来实现高性能网络服务器
以fork方式实现高性能网络服务器
创建子进程函数--fork( )
要了解线程我们先来了解fork()函数:fork() 函数的功能是在当前的进程创建一个子进程;
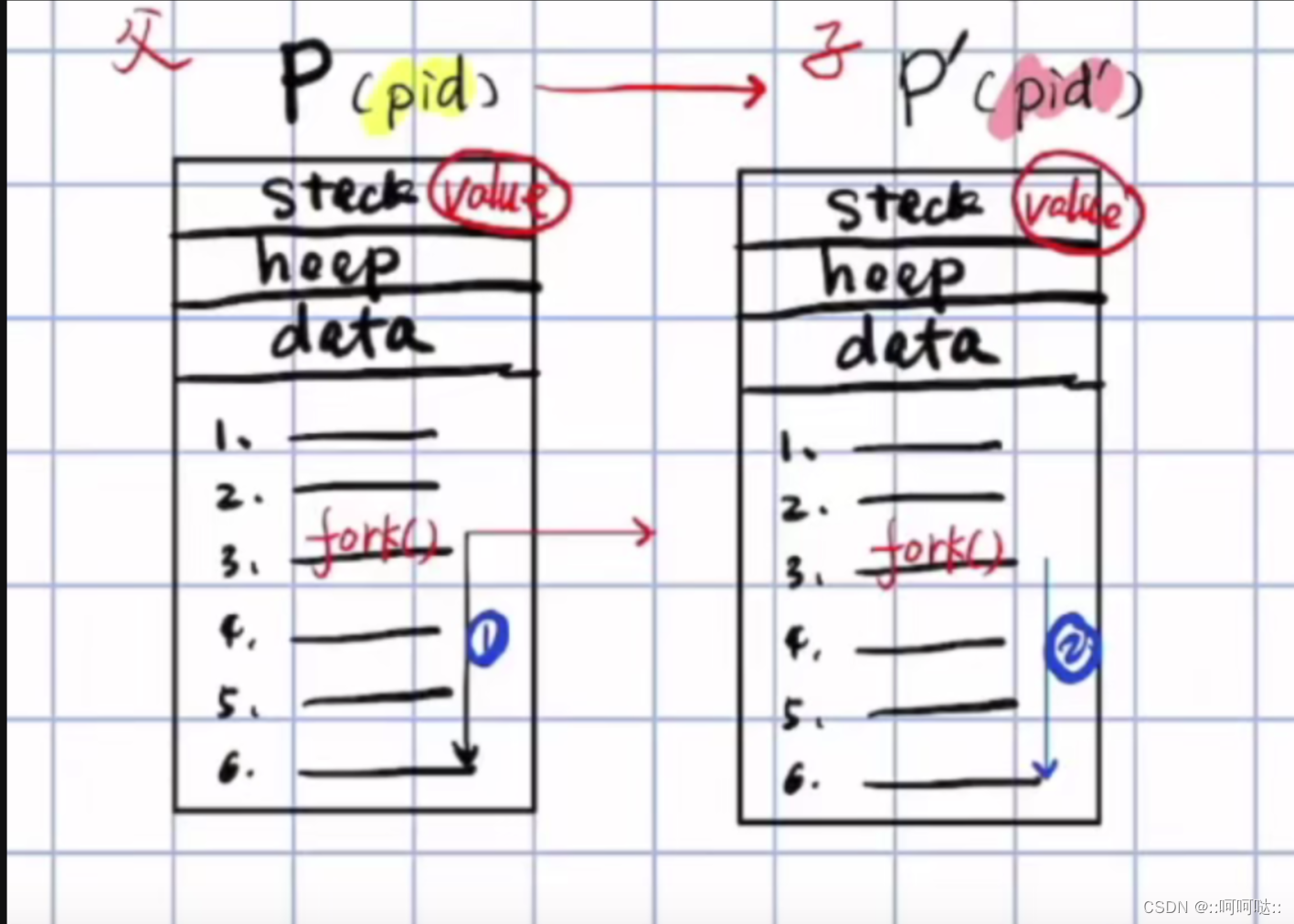
执行fork函数,会在内存中创建一份和父进程完全一样的子进程出来;
该子进程和父进程是两个完全独立的空间;用进程编号pid来区分父子进程;
父进程fork()之后的代码会被并发的执行两遍,是因为子进程和父进程在交替执行fork()之后代码的原因;fork()函数返回0表示为执行子进程的代码,返回pid编号表示执行父进程,返回-1表示创建子进程失败
fork的执行机制
那fork()函数的执行机制是什么?
