一 .概念
ILM定义了四个生命周期阶段:
Hot:正在积极地更新和查询索引。
Warm:不再更新索引,但仍在查询。
cold:不再更新索引,很少查询。信息仍然需要可搜索,但是如果这些查询速度较慢也可以。
Delete:不再需要该索引,可以安全地将其删除
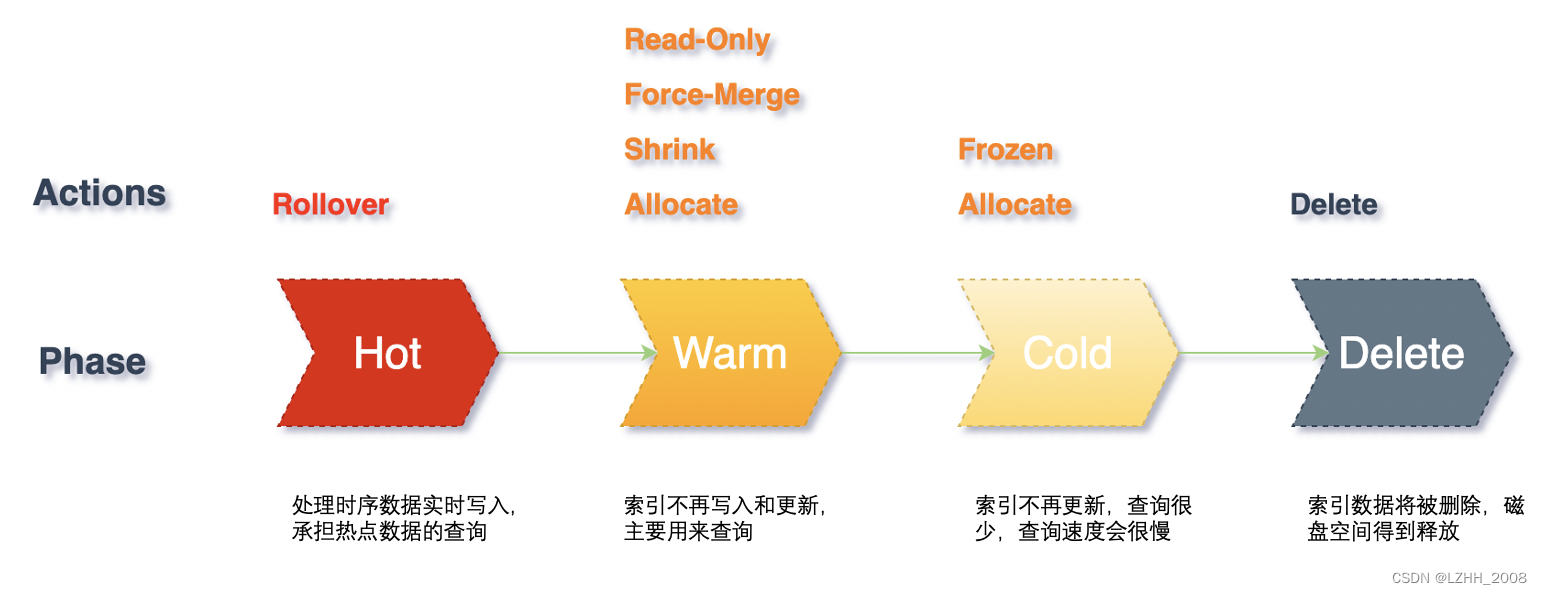
仅仅在 Hot阶段 可以设置 rollover滚动
在实验中可以修改设置,来缩短ILM检测时间间隔。ILM定期运行(indices.lifecycle.poll_interval),默认是10分钟,检查索引是否符合策略标准,并执行所需的任何步骤
java
PUT /_cluster/settings
{ "transient": { "indices.lifecycle.poll_interval": "1m" } }参数的设置:满足任意一个创建新的索引
HOT
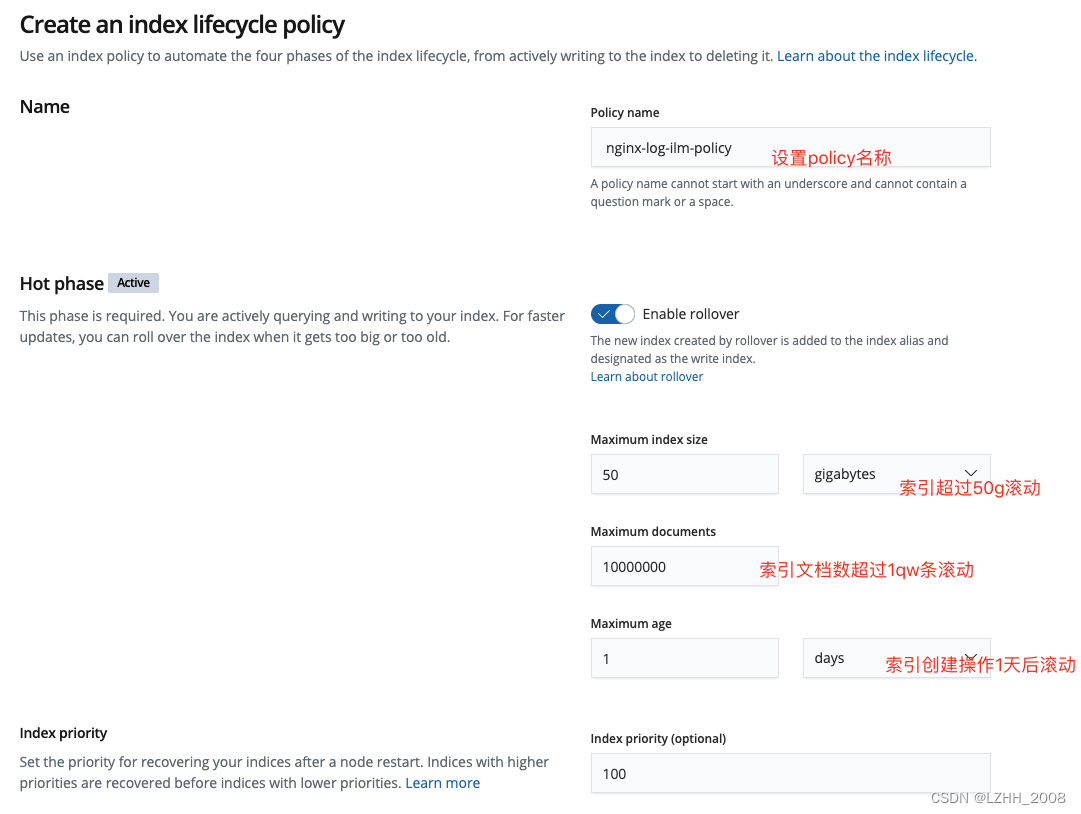
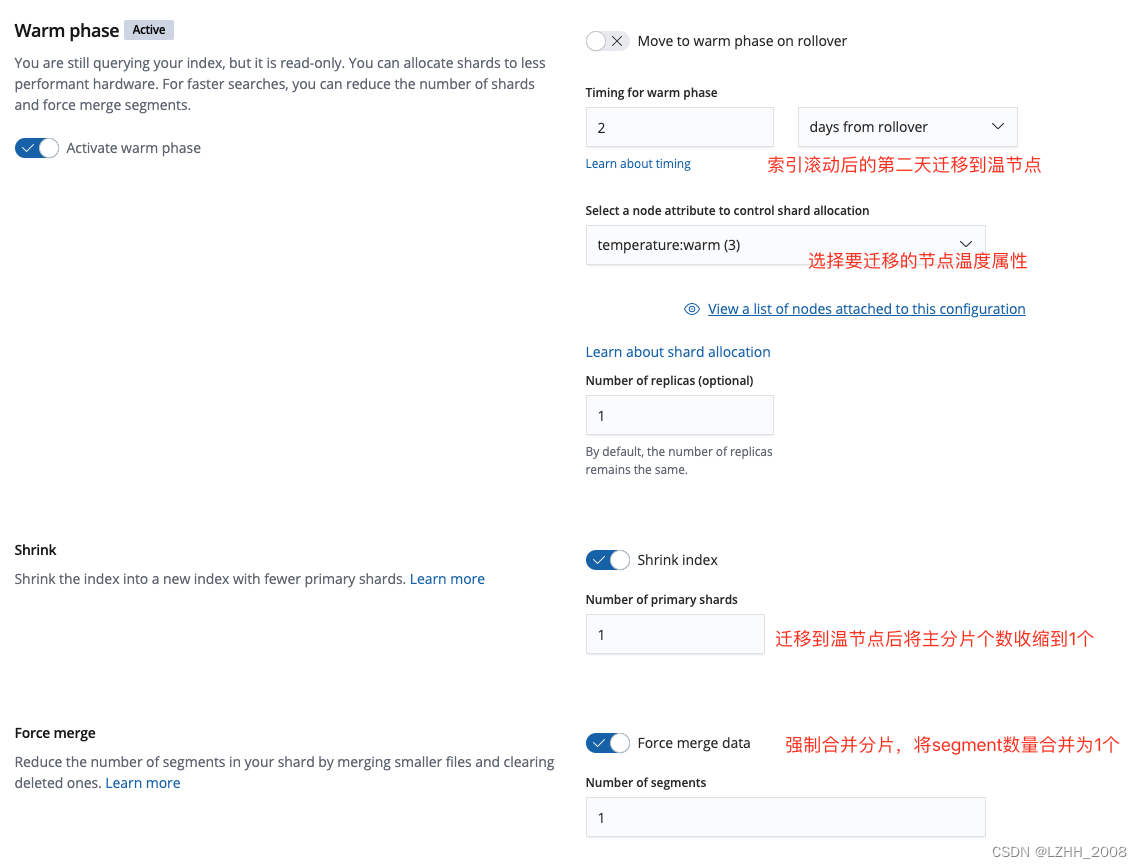
WARM
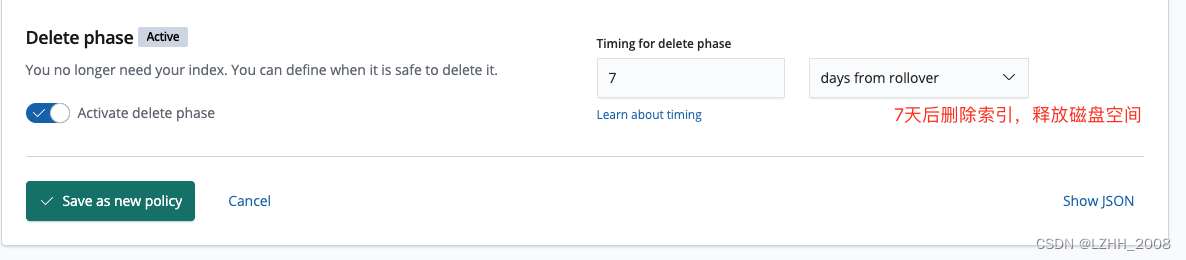
Delete
二. 实战
1 .创建生命周期策略模板:PUT 请求
http://localhost:9099/_ilm/policy/my_index_rollover_policy
"max_docs": 5000000 设置超过500万是创建新的索引,实际测试可以设置小一点
java
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_docs": 5000000
},
"set_priority": {
"priority": 100
}
}
},
"warm": {
"min_age": "30d",
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"shrink": {
