1、Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
中文标题:Video-MME:视频分析领域首个多模态法学硕士综合评估基准
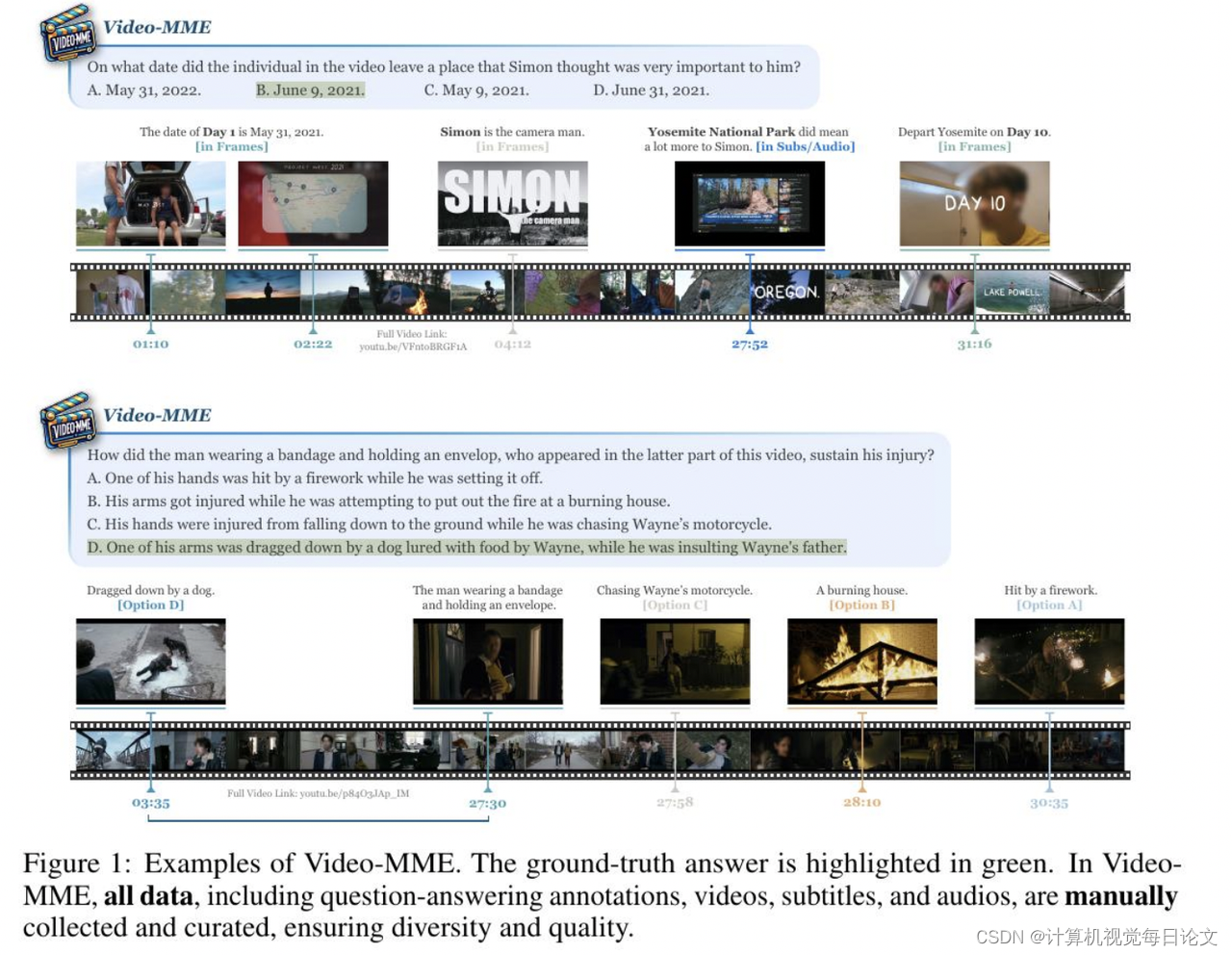
简介:Video-MME 是一个全面评估多模态大语言模型(MLLMs)在视频分析中性能的基准。它具有以下四个关键特点:
-
多样的视频类型:覆盖6个主要视觉领域和30个子领域,确保广泛的场景泛化性。
-
持续时间的时间维度:包括从11秒到1小时的短、中、长期视频,测试强大的上下文动态。
-
广泛的数据模态:除了视频帧,还整合了字幕和音频等多模态输入,以揭示MLLMs的全面能力。
-
高质量的注释:由专家注释员严格手动标注,确保精确可靠的模型评估。
