提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
Spark SQL
- 一、介绍
- 二、结构化转换transformation
- 三、结构化动作action
- 四、常用函数
- 五、代码示例
-
- 1、dataframe创建
- [2、dataframe api](#2、dataframe api)
- 3、过滤行filter、where
- [4、distinct、dropDuplicates 去掉重复行](#4、distinct、dropDuplicates 去掉重复行)
- 5、sort(columns),orderBy(columns)
- 6、limit(n)
- 7、union(otherDataFrame)
- 8、withcolumn(colName,column)
- [9、withColumnRenamed(existingColName,newColName) 修改列名](#9、withColumnRenamed(existingColName,newColName) 修改列名)
- [10、drop(columnName1,columnName2) 删除指定的列](#10、drop(columnName1,columnName2) 删除指定的列)
- 11、dropna()删除缺失值
- 12、分组聚合
- 13、describe
- 14、action
- 六、使用SQL查询
- 七、用户自定义函数
-
- 1、udf函数
- [2、# 注册函数](# 注册函数)
- [3、与pandas dataframe的转换](#3、与pandas dataframe的转换)
- 八、窗口函数
-
- [1、rangking 函数](#1、rangking 函数)
- 2、分析函数
- 3、其他常用函数
- 4、开窗函数和普通聚合函数的区别
- 5、开窗函数语法结构
- 6、对于滑动窗口的范围指定,有两种方式:基于行和基于值
-
- 1、基于行
- 2、基于值
- [3、row_number 显示分区中的当前序号](#3、row_number 显示分区中的当前序号)
- 4、rank与dense_rank
- [5、前后函数 lag(n)/lead(n)](#5、前后函数 lag(n)/lead(n))
一、介绍

Spark SQL是一个用于处理结构化数据对组件,主要用于结构化处理和对数据执行SQL查询,类似于pandas操作,只不过数据量相对更大。
- 批量处理与数据分析
- 在数据挖掘过程中用于数据准备和数据探索
- 内存需求量大的数据,用spark SQL会出现内存溢出,建议使用hive
- 不支持数据更新
- 不可建立索引
spark SQL数据集类型:DataFrame
- 是一个以命名列方式组织的分布式数据集,与关系数据库中的表类似
- 带有schema元信息,这使得spark SQL支持python、Scala、Java语言,降低开发难度
- 可以由RDD创建,也与pandas.DataFrame互换
- 支持hive、parquet、hbase、json、Avro等多种数据格式
使用所提供的结构化操作来操作或转换data frame:
-
结构化操作有时被描述为一种用于分布式数据操作的特定领域的语言(DSL)
-
结构化操作分为两类:transformation、action
-
dataframe是不可变的,他们的转换操作总是返回一个新的dataframe
-
大多数dataframe结构化操作都需要指定一个或多个列
-
对于其中的一些列,列是以字符串的形式指定的,对于某些列,需要被指定为column类的实例
在较高的层次上,列类提供的功能可以分解为以下类别
-
数学运算:加法、乘法等
-
将列值与文字之间的逻辑比较,例如相等、大于、等于等
-
字符串匹配模式
二、结构化转换transformation
结构化转换transformation:
- 操作的函数通常与数据表中SQL操作发现的函数相似,如选择数据:select函数
- 删除某列:drop函数
- 过滤数据:where和filter函数(同义)
- 限制返回量limit
- 重命名列:withColumnRename函数
- 增加新列:withColumn
- 数据排序:orderBy和sort函数(等价)
三、结构化动作action
结构化动作action具有与RDD动作相同的eager evalueated语义,因此他们触发了所有导致特定动作的转换的计算量,函数有:
- show()
- show(numRows)
- show(truncate)
- show(numRows,truncate)
- head()、first()
- head(n)、take(n)
- takeAslist(n)
