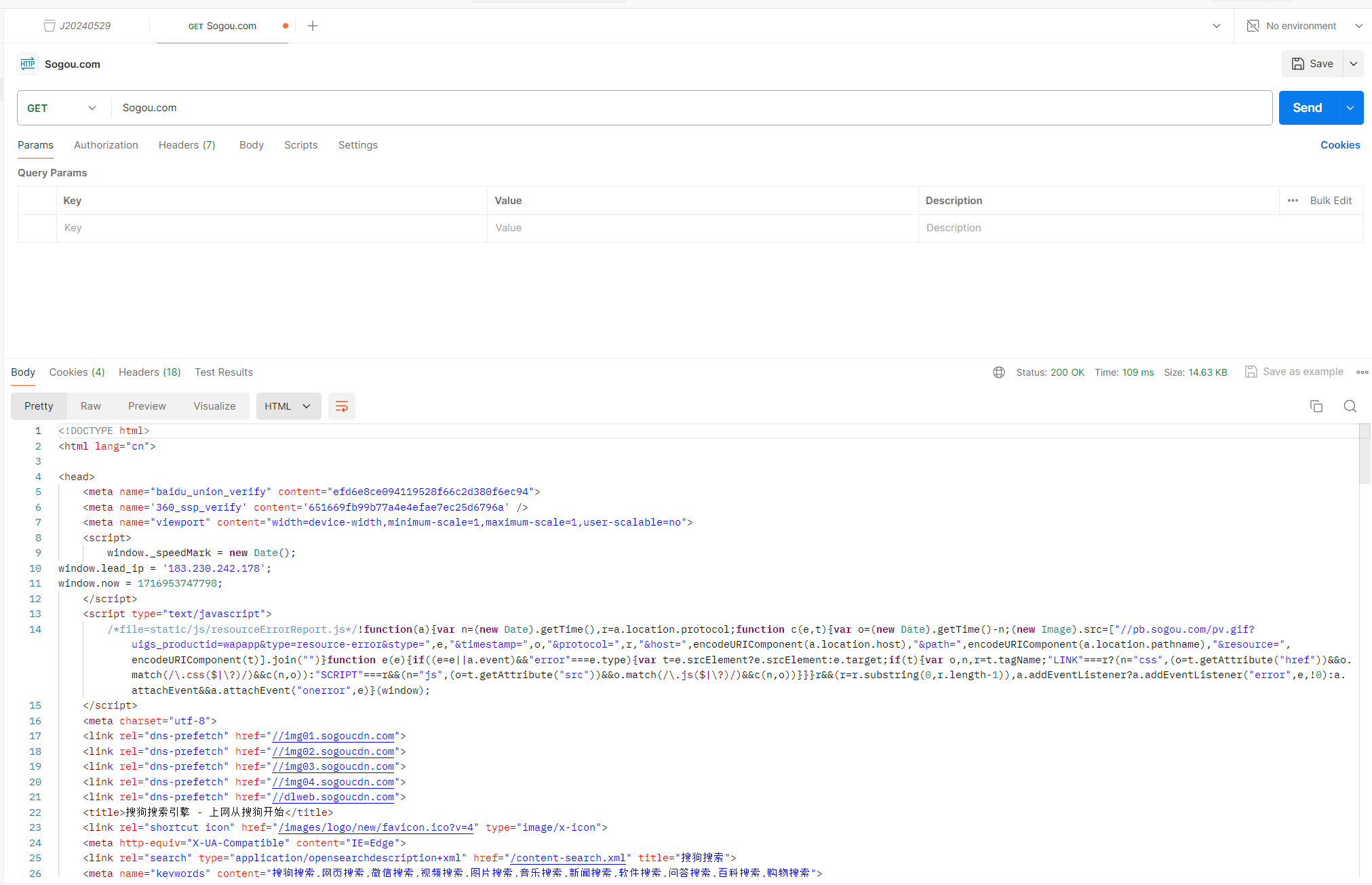
http(接上一篇文章)
认识请求报头"header"
header里面的键值对,都是标准规定的内容,很多,我们主要是认识一些关键的
host
表示对应的服务器主机的IP / 域名

实际上,这两个通常来说是一样的
但是有些时候不一样
当我们通过代码构造http请求,url里面写的以Ip地址的格式作为目标服务器,但是host写的任然是域名,此时就会出现不一致
Content-Length
表示的是body里面的数据长度
一旦有body,就需要知道 body到底有多长,才能够早知道一个完整的http请求
这个变量同时也解决了"粘包问题"
在http请求报文里面,解决"粘包问题"是通过两种方法来实现的
(1)分隔符 对于get请求来说,没有body的时候,header后面的空行就是一个分隔符
(2)长度,当有body的时候,通过空行找到body开始的位置,通过长度确定body结束的位置
Content - Type
表示body是哪种数据类型
通过http请求,我们可以传输的数据有很多,图片 /视频/ 音频 / 字体/ html/json /css...
