创建高性能的索引
选择合适的索引列顺序
当使用前缀索引的时候,在某些条件值的基数比正常值高的时候,问题就来了。例如,在某些应用程序中,对于没有登录的用户,都将其用户名记录为"guest",在记录用户行为的会话(session)表和其他记录用户活动的表中"guest"就成为了一个特殊用户ID.一旦查询涉及这个用户,那么和对于正常用户的查询就大不同了,因为通常由很多会话都是没有登录的。系统账号也会导致类似的问题。一个应用通常都有一个特殊的管理员账号,和普通账号不同,它并不是一个具体的用户,系统中所有的其他用户都是这个用户的好友,所以系统往往通过它向网站的所有用户发送状态通知和其他消息。这个账号的巨大的好友列表很容易导致网站初夏你服务器性能问题。这实际上是一个非常典型的问题。任何的异常用户,不仅仅是那些用于管理应用的设计糟糕的账号会有同样的问题;那些拥有大量好友、图片、状态、收藏的用户,也会有前面提到的系统账号同样的问题。下面s是一个真实案例,在一个用户分享购买商品和购买经验的论坛上,这个特殊表上的查询运行得非常慢:
sql
mysql> SELECT COUNT(DISTINCT threadId) AS COUNT_VALUE FROM Message
-> WHERE (groupId = 10137) AND (userId = 1288826) AND (anonymous = 0)
-> ORDER BY priority DESC, modifiedDate DESC
-> ;这个查询看似没有建立合适的索引,所以客户咨询是否可以优化。EXPLAIN的结果如下:
sql
id:1
select_type:SIMPLE
table:Message
type:ref
key:idx_groupId_userId
key_len:18
ref:const,const
rows:1251162
Extra:Using whereMySQL为这个查询选择了索引(groupId, userId),如果不考虑列的基数,这看起来是一个非常合理的选择。但如果考虑一下userID和groupID条件匹配的行数,可能就会有不同的想法了:
sql
mysql> SELECT COUNT(*) , SUM(groupId=10137), SUM(userId=1288826),SUM(anonymous = 0)
-> FROM Message\G
*************************** 1. row ***************************
COUNT(*):4142217
SUM(groupId=10137):4092654
SUM(userId=1288826):1288496
SUM(anonymous=0):4141934从上面的结果来看符合组(groupId)条件几乎满足表中的所有行,符合用户(userId)条件的有130弯条记录------也就是说索引基本上没什么用。因为这些数据是从其他应用中迁移过来的,迁移的时候把所有的消息都赋予了管理员组的用户。这个案例的解决办法是修改应用程序代码。去分这类特殊用户和组,禁止针对这类用户和组执行这个查询。从这个小案例可以看到经验法则和推论在多数情况下是有用的,但要注意不要假设平均情况下的性能也能代表特殊情况下的性能,特殊情况可能会摧毁整个应用的性能。最后,尽管关于选择性和基数的经验法则值得去研究和分析,但一定要记住别忘了WHERE子句中的排序、分组和范围条件等其他因素,这些因素可能对查询的性能造成非常大的影响。
聚簇索引
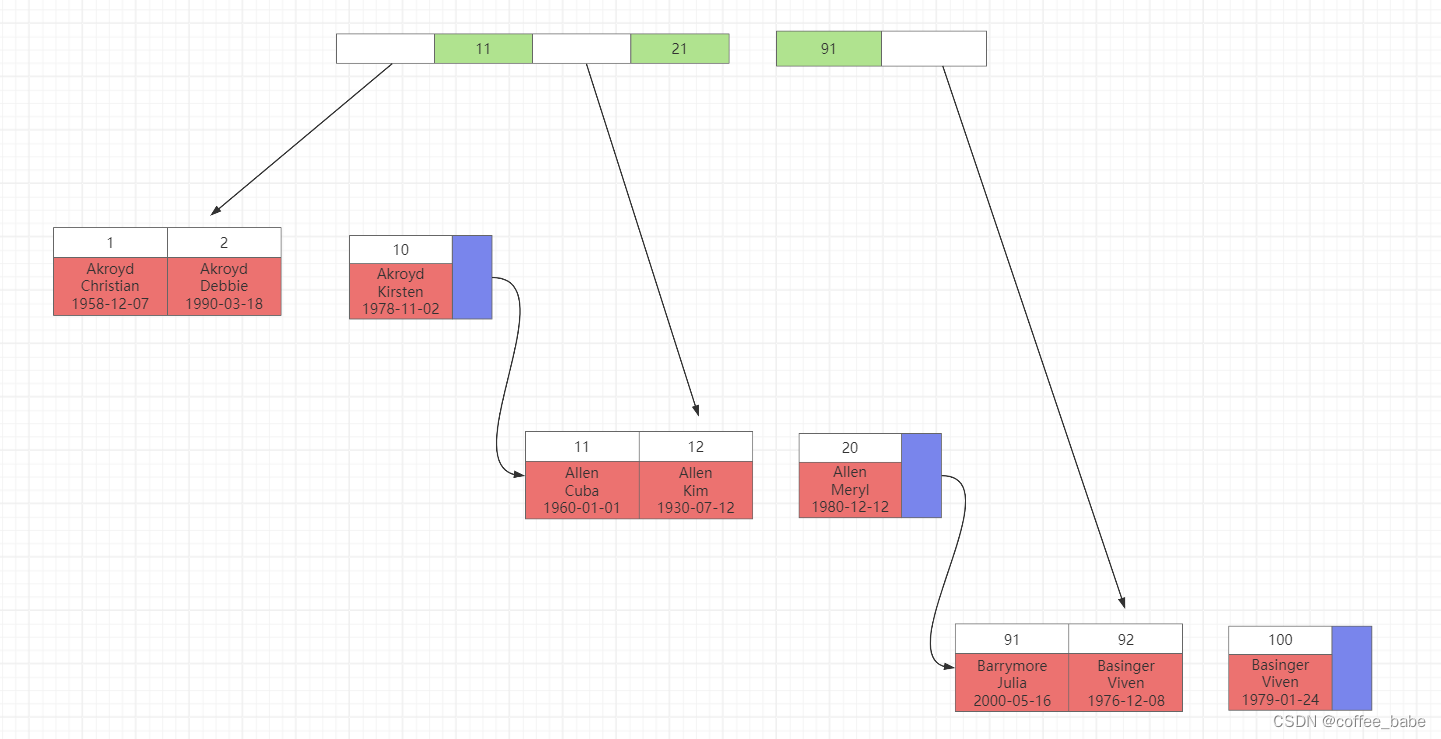