- collect()、collectAslist、count
四、常用函数
1、数值计算函数
- avg(col)返回平均值的聚合函数
- exp(col)返回常数e的指数函数
- greatest(col)返回多个列比较大最大值
- least(col)返回多个列比较大最小值
- log(agr1,agr2=None)返回第一个参数为底的第二参数的对数,如果仅有一个参数,则返回自然对数
- min/max(col)返回列中最小/大值的聚合函数
- pow(coll,col2)返回Coll为底的指数为col2的指数函数,可以传入列对象或数值
- rand(seed=None)返回0~1之间的随机数
- sum(col)返回总和的聚合函数
2、日期计算函数
- current_date()返回当前日期
- current_timestamp()返回当前时间戳
- month(col)以整数形式返回日期中的月份
- trunc(date,format)返回按指定格式进行截断的日期
- datadiff(end,start)返回2个日期之间相差天数
3、字符串操作函数
- lower/upper(col)字符串小/大写后返回
- length(col)返回字符串长度
- initcap(col)返回首字母大写的字符串,如果有空格(句子或短语)则每个首字母都大写
- trim(col)去除字符串两端空格
- substring(str,pos,len)返回从post开始的长度为len的字符串
五、代码示例
实例化spark
sc = SparkSession.builder.appName('sparkSQL').getOrCreate()1、dataframe创建
-
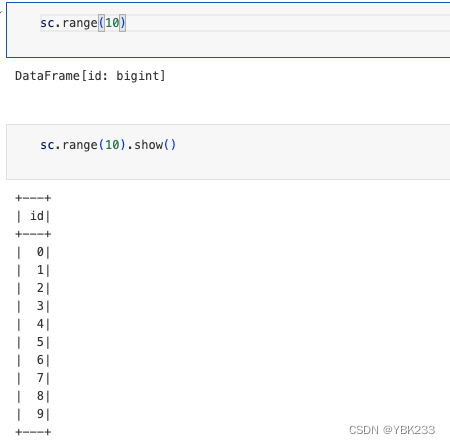
内置函数:创建spark.range(start,end,step)数据区间[start,end),start默认是0,step默认是1
sc.range(10)
sc.range(10).show()
- 由其他数据对象转化成dataframe
spark.createDataFrame(data,schema)-
data数据:列表、RDD、pandas的dataframe都可以
-
schema:元数据
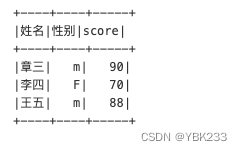
scores = [['章三','m',90],['李四','F',70],['王五','m',88]]
string_schema = """
姓名string
,性别string
,score int
"""中文的字段名,或者别名,需要用``上引号(tab键上面的)括起来
sc.createDataFrame(data=scores,schema=string_schema).show()
-
spark = sc.sparkContext
rdd1 = spark.parallelize([["章三","男",90],["李四","女",70],["王五","男",88]])
sc.createDataFrame(rdd1,schema=string_schema).show()
-
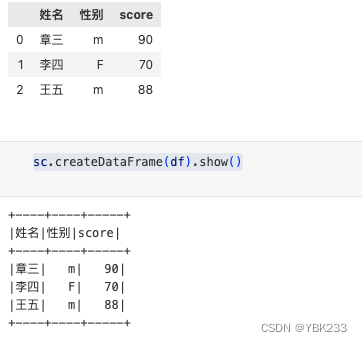
pandas中的data frame转换
df = pd.DataFrame(scores,columns=['姓名','性别','score'])
sc.createDataFrame(df).show()
-
通过文件创建
movies = sc.read.csv('./data/spark_data/movies.csv',header = True)
movies.show(5)

2、dataframe api
与dataframe类似,dataframe的API也分为两类:transformation和action
transformation
选择列select selectExpr
select与SQL中的类似,选取指定列(指定条件的数据)
selectExpr与select类似,不同的是可以解析表达式(地处进行了SQL转化)
spark = SparkSession.builder.appName('sparkSQL').getOrCreate()
movies_parquet = spark.read.parquet("./data/spark_data/movies.parquet")
movies_parquet.printSchema()
movies_parquet.select("*",'movie_title').show(5)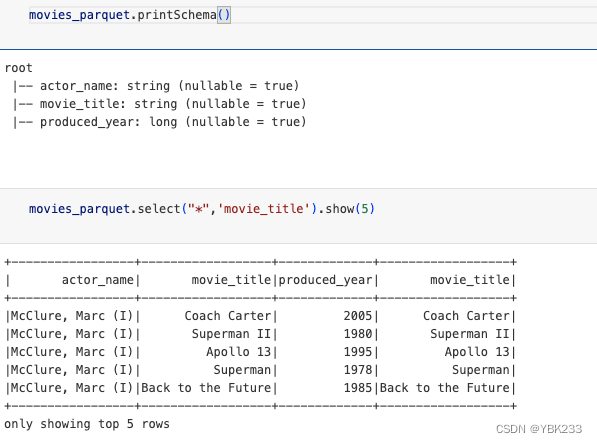