就需要通过 Content-type来做出区分
常见选项有:
application/x-www-form-urlencoded:form
--表单提交的数据格式.此时 body 的格式形如:
java
title=test&content=hellomultipart/form-data: form
表单提交的数据格式(在 form 标签中加上enctyped="multipart/form-data".通常用于提交图片/文件.body 格式形如:
java
Content-Type:multipart/form-data; boundary=----WebKitFormBoundaryrGKcBY7ghFd3Trw
------WebKitFormBoundaryrGKCBY7ghFd3TrwA4
Content-Disposition:form-data;name="text'
title
------WebKitFormBoundaryrGKCBY7ghFd3TrwA
Content-Disposition: form-data; name="file"; filename="chrome.png'
Content-Type:image/png
PNG ... content of chrome.png ...
------WebKitFormBoundaryrGKcBY7ahEd3TrwA--application/json: 数据为 ison 格式. body 格式形如:
java
{"username" :"123456789","password":"xxxx","code":"jw7l","uuid":"d110a05ccde64b16"}一个请求里面,可能会有body
一旦有,那么length 和 type就必须存在,没有的话就不存在
User - Agent(简称UA)
表示浏览器 + 操作系统的属性
java
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36其中, (Windows NT 10.0; Win64; x64) 表示操作系统
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0表示 浏览器信息
UA主要表示的就是两个部分(操作系统版本+浏览器版本)
就是描述了用户用的什么设备打开当前网页
那么UA有什么用呢??
以前的用处就是 通过UA来实现兼容
在很久以前,浏览器发展非常迅速,在同一个时间就可能存在多个版本的浏览器,有的用户用的是老版本,有的是新版本
二者之间功能差异很大
开发者就可以通过UA来判断用户的浏览器和系统是什么水平的,返回对应的内容
至于现在的浏览器,都是大同小异的
而现在的UA主要是用来区分,当前访问的设备是电脑还是手机
如果是电脑,就返回一个宽屏的网页
如果是手机,就返回一个窄屏的网页
但是使用UA区分就意味着,网站开发者就需要维护两套代码
于是就诞生了"响应式布局",只写一套代码,就能根据你设备的尺寸,设置不同的样式,适应各种设备
referer
表示当前页面是从哪里跳转过来的
如果是直接在浏览器地址栏里面输入 URL 那么此时的referer就是空的

此时就表示,这个此时是从搜狗主页跳转过来的
Cookit
java
Cookie:
sensorsdata2015jssdkchannel=%7B%22prop%22%3A%7B%22_sa_channel_landing_url%22%3A%22%22%7D%7D;
user_locale=zh-CN;
oschina_new_user=false;
remote_way=http;
slide_id=10;
visit-gitee--2024-05-20=1; Cookie也是键值对的格式,和query string类似,都是程序员自定义的
Cookie这个的键值对,本质上都是要能够在客户端这边的硬盘上持久化保存的
但是网页是运行在浏览器上的,默认情况下,一个网页是不能够随意访问用户的硬盘的(直接操作就很危险)
但是有的网站确实是需要在用户这边存下必要的信息
希望能够持久化存储(就是写到硬盘上,即使是重启也还存在)
于是浏览器就给网页提供了特定的机制,也就是Cookie
Cookie机制不是让有服务器/网页随意的访问用户的硬盘,而是做了封装.相当于专门提供了一组文件
限制了只能往这些特殊文件里面去写,还限制了格式,只能是 键值对,不能是其他的
那么Cookit具体是怎么存的呢??