Video-MME 汇总了900个视频,总共256小时,并生成了2700个问题-答案对。通过这个基准,研究者广泛评估了GPT-4、Gemini 1.5 Pro等先进的MLLMs,以及InternVL-Chat-V1.5和LLaVA-NeXT-Video等开源模型。实验发现,Gemini 1.5 Pro是表现最佳的商业模型,但仍存在处理长序列和多模态数据的必要性。Video-MME 项目页面: https://video-mme.github.io。
2、Latent Intrinsics Emerge from Training to Relight
中文标题:潜在的内在本质从训练中显现出来,以重新打光

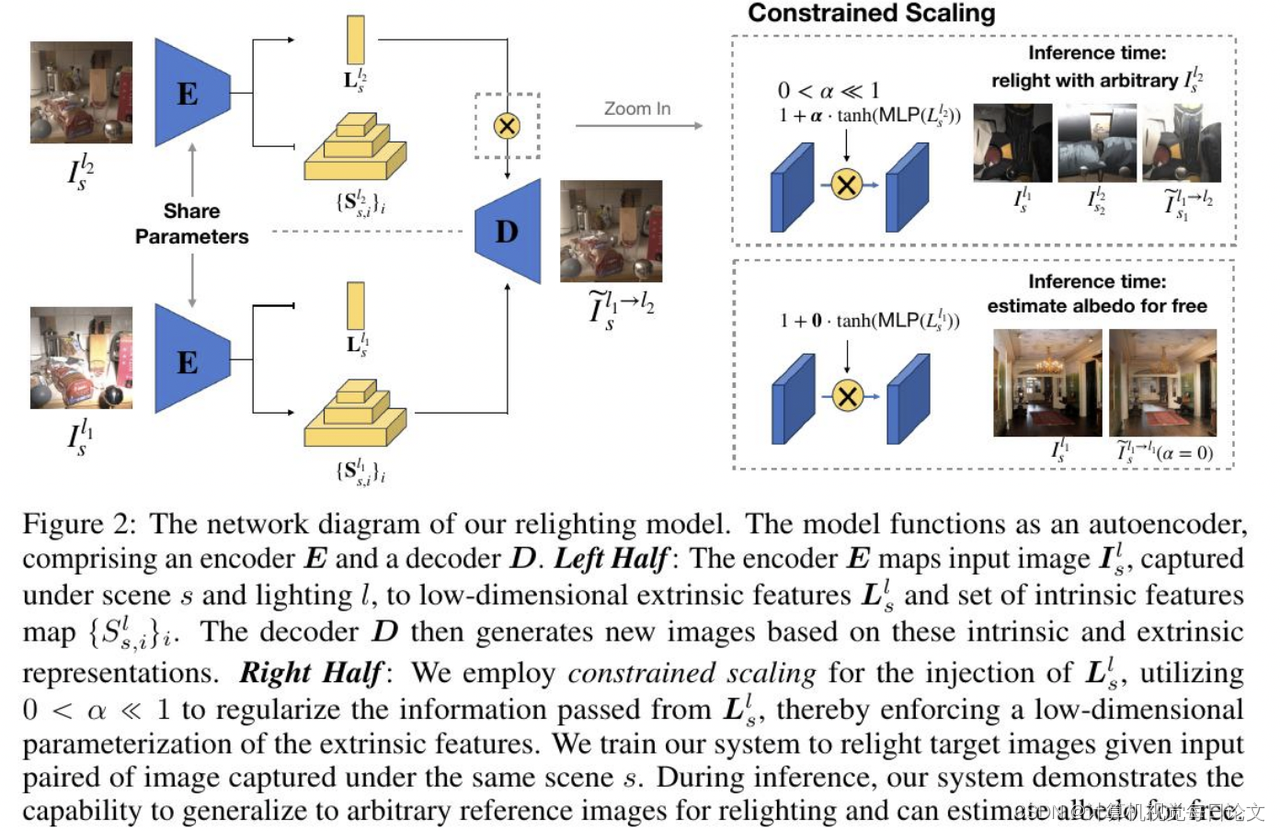
简介:这篇论文介绍了一种全新的数据驱动的图像照明方法。与传统的基于逆向图形的方法不同,本文提出的方法将场景的内在特征和照明分别建模为潜在变量。这种方法避免了逆向图形方法中难以控制误差的问题,同时也不局限于表示预先选择的内在特征。