#查询电影上映的年代
#select不能存放字符串表达式
#这里会报错,用selectexpr
movies_parquet.select('movies_title','produced_year-produced_year%10').show(5)

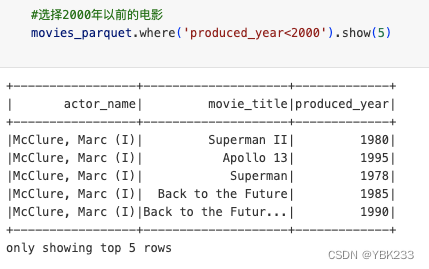
3、过滤行filter、where
filter where用来设置条件筛选字段,两者用法一致
#不等比较操作符 !=
movies_parquet.where('produced_year!=2000').show(5)
#组合一个或多个比较表达式,我们将使用or或and表达运算符
#2000~2005范围内的电影
movies_parquet.where('produced_year>2000 and produced_year<2005').show(5)
4、distinct、dropDuplicates 去掉重复行
#电影数量
movies_parquet.selectExpr('count(movie_title)').show()
#去重后的数量
movies_parquet.select('movie_title').distinct().selectExpr('count(movie_title)').show()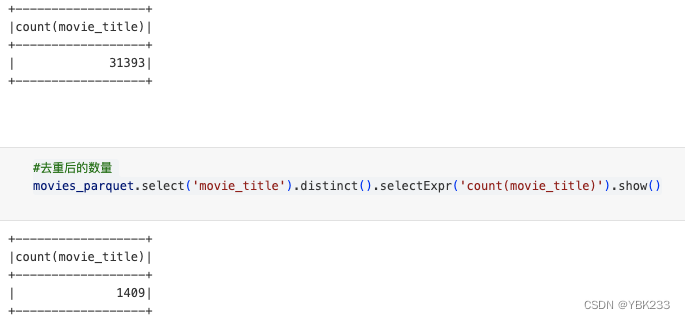
5、sort(columns),orderBy(columns)
#根据电影title名称长短排序
(movies_parquet
.dropDuplicates(['movie_title'])
.selectExpr("*",'length(movie_title)t_len')
.sort('t_len')
).show()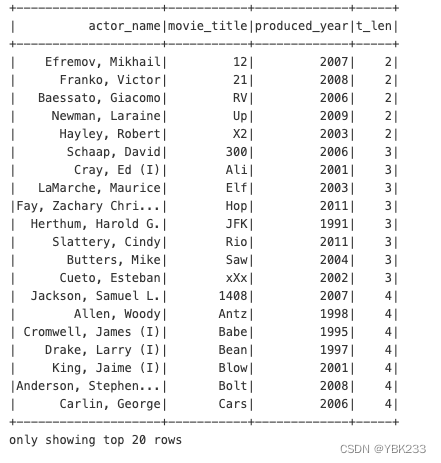
#使用sparkSQL函数实现升降的设定
from pyspark.sql.functions import desc,asc
(movies_parquet
.dropDuplicates(['movie_title'])
.selectExpr("*",'length(movie_title)t_len')
.sort(desc('t_len')
,asc('produced_year'))
).show()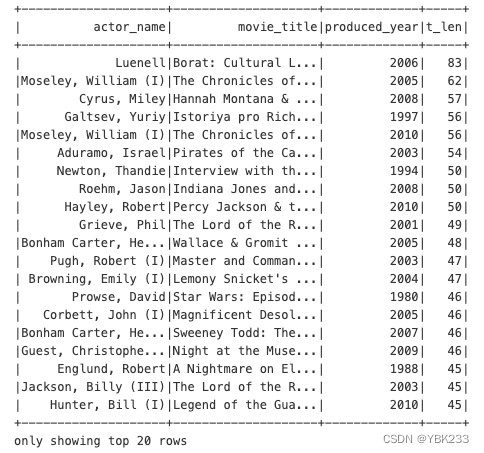
6、limit(n)
# 选择前3行
movies_parquet.limit(3).show()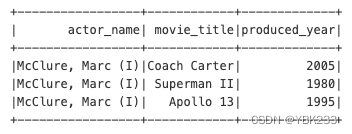
# 显示前3行
movies_parquet.show(3)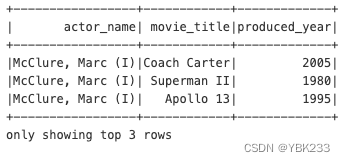
7、union(otherDataFrame)
相当于SQL的union all,去重用前面的方法
df1 = spark.createDataFrame([[1,2,3]],['c1','c2','c3'])
df2 = spark.createDataFrame([[4,5,6]],['c2','c3','c1'])
df1.union(df1).show()
df1.union(df2).show()
8、withcolumn(colName,column)
向DataFrame增加一个新的列,基于某一列表达式
movies_parquet.withColumn('年代',movies_parquet.produced_year - movies_parquet.produced_year%10).show(10)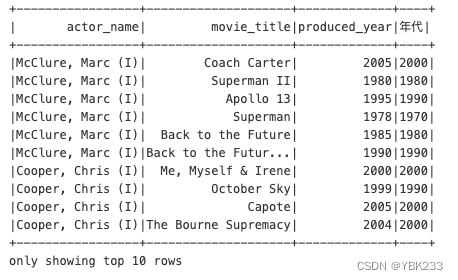
9、withColumnRenamed(existingColName,newColName) 修改列名
movies_parquet.withColumnRenamed('actor_name','actor').show(5)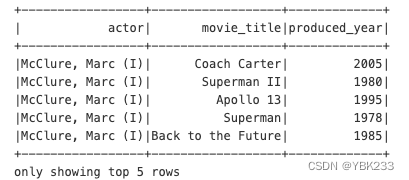
10、drop(columnName1,columnName2) 删除指定的列
movies_parquet.drop('actor_name').show(5)
11、dropna()删除缺失值
badmovie = [[None,None,2005],
['test',None,2003],
[None,'test1',2007]]
bad_df = spark.createDataFrame(badmovie,schema=movies_parquet.schema)