浏览器会根据不同的域名,每个网站都会有自己的一份Cookit(不同网站之间是不会有影响的)
如果你的浏览器第一次访问某个网站,那么第一次访问的时候,网站的服务器返回的htpp响应里面,就会包含set-Cookie这样的header,此时就会将一些键值对,保存在浏览器提供的Cookie里面
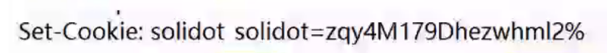
此时就会保存在浏览器的cookie里面
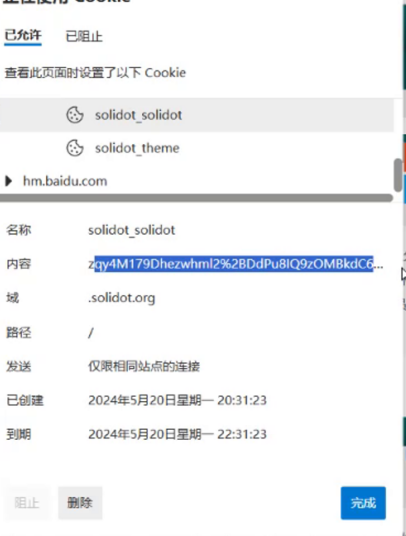
Cookie保存在浏览器之后,后续访问该网站的时候,就会在请求header中,把之前保存的这些Cookie键值对给带入进去,即还是要返回给服务器
Cookie本来就是从服务器来的,为啥还要返回给服务器??
这是因为,一个服务器是要面对很多客户端的
每个客户端有自己的偏好,此时就需要让每个客户端都保存好这样的数据,以备告诉服务器
就比如很多网站设置了夜间模式,此时关闭浏览器后,再次访问这个网站,还是希望是 夜间模式
形如上述的设置信息,必须是保存在我的浏览器里面的,后续请求这个网站,就告诉网站服务器,我要日间 / 夜间
此时网站用户很多,有的人用日间,有的人用夜间,大家的浏览器就分别存储了不同的这样的信息
Cookie里面虽然很多都是程序员自定义的,但是往往会有一个特殊的键值对,大部分网站都会有的key,是用来标识用户的身份信息
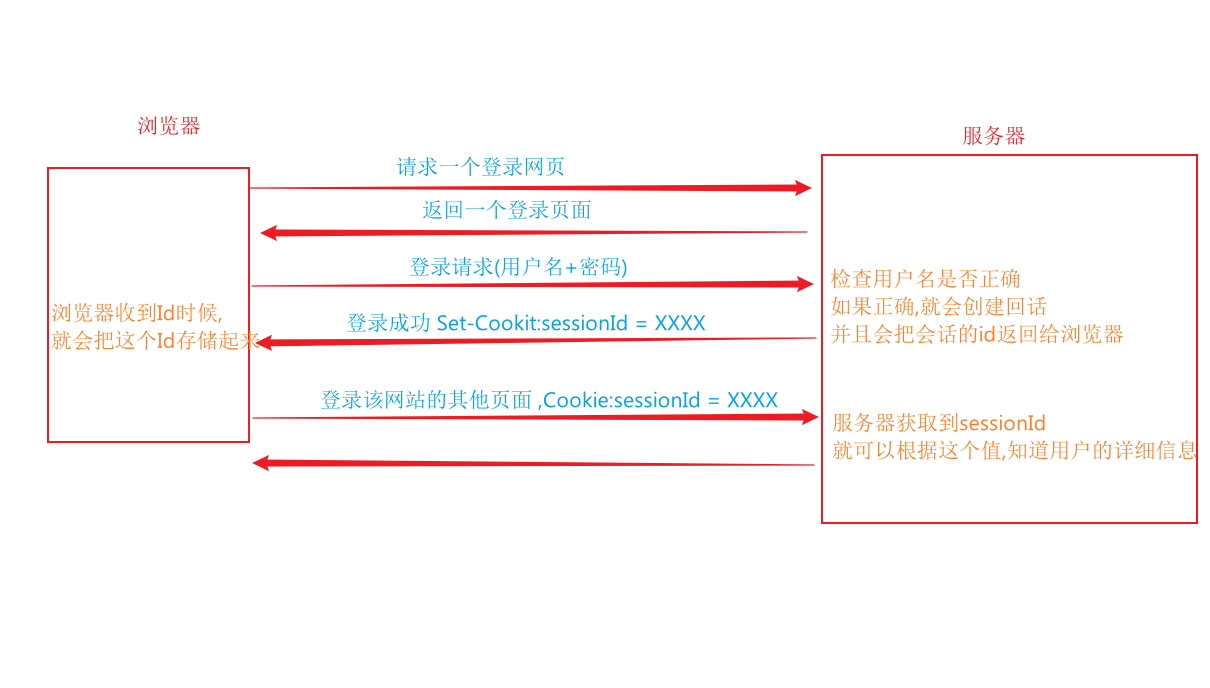
http响应里面的一些信息
状态码
就是描述了这次http请求是否成功,以及失败的原因是什么
其中有几个比较关键的
-
200 OK 表示这次访问是成功了
-