通过这种潜在变量建模的方法,我们生成了最先进的实景照明效果,在标准评价指标上表现优秀。我们还展示了这种方法可以从图像中恢复出反照率信息,而无需任何反照率样例,其恢复效果也与目前最好的方法相当。
总的来说,这种全新的数据驱动图像照明方法,克服了传统逆向图形方法的局限性,展现出更强大的建模能力,为图像照明问题带来了新的解决思路。
3、Generalization Beyond Data Imbalance: A Controlled Study on CLIP for Transferable Insights
中文标题:超越数据不平衡的泛化:针对可转移见解的 CLIP 的对照研究
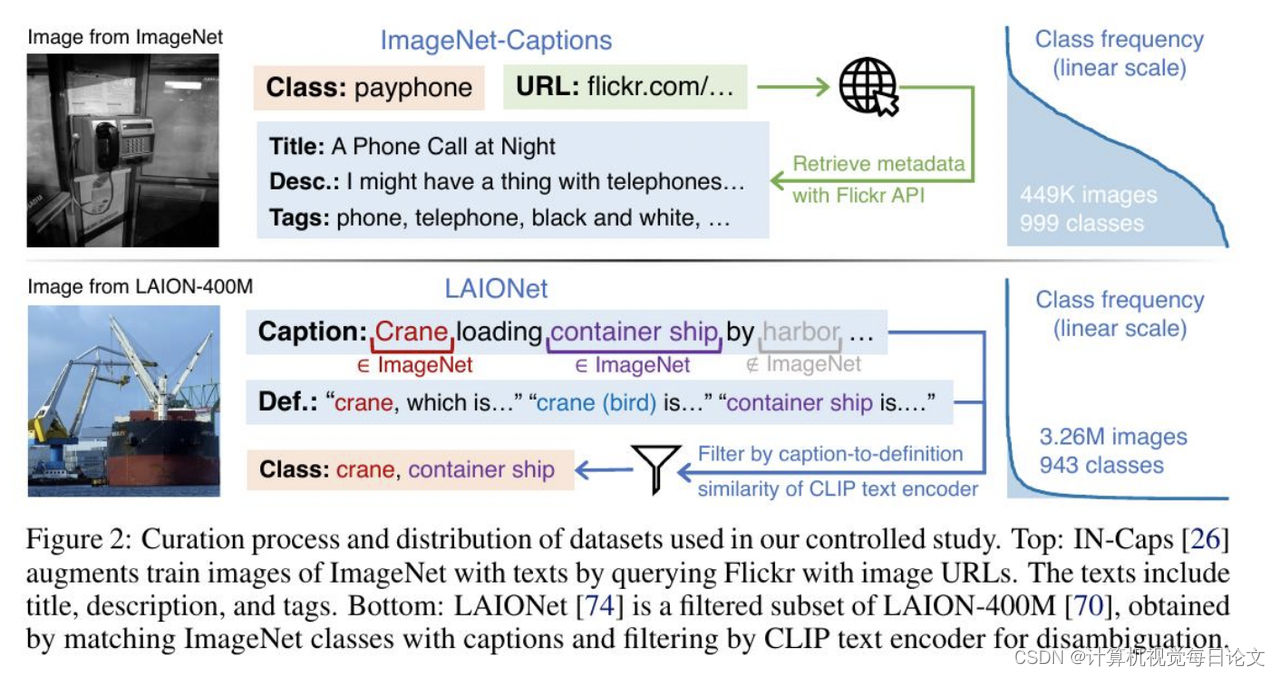