- 执行fork函数,会在内存中创建一份和父进程完全一样的子进程出来;
- 该子进程和父进程是两个完全独立的空间;用进程编号pid来区分父子进程;
- 父进程fork()之后的代码会被并发的执行两遍,是因为子进程和父进程在交替执行fork()之后代码的原因;
- fork()函数返回0表示为执行子进程的代码,返回pid编号表示执行父进程,返回-1表示创建子进程失败
下图是父子进程的大概内存布局:有编号那些是进程的代码段
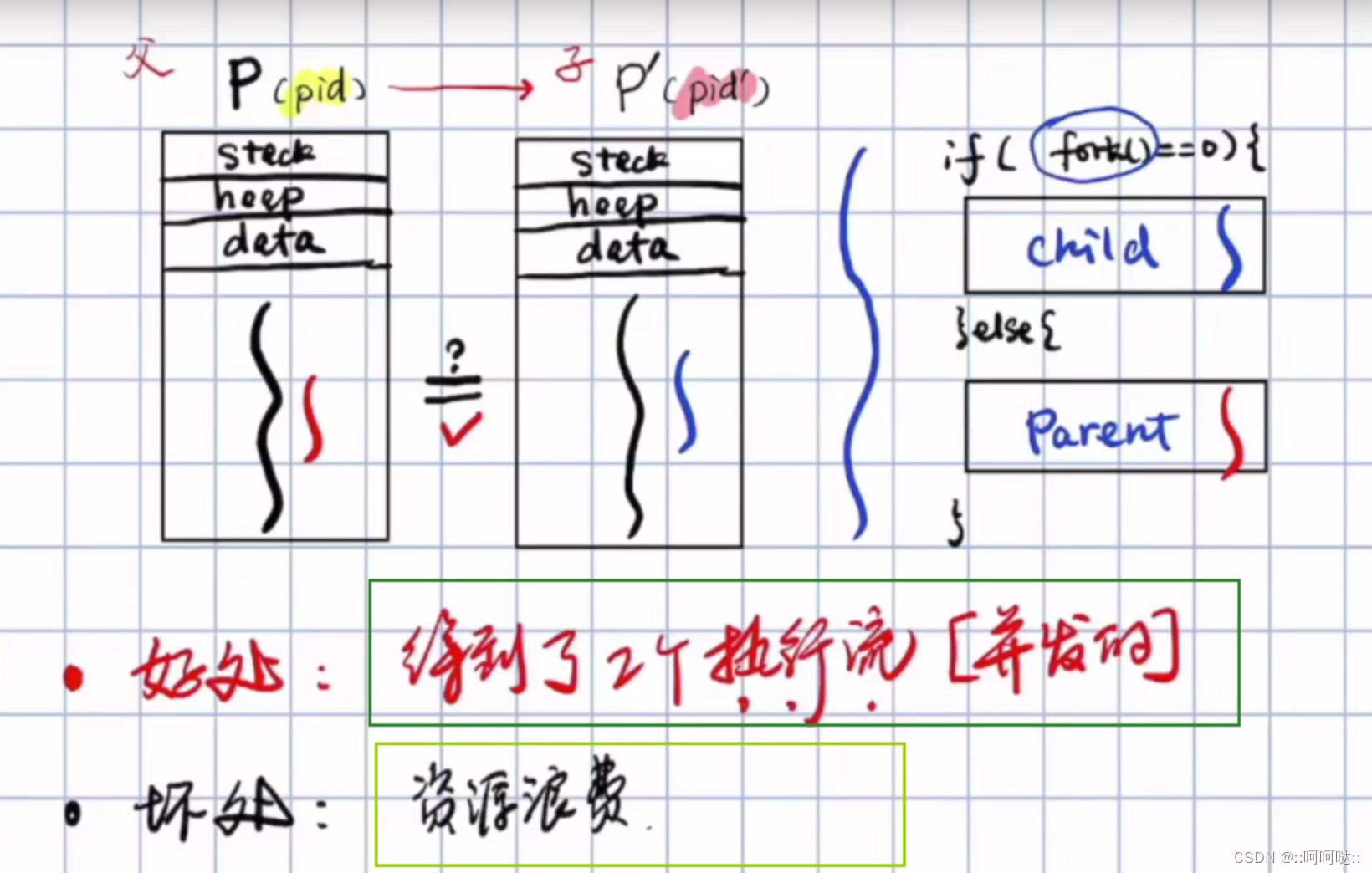
对于fork()出来的子进程:我们是好处和坏处的;
好处 :同一段代码,可以有两个不同的执行流,也就是说可以同一段代码可以完成两个不同的事情;
坏处 :资源浪费:创建一份完全一样的子进程出来,又要复制一份父进程的代码到内存中,很浪费资源!其实很没必要!