404 Not Found 表示客户端请求的资源在服务器这边不存在
-
403 Forbidden 表示客户端权限不足,被禁止访问了
-
405 Method Not Allowed 表示请求的方法,服务器不支持
-
500 Internet Server Error 服务器内部错误(bug)
-
504 Gateway Timeout 服务器访问超时了
这里的Gateway指的就是网关
要访问的服务器可能是 很多台,此时就会有一个入口服务器,就是所谓的网关服务器
这种问题常见于 "服务器比较繁忙的情况"
-
Move temporary
表示临时重定向
比如访问某个地址的时候,访问的是旧地址,自动跳转到新地址上去
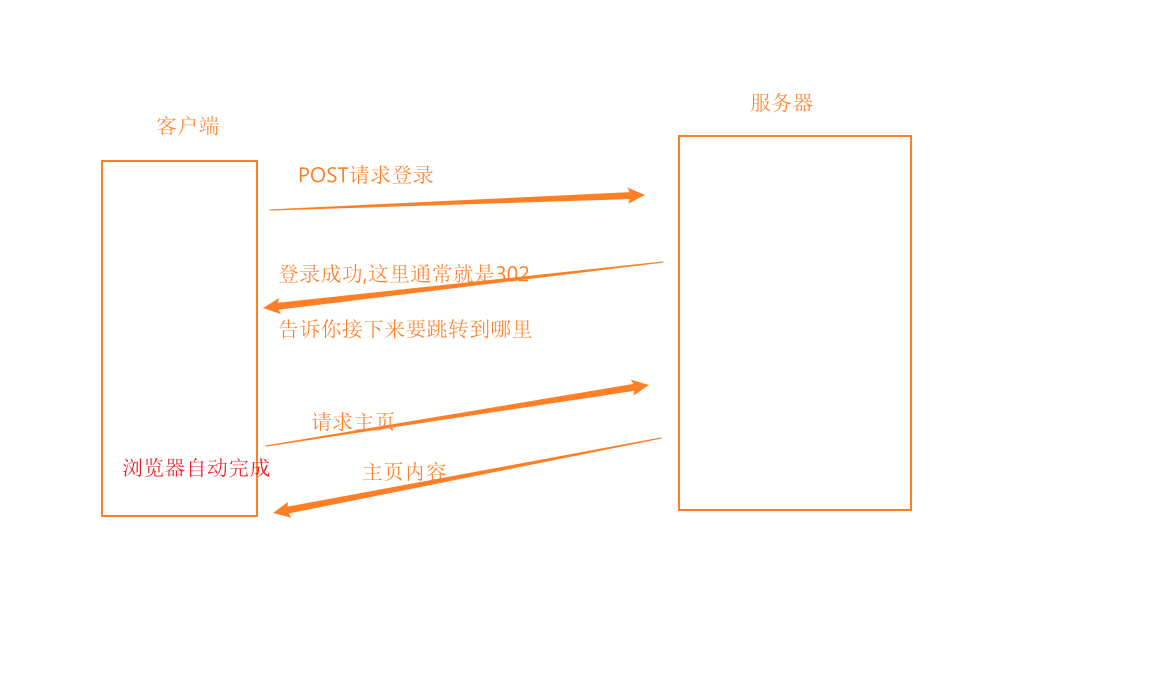
- Move Permanently
访问的旧地址和新地址之间的映射关系就确定了
此时浏览器就会缓存这样的结果
后续再次访问旧地址的时候,浏览器就可以直接构造出 新地址的请求,就减少一次 http访问了
但是如果使用的是302作为重定向,临时重定向,旧地址是否要重定向,以及重定向到哪里,就是可变的,因此每次访问旧地址,就都要使用旧地址访问服务器,获取到响应的Location属性再跳转
什么时候使用301?? 服务器迁移了.域名更新了,就可以使用301
设置字符集
设置Content-type不仅可以指定响应的数据的类型,还可以指定响应数据的字符集
如果响应数据出现乱码,就可以在这里设置好 字符集,确保数据的字符集和页面显示方式的编码是一样的
通过工具构造http请求
除了通过代码的方式来构造请求之外,还可以通过专门的工具来构造请求,更加简单.方便
尤其是做一些测试类的工作
如使用postman