简介:这篇论文探讨了在大规模视觉-语言数据集上进行CLIP预训练的数据不平衡问题。研究发现,与传统监督学习相比,CLIP预训练在学习可推广的表示方面表现出了显著的数据平衡鲁棒性。
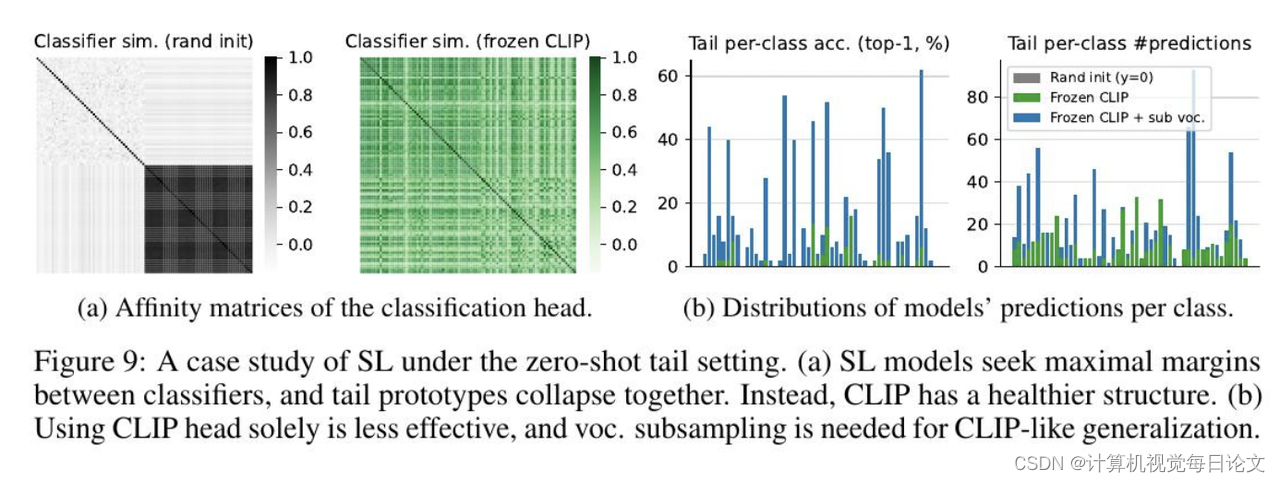
为了深入理解这一现象背后的原因,作者进行了一系列受控实验,发现CLIP的伪任务形成了动态分类问题,其中训练集中只有一部分类别。这种设置隔离了主导类别的偏见,隐含地平衡了学习信号。此外,CLIP的鲁棒性和可区分性还受益于更具描述性的语言监督、更大规模的数据以及更广泛的开放世界概念,这些是传统监督学习无法访问的。
这些发现不仅揭示了CLIP在数据不平衡情况下推广性的机制,还为其他监督学习和自监督学习模型在不平衡数据上的训练提供了可转移的见解,使其能够达到CLIP级别的性能。相关代码已公开在 https://github.com/CVMI-Lab/clip-beyond-tail。