线程的理解
线程之所以出现:也是进程的浪费资源问题相应而出的。
我们最初的想法是,能不能在不创建子进程的同时,也可以有同一份代码,却又有多个执行流!即一份代码可以做不同的事,并且不用创建子进程!
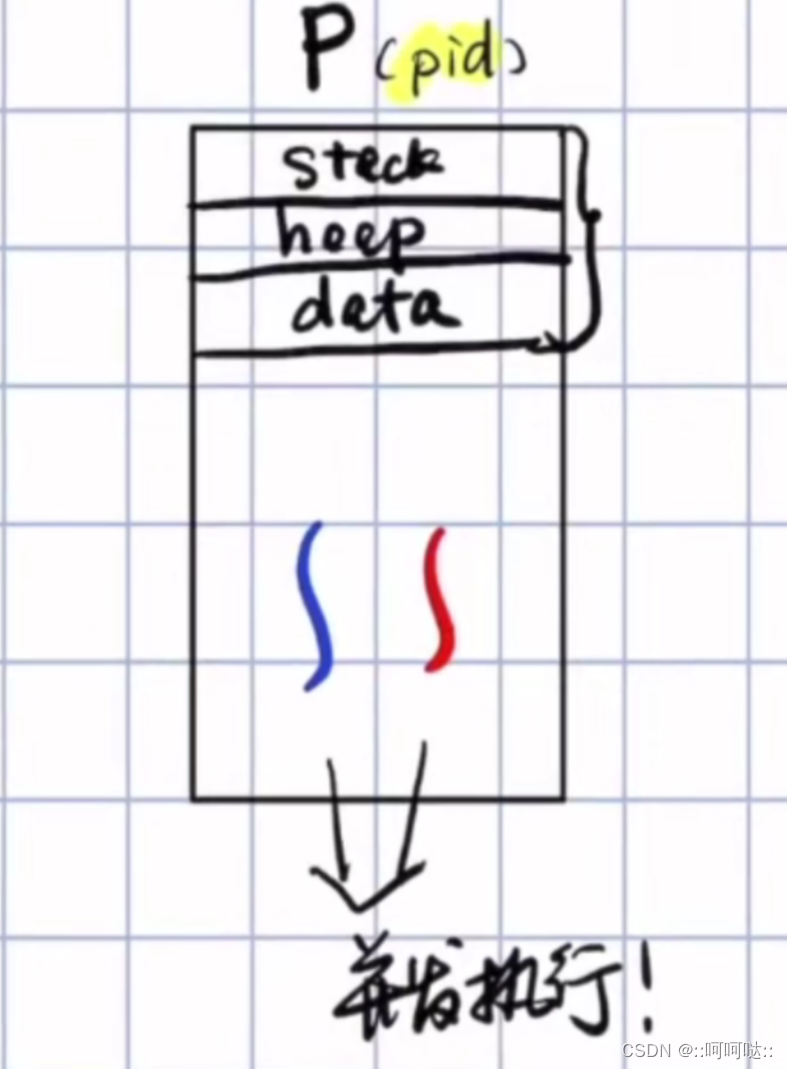
有了线程:那么cpu的调度单位就不再是进程了,而是进程的执行流,也就是线程,因为它们是并发执行的,我们成为并发的线程
具体可以看这个链接
fork的API
一个主进程进行监听连接。每收到一个连接就创一个子进程 ,多个子进程进行并行连接。然后父进程负责接收连接,通过fork创建子进程。
头文件
#include <sys/types.h>
#include <unistd.h>原型
pid_t fork(void);fork()是一个系统调用函数,用于在 Unix-like 操作系统中创建一个新的进程。它会复制当前进程(称为父进程),并在新的进程(称为子进程)中继续执行。
fork()函数返回的是一个 pid_t 类型的值,pid是进程id,如果pid==0,说明是子进程,如果大于0就是父进程。其含义如下:
- 在父进程中,fork() 返回新创建的子进程的进程 ID(PID)。
- 在子进程中,fork() 返回 0。
- 如果创建子进程失败,fork() 返回 -1。
fork() 函数在创建子进程时会返回两次,这是因为它是一个复制当前进程的系统调用。具体来说,fork() 函数会创建一个新的进程(子进程),并将父进程的所有内容(包括代码、数据、堆栈等)复制到子进程中。
第一次返回:
- 在父进程中,fork() 返回新创建的子进程的进程 ID(PID)。
- 如果创建子进程失败,fork() 返回 -1。
第二次返回:
- 在子进程中,fork() 返回 0。
- 通过这两次返回,父进程和子进程可以根据不同的返回值采取不同的逻辑分支。
在父进程中,可以根据返回的子进程 PID 做一些与子进程相关的操作,如记录子进程的 PID、等待子进程的终止等。
在子进程中,由于 fork() 返回的是 0,可以根据此特性来区分自己是子进程,从而执行特定的子进程代码逻辑。
需要注意的是,父进程和子进程会继续执行 fork() 调用之后的代码,并且它们是在不同的进程上下文中运行的,拥有各自独立的内存空间和资源。因此,在使用 fork() 创建子进程时,通常需要在父子进程中进行不同的处理,以避免竞态条件和不必要的资源共享问题。
fork的代码
这个代码还是在服务器端,接收客户端的时候fork一个子线程。然后进行通信。
tcp_server_fork.cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <iostream>
//端口
#define PORT 8888
#define MESSAGE_LEN 1024
int main(int argc,char* argv[]){
int ret=-1;
int on=1;
int backlog=10;//缓冲区大小
int socket_fd,accept_fd;
pid_t pid;
struct sockaddr_in localaddr,remoteaddr;
char in_buff[MESSAGE_LEN]={0,};
socket_fd=socket(AF_INET,SOCK_STREAM,0);
if(socket_fd==-1){
std::cout<<"Failed to create socket!"<<std::endl;
exit(-1);
}
ret=setsockopt(socket_fd,SOL_SOCKET,SO_REUSEADDR,&on,sizeof(on));
if(ret==-1){
std::cout<<"Failed to set socket options!"<<std::endl;
}
localaddr.sin_family=AF_INET;//地址族