bad_df.dropna(how='any',subset=['actor_name','produced_year']).show()
# 非空数据大于等于2则不删除
bad_df.dropna(thresh=2 #非空数据至少有2个
).show()
12、分组聚合
- groupBy传入分组的列字符串形式
- agg 传入聚合表达式
-
例如字典形式{'movie_title':'count'}对字段'movie_title'进行count计算
-
也可以使用内置函数 例如F.count(movies_parquet.movie_title).alias('count')
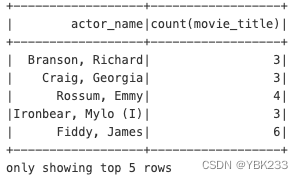
movies_parquet.groupBy('actor_name').agg({'movie_title':'count'}).show(5)
-
import pyspark.sql.functions as F #使用F中的count函数,这样返回dataframe列对象,可以用alias设置列名
movies_parquet.groupBy('actor_name').agg(F.count('movie_title')).show(5)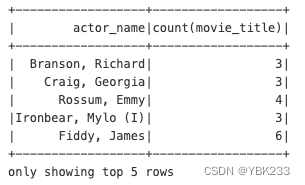
13、describe
movies_parquet.describe().show()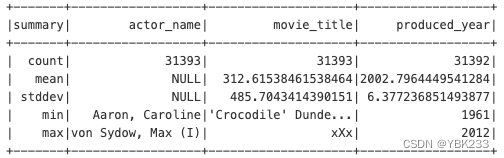
14、action
1、show
- 查看数据可以使用show()函数,这样程序会将数据打印到代码下方
- n表示要展示的数据行数,默认20行
- truncate显示时列宽,默认最多显示20个字符,可以给整数设置其显示宽度
2、head
返回数据第一行
movies_parquet.head()
movies_parquet.head()['actor_name']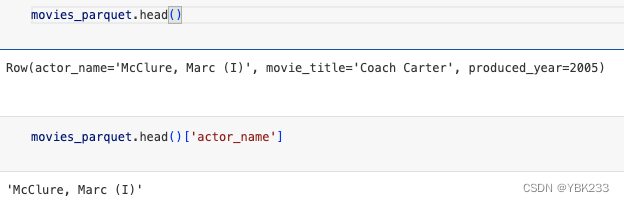
3、first
movies_parquet.first()
4、take
movies_parquet.take(3)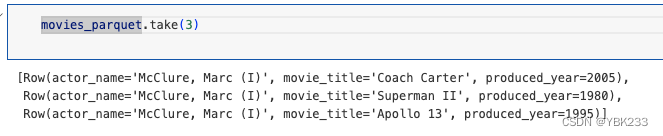
5、collect
以列表形式返回客户端
movies_parquet.limit(3).collect()
6、count
movies_parquet.limit(3).collect()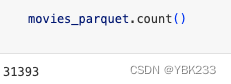
六、使用SQL查询
sparkSQL提供的最酷功能之一是能够使用SQL来执行分布式数据操作或大规模数据分析
- spark实现了ASNI SQL:2003修订版的一个子集
- 需要先将DataFrame注册为视图,然后再进行SQL查询
- spark为临时视图提供了两个级别的范围,一个是spark会话级别,第二个作用域级别是全剧级别的
- 所有已注册的视图都保存在spark元数据目录中,可以通过sparksession访问该目录
- 使用sparksession类的SQL函数执行SQL语句
1、createOrReplaceTempView 注册视图
# 将df注册为临时视图movies
movies_parquet.createOrReplaceTempView('movies')2、查询
spark.sql('select * from movies limit 3').show()
与API混用
# 电影数量高于平均值的演员信息
spark.sql('''
select actor_name,numb
,avg(numb) over() avg_numb
from(select actor_name
,count(*)numb
from movies group by actor_name) t
''').where('numb>avg_numb').show()
3、常用函数
-
pyspapyspark.sql.functionsrks提供的用于数值、字符串、日期的函数远不止于这些,还有关于编码转换、进制转换、时区转换、数组转换、三角函数等函数
-
当我们使用API的方法使用DataFrame的时候需要使用从pyspark.sql.functions导入的相关函数
-
当我们以SQL形式查询数据时,可以直接在SQL中使用这些函数
-
内部函数先介绍一下时间相关函数
#通过语法 desc function extended 函数名 ,查看函数文档
自定义函数,以更好的格式查看文档信息
def print_doc(func_name:str)->None:
for i in spark.sql(f'desc function extended {func_name}').head(100):
print(i['function_desc'])print_doc('explode')

spark.sql('show functions').count()
spark.sql('show functions').show(333,False)
4、内置函数
内置函数:处理日期的时间函数
spark内置的日期时间函数大致可分为以下三个类别:
- 1)将日期或时间戳从一种格式转换为另一种格式
- 2)执行日期时间计算
- 3)并从日期或时间戳中提取特定的值
1、字符串与时间(data,datetime,unix_timestamp)互换
日期和时间转换函数:这些函数使用的默认的日期格式为yyyy-mm-dd:HH:mm:ss
- to_timestamp,转成datatime
- to_date,转成date
- to_unix_timestamp/unix_timestamp转换为整数Unix时间戳
-
注意to_unix_timestamp只能在SQL里面使用,API上不行 unix_timestamp则在两边均可使用
test_data = [(1,'2023-05-08','2023-05-08 11:22:33','28-05-2023','28-05-2023 13:50')]
test_DF = spark.createDataFrame(test_data,schema=['id','date','datetime','date_str','dt_str'])
test_DF.show()
test_DF.printSchema()
-
将这些字符串转换成date、timestamp和unix timestamp,并指定一个自定义的date和timestamp格式
-
SQL的格式
#注册视图
test_DF.createOrReplaceTempView('test_DF')- to_date将各种字符串替换为date
- to_timestamp将字符串转换为datetime
- unix_timestamp将字符串转换为整数
test_DF.show()
spark.sql('''
select to_date(datetime) date2
,to_timestamp(dt_str,'dd-MM-yyyy HH:mm')
from test_DF
''').show()

spark.sql('''
select to_date(datetime) date2
,to_timestamp(dt_str,'dd-MM-yyyy HH:mm')
from test_DF
''').printSchema()
-
API调用方式
test_DF.select(F.to_date('datetime'),
F.to_timestamp('dt_str','dd-MM-yyyy HH:mm')).show()
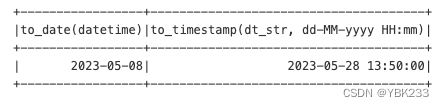
3、日期或时间戳转换为时间字符串
将日期或时间戳转换为时间字符串,使用
-
date_format函数和定制日期格式
-
from_unixtime函数将Unix时间戳(以秒为单位)转换为字符串
from pyspark.sql.functions import date_format,from_unixtime
4、时间计算
-
datediff
-
months_between
-
last_day
-
提取日期或时间戳值的特定字段(如年,月、小时、分钟和秒)从一个日期值中提取指定的字段
case_df = spark.createDataFrame([('a','2015-01-10','2015-02-10'),('b','2017-05-20','2025-02-15')]
,schema = ['name','join_date','leave_date'])
case_df.createOrReplaceTempView('case_df')
case_df.show()

5、执行date和month计算
-
待了多久(天)
-
待了多久(月)
-
离开日期所在月最后一天
from pyspark.sql.functions import datediff,months_between,last_day
API
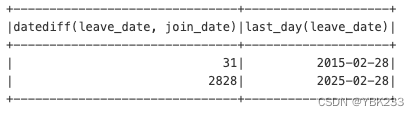
case_df.select(F.datediff('leave_date','join_date'),
F.last_day('leave_date')).show()
6、执行日期加、减计算
-
date_add:date_add(start,num_days) - 返回 start_date之后num_days天的日期