"number_of_shards": 1
},
"allocate": {
"number_of_replicas": 1
},
"set_priority": {
"priority": 50
}
}
},
"cold": {
"min_age": "90d",
"actions": {
"freeze": {},
"allocate": {
"require": {
"type": "cold"
}
},
"set_priority": {
"priority": 10
}
}
},
"delete": {
"min_age": "3650d",
"actions": {
"delete": {}
}
}
}
}
}- 创建索引模板(日志统计索引) PUT 请求:
http://localhost:9099/_template/my_statistic_log
java
{
"index_patterns": [
"my_statistic_log-*"
],
"settings": {
"index.number_of_shards": 5,
"index.number_of_replicas": 1,
"refresh_interval": "60s",
"index.lifecycle.name": "my_index_rollover_policy",
"index.lifecycle.rollover_alias": "statistic_log_write"
},
"aliases": {
"statistic_log_read": {}
},
"mappings": {
"log": {
"dynamic": "strict",
"_field_names": {
"enabled": false
},
"dynamic_templates": [
{
"date": {
"match": "*Date",
"mapping": {
"type": "date"
}
}
},
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
},
{
"long_or_text": {
"match": "*Time",
"mapping": {
"type": "date"
}
}
},
{
"dataFormat": {
"match": "*Date",
"mapping": {
"type": "date"
}
}
},
{
"timeFormat": {
"match": "*Time",
"mapping": {
"type": "date"
}
}
},
{
"noAnalyzed": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
],
"properties": {
"area": {
"type": "keyword"
},
"desc": {
"type": "keyword"
},
"hour": {
"type": "integer"
},
"day": {
"type": "integer"
},
"startTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"totalCount": {
"type": "long"
}
}
}
}
}- 根据索引模板创建起始索引(日志统计索引)
put 请求: http://localhost:9099/my_statistic_log-000001
java
{
"aliases": {
"statistic_log_write": {
"is_write_index": true
}
}
}- 查看索引生效:GET请求
http://localhost:9099/my_statistic_log-000001/_ilm/explain
https://www.elastic.co/guide/en/elasticsearch/reference/6.8/_setting_up_a_new_policy.html