localaddr.sin_port=htons(PORT);//端口号
localaddr.sin_addr.s_addr=INADDR_ANY;//这个就是0
bzero(&(localaddr.sin_zero), 8);
ret= bind(socket_fd,(struct sockaddr *)&localaddr,sizeof(struct sockaddr));//绑定
if(ret==-1){//绑定失败
std::cout<<"Failed to bind addr!"<<std::endl;
exit(-1);
}
ret = listen(socket_fd,backlog);//第二个是缓冲区大小,因为同一时间只能处理一个,其他都放在缓冲区
if(ret==-1){
std::cout<<"failed to listen socket!"<<std::endl;
exit(-1);
}
while(1){//等待连接
socklen_t addr_len=sizeof(struct sockaddr);
accept_fd = accept(socket_fd,
(struct sockaddr *)&remoteaddr,
&addr_len);
//每次接收之后我们fork一个子进程。pid是进程id,如果pid==0,说明是子进程,如果大于0就是父进程
pid = fork();
if(pid == 0){
//连接了
while(1){//这个是连接了之后,发消息
memset(in_buff, 0, sizeof(in_buff));
//接收消息
ret = recv(accept_fd,(void *)in_buff,MESSAGE_LEN,0);
if(ret==0){
break;
}
std::cout<<"recv:"<<in_buff<<std::endl;
//返回消息
send(accept_fd,(void*)in_buff,MESSAGE_LEN,0);
}
}
close(accept_fd);
}
if(pid!=0){
close(socket_fd);
}
return 0;
}clang++ -g -o tcp_server_fork tcp_server_fork.cpp
./tcp_server_fork
客户端还是上个文章的客户端。
fork()的优缺点
使用 fork() 函数创建子进程的服务器有以下优点和缺点:
优点:
简单易用:使用 fork() 函数创建子进程的服务器相对简单,不需要使用复杂的多线程或多进程编程模型。通过复制父进程的内存空间,子进程可以独立运行,处理客户端请求。
高并发处理:每个客户端连接都可以创建一个独立的子进程,这样服务器能够同时处理多个客户端请求,实现高并发性能。
数据共享:父进程和子进程共享文件描述符,可以轻松共享一些资源和状态信息,例如打开的文件、缓冲区等。
可靠性:由于每个子进程是独立运行的,一个子进程的崩溃或异常不会影响其他子进程或主服务器进程。
缺点:
内存开销:每个子进程都需要复制父进程的内存空间,因此在大规模并发的情况下,服务器的内存开销会比较大。
进程切换开销:由于每个客户端连接都需要创建子进程,因此涉及到进程之间的切换开销,包括上下文切换和进程间通信开销,这可能对服务器性能产生一定的影响。
可伸缩性:由于每个客户端连接都需要创建子进程,服务器的可伸缩性可能受到限制。在大规模并发情况下,为每个连接创建子进程可能会导致系统资源耗尽。
进程间通信复杂性:如果子进程之间需要进行通信或共享数据,就需要使用进程间通信(IPC)机制,如管道、共享内存等。这增加了编程的复杂性。
综上所述,使用 fork() 函数创建子进程的服务器适用于简单的并发场景和较小规模的应用,但在大规模高并发、资源消耗较大或需要更高可伸缩性的情况下,可能需要考虑其他并发模型,如多线程或事件驱动模型。
参考:https://blog.csdn.net/lepaitianshi/article/details/132981657