-
date_sub:date_sub(start,num_days) - 返回 start_date之前num_days天的日期
from pyspark.sql.functions import date_add,date_sub
7、提取日期或时间戳值的特定字段(如年、月、小时、分钟、秒)
from pyspark.sql.functions import year,month,dayofmonth,hour,second,dayofweek七、用户自定义函数
1、udf函数
使用udf函数涉及有三个步骤:
-
1)首先编写一个函数并进行测试
-
2)通过函数名及其签名传递给spark的udf函数来注册该函数
-
3)在dataFrame代码或发出SQL查询时使用udf
data = [[101,'中山路','南京路'],
[102,'北京路','中山路'],
[103,'南京路','北京路'],
[104,'北京路','南京路'],
[105,'中山路','南京路'],
[106,'南京路','北京路'],
]
route_df = spark.createDataFrame(data,schema='id int ,st string,end string')
route_df.show()

# 每个线路的订单数量,线路不区分起点和终点
def get_route(st,ed):
return "-".join(sorted([st,ed]))
from pyspark.sql.functions import udf
udf_get_route = udf(get_route)
route_df.select('id',udf_get_route('st',"end").alias('route')).show()
route_df.select('id',udf_get_route('st',"end").alias('route')).groupBy('route').count().show()
2、# 注册函数
spark.udf.register('udf_get_route_sql',get_route)
route_df.createOrReplaceTempView('route_df')
spark.sql("""
select udf_get_route_sql(st,end)
,count(*)
from route_df
group by udf_get_route_sql(st,end)
""").show()
3、与pandas dataframe的转换
result = spark.sql("""
select udf_get_route_sql(st,end)
,count(*)
from route_df
group by udf_get_route_sql(st,end)
""")
# action操作toPandas()
df = result.toPandas()
df
df.plot(kind = 'bar'
,x='udf_get_route_sql(st, end)'
,y='count(1)')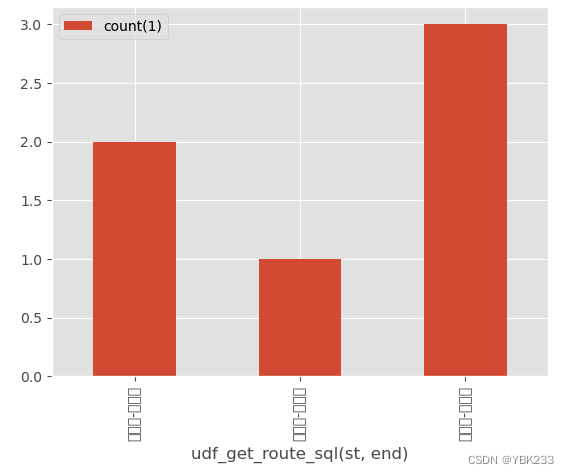
文字未正常加载,可以使用以下代码解决
import matplotlib.pyplot as plt
plt.rcParams['axes.unicode_minus']=False
plt.rcParams['font.sans-serif']=['Simhei']八、窗口函数
窗口函数:排序函数、分析函数、聚合函数
1、rangking 函数
- rank:返回一个frame内行的排名和排序,基于一些排序规则
- dense_rank:类似于rank,但是在不同的排名之间没有间隔,紧密衔接显示
- ntile(n):在一个有序的窗口分区中返回ntile分组ID.比如,如果n是4,那么前25%行得到的ID值为1,第二个25%行得到的ID值为2,依次类推
- row_number:返回一个序列号,每个frame从1开始2、分析函数
- cume_dist:返回一个frame的值的累积分布。换句话说,低于当前的行的比例
- log(col,offset):返回当前行之前offset行的列值
- lead(col,offset):返回当前行之后offset行的列值它可以理解为记录集合,开窗函数也就是在满足某种条件的记录集合上执行的特殊函数。对于每条记录都要在此窗口内执行函数,有点函数随着记录不同,窗口大小都是固定的,这
种属于静态窗口;有的函数则相反,不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口。开窗函数的本质还是聚合运算,只不过它更具灵活性,它对数据的每一行,都