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。具体的细节依赖于其实现方式但InnoDB得聚簇索引实际上在同一个结构中保存了B-Tree索引和数据行。当表有聚簇索引时,它的数据行实际上存放在索引的叶子页(leaf page)中。术语"聚簇"表示数据行和相邻的键值紧凑地存储在一起。因为无法同时把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引(不过,覆盖索引可以模拟多个聚簇索引的情况)。因为是存储引擎负责实现索引,因此不是所有的存储引擎都支持聚簇索引。主要关注InnoDB.如图展示了聚簇索引中的记录是如何存放的。注意到,叶子页包含了行的全部数据,但是节点页只包含了索引列。该图中,索引包含的是整数值。
一些数据库服务器允许选择哪个索引作为聚簇索引,但是目前市场上,还没有任何一个MySQL内建的存储引擎支持这一点。InnoDB将通过主键聚集数据,这也就是说上图中的"被索引的列"就是主键列。如果没有定义主键,InnoDB会选择一个唯一的非空索引代替。如果没有这样的素银,InnoDB会隐式定义一个主键来作为聚簇索引,InnoDB只聚集在同一个页面中的记录。包含相邻键值的页面可能会相距甚远。
聚簇索引可能对性能有帮助,但也可能导致严重的性能问题。所以需要仔细地考虑聚簇素银,尤其是将表的存储引擎从InnoDB改成其他引擎的时候(反过来也一样)。聚集的数据有一些重要的优点:
- 1.可以把相关数据保存在一起。例如实现电子邮箱时,可以根据用户ID来聚集数据,这样只需要从磁盘读取少数的数据也就能获取某个用户的全部邮件。如果没有使用聚簇索引,则每封邮件都可能导致一次磁盘IO
- 2.数据访问更快。聚簇索引将索引和数据保存在同一个B-Tree中,因此聚簇索引中获取数据通常比在非聚簇索引中查找要快。
- 3.使用覆盖索引扫描的查询可以直接使用叶节点中的主键值
如果在设计表和查询时能充分利用上面的优点,那就能极大地提升性能。
同时,聚簇索引也有一些缺点:
- 1.聚簇数据最大限度地提高了IO密集型应用的性能,但入股哦数据全部都存放在内存中,则访问的顺序就没那么重要了,聚簇索引也就没什么优势了
- 2.插入速度严重依赖于插入顺序。按照主键的顺序插入是加载数据到InnoDB表中速度最快的方式。但如果不是按照主键顺序加载数据,那么在加载完成后最好使用OPTIMIZE TABLE命令重新组织一下表
- 3.更新聚簇索引列的代价很高,因为会强制InnoDB将每个被更新的行移动到新的位置
- 4.基于聚簇索引的表在插入新行,或者主键被更新导致需要移动行的时候,可能面临"页分裂(page split)"的问题。当行的主键值要求必须将这一行插入到某个已满的页中时,存储引擎会将该页分裂成两个页面来容纳该行,这就是一次页分裂操作。也分裂会导致表占用更多的磁盘空间
- 5.聚簇索引可能导致全表扫描变慢,尤其是行比较稀疏,或者由于页分裂导致数据存储不连续的时候
- 6.二级索引(非聚簇索引)可能比想象的要更大,因为在二级索引的叶子节点包含了引用行的主键列
- 7.二级索引访问需要两次索引查找,而不是一次
最后一点可能让人有些疑惑,为什么二级索引需要两次索引查找?答案在于二级索引中保存的"行指针"的实质。要记住,二级索引叶子节点保存的不是指向行的物理位置的指针,而是行的主键值。这意味着通过二级索引查找行,存储引擎需要找到二级索引的叶子节点获得对应的主键值,然后根据这个值去聚簇索引中查找到对应的行。这里做了重复的工作:两次B-Tree查找而不是一次(顺便提一下,并不是所有的非聚簇索引都能做到一次索引查询就找到行。当行更新的时候可能无法存储在原来的位置,这会导致表中出现行的碎片花或者移动行并在原位置保存"向前指针"。这两种情况都会导致查找行时需要更多的工作),对于InnoDB,自适应哈希索引能够减少这样的重复工作