使用与该行相关的行进行计算并返回计算结果。
3、其他常用函数
- count(col)返回col列的计数
- countDistinct(col,*cols)返回列中不相同的值的个数
- first/last(col)返回第一/最后行数据的聚合函数
4、开窗函数和普通聚合函数的区别
- 聚合函数上讲多条记录聚合为一条而开窗函数则是每条记录都会执行,有几条记录执行完还是几条
- 聚合函数也可以用于开窗函数中
- 我们知道聚合函数对一组值执行计算并返回一个值,但有时候一组数据只返回一个结果值并不能满足需求
数据初始化
logFile = './data/spark_data/order_tab.csv'
from pyspark.sql.types import FloatType,StringType,DateType,IntegerType,StructType,StructField
schema1 = StructType(
[StructField('order_id',IntegerType(),True),
StructField('user_no',StringType(),True),
StructField('amount',IntegerType(),True),
StructField('create_date',DateType(),True)
]
)
logData = spark.read.csv(logFile,schema=schema1,header=True)
logData.printSchema()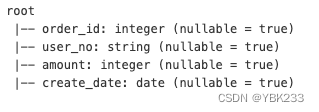
logData.createOrReplaceTempView('order_tab')
spark.sql('select * from order_tab').show()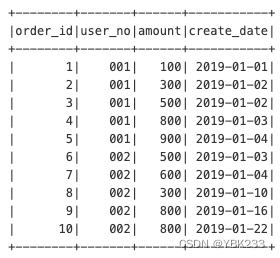
# 查询每个用户的订单总金额
spark.sql('select user_no ,sum(amount) from order_tab group by user_no').show()
#查询每个用户按时间顺序的累计订单金额
spark.sql('select *,sum(amount) over (partition by user_no order by create_date) cusum from order_tab').show()
spark.sql('select *,sum(amount) over (partition by user_no) cusum from order_tab').show()
5、开窗函数语法结构
- 开窗函数名(\<字段名\>) over (partiti on by \<分组字段\> order by \<排序字段\> \[desc] \<窗口区分\>)
开窗函数的一个概念是当前行,当前行属于某个窗口,窗口由over关键字用来指定函数执行的窗口范围,如果后面括号中什么都不写,则意味着窗口包含满足where条件的所有行,
开窗函数基于所有行进行计算;如果不为空,则有三个参数来设置窗口:-
partition by子句:按照指定字段进行区分,两个分区由边界分割,开窗函数在不同的分区内分别执行,在跨越分区边界时重新初始化
-
order by子句:按照指定字段进行排序,开窗函数讲按照排序后的记录顺序进行编号。可以和partition by子句配合使用,也可以单独使用
-
frame子句:当前分区的一个子集,用来定义子集的规则,通常用来作为滑动窗口使用
- 如果order by部分已定义,但frame部分缺省,则表示窗口为分区第一行到当前行
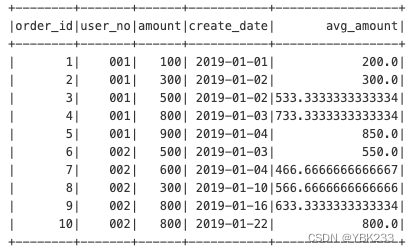
查询每个用户按下单时间顺序,前一行和后一行记录的平均订单金额
spark.sql("""
select * ,avg(amount) over (partition by user_no order by create_date rows between 1 preceding and 1 following) avg_amount
from order_tab
""").show()
-
6、对于滑动窗口的范围指定,有两种方式:基于行和基于值
1、基于行
通常使用rows between frame_start and frame_end语法来表示行范围,frame_start和frame_end可以支持如下关键字,来确定不同的动态行记录:
- current row 边界时当前行,一般和其他范围关键字一起使用
- unbounded preceding 边界时分区中的第一行
- unbounded following 边界时分区中的最后一行
- expr preceding 边界时当前行减去expr的值
- expr following 边界时当前行加上expr的值
比如下面都是合法的行范围- rows between 1 preceding and 1 following 窗口范围是分区中的当前行、前一行、后一行一共三行记录
- rows between preceding and current row 窗口范围是分区中的前一行、当前行一共两行记录
- rows between current row and 1 following 窗口范围是分区中的当前行、后一行一共两行记录
- rows unbounded preceding 窗口范围是分区中的第一行到当前行
- rows between unbounded preceding and current row 窗口范围是分区中第一行到当前行
- rows between current row and unbounded preceding 窗口范围是分区中的当前行到最后一行
- rows between unbounded preceding and unbounded following 窗口范围是分区中的第一行到最后一行
2、基于值
和基于行类似,通常使用range between frame_start and frame_end语法来表示值范围,比如下面都是合法的值范围
- range between 1 preceding and 1 following 窗口范围是分区中的当前行对应值-1、和当前行对应值+1范围内的记录
- range between 1 preceding and current row 窗口范围是分区中的当前行对应值-1、和当前行范围内的记录
- range between current row and 1 following 窗口范围是分区中的当前行对应值、和当前行对应值+1范围内的记录
- range unbounded preceding 窗口范围是分区中的第一行对应值、和当前行对应值范围内的记录
- range between unbounded preceding and current row 窗口范围是分区中的第一行对应值、和当前行对应值范围内的记录
- range between current row and unbounded preceding 窗口范围是分区中的当前行对应值、和最后一行对应值范围内的记录
- range between unbounded preceding and unbounded following 窗口范围是第一行对应值、和最后一行对应值范围内的记录
3、row_number 显示分区中的当前序号
示例:查询每个用户订单金额最高的前三个订单
spark.sql("""
select * from
(select *
,row_number() over (partition by user_no order by amount desc) rb
from order_tab) t
where rb<4
""").show()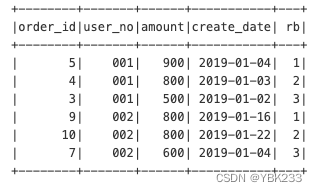
4、rank与dense_rank
以上结果中用户002的前两个订单的金额都是800,随机排为第一和第二,但实际两笔订单金额应该并列第一
这种情况row_number函数就不能满足要求,需要rank和dense_rank函数,这2个函数和row_number函数类似,只是在出现重复值时处理逻辑不同
示例:使用三个不同的序号函数,查询不同用户的订单中,按照订单金额进行排序,显示出相应的排名
5、前后函数 lag(n)/lead(n)
分区中位于当前行前n行(lag)/后n行(lead)的记录值
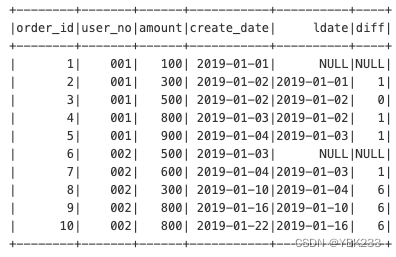
示例:查询上一个订单距离当前订单的间隔天数
spark.sql('select *,lag(create_date,1) over(partition by user_no order by create_date) ldate from order_tab').show()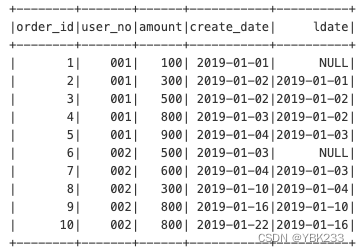
spark.sql("""
select *,datediff(create_date,ldate)diff
from (select * ,lag(create_date,1) over (partition by user_no order by create_date) ldate
from order_tab) t
""").show()