引入
spark和flink的区别:在上一个spark专栏中我们了解了spark对数据的处理方式,在 Spark 生态体系中,对于批处理和流处理采用了不同的技术框架,批处理由 Spark-core,SparkSQL 实现,流处理由 Spark Streaming 实现,但是Flink 可以用同一套代码同时实现批处理和流处理。
虽然spark和flink都可以进行批处理和流处理,但是侧重点不同,spark侧重于批处理,flink侧重于流处理。而且Spark Streaming准确来说并不是严格意义上的实时,它本质上还是一种微批处理 的结构,用近实时描述更准确,所以使用Spark Streaming来做实时计算会发现延时很高。这也是会出现flink去代替Spark Streaming完成实时计算的原因之一。
一、离线和实时的区别
首先要明确一个概念,离线计算也叫做批量处理,实时计算也叫做流式处理,都是同一种东西,只是叫法不同。
1、离线(批处理)和实时(流处理)的区别:
 批处理的特点是有界、大量,批处理非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。流处理的特点是无界、实时,流处理方式无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
批处理的特点是有界、大量,批处理非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。流处理的特点是无界、实时,流处理方式无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
二、主流实时计算框架对比
**声明式:**描述所需的数据转换和输出,而框架负责如何实现这些转换。它更加关注于"做什么",而不是"如何做"。
**组合式:**开通过编写具体的指令来控制数据的流动和处理。
三、Spark Streaming微批处理 与Flink流式处理对比
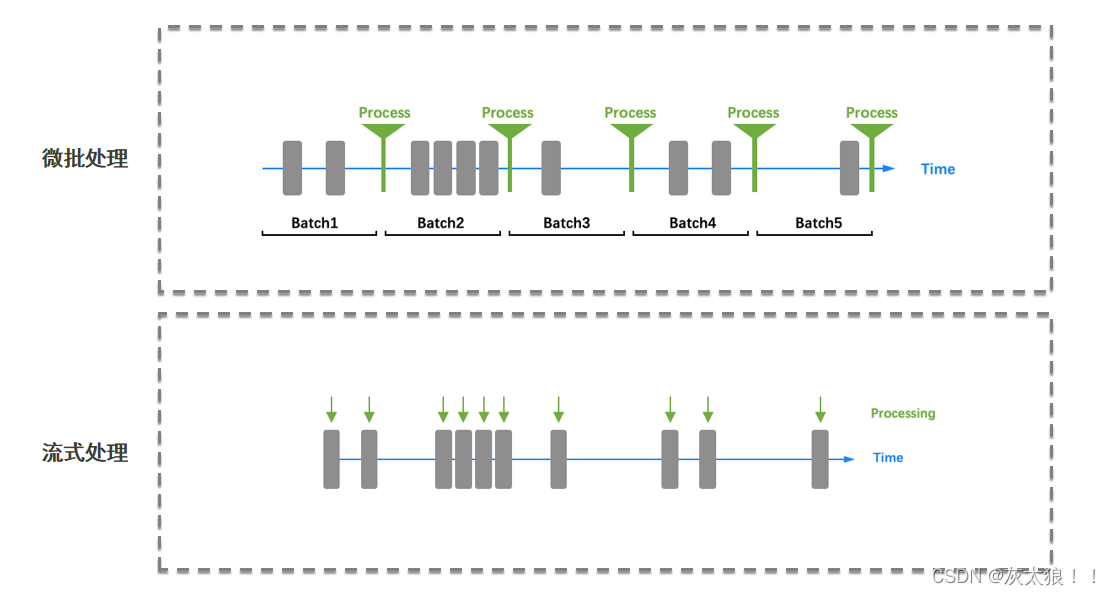
从上图我们就可以看出Spark Streaming处理的方式是每隔一段时间,将该段时间产生的所有数据集中起来一起处理,而Flink流式处理是将数据产生一条就处理一条,这也是flink实时处理延迟低的原因。
四、Apache Flink简介
1、概述
Apache Flink 是一个实时计算 框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
2、Flink特性

十大特性:

3、Apache Flink组件栈

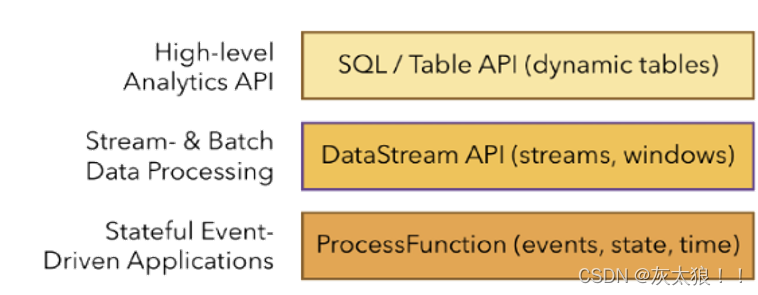
4、Flink API 层级具体划分
---------------------------------------------------------------------------------------------------------------------------------简要的介绍到这里结束,下一篇文章开始正式的学习。下面写一个简单的入门案例配上图解,便于对flink的理解。
五、入门案例(WordCount)
1、单词统计案例1(流处理/实时)
java
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Demo1StreamWordCount {
public static void main(String[] args) throws Exception {
//1、获取flink执行环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
//设置任务的并行度,一个并行度相当于一个task
environment.setParallelism(2);
//设置数据从上游发送到下游的延迟时间,也可以不设置,默认延迟为200ms
/*
(1)一个正整数会根据该整数周期性地触发刷新
(2)0在每条记录后触发刷新,从而最大限度地减少延迟
(3)-1只在输出缓冲区已满时触发刷新,从而最大限度地提高吞吐量
*/
environment.setBufferTimeout(200);
//2、读取数据
//在命令行执行nc -lk 8888来模拟实时数据生成
DataStream<String> wordDS = environment.socketTextStream("master", 8888);
//3、统计单词数量
DataStream<Tuple2<String, Integer>> wordKVDS = wordDS.map(
word->Tuple2.of(word,1), Types.TUPLE(Types.STRING,Types.INT)
);
//3、1分组统计单词的数量
KeyedStream<Tuple2<String, Integer>, String> wordKeyBY = wordKVDS.keyBy(kv -> kv.f0);
//3.2对下标为1的列求和
DataStream<Tuple2<String, Integer>> wordCounts = wordKeyBY.sum(1);
//打印数据
wordCounts.print();
//启动flink
environment.execute();
}
}运行结果:

代码流程图解:

2、单词统计案例2(批处理/离线)
java
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Demo2BatchWorldCounr {
public static void main(String[] args) throws Exception {
//1、创建Flink运行环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
/*
*处理模式:
* RuntimeExecutionMode.BATCH:批处理模式(MapReduce模型)
* 1、输出最终结果
* 2、批处理模式只能用于处理有界流
*
* RuntimeExecutionMode.STREAMING:流处理模式(持续型模型)
* 1、输出连续结果(换句话说就是会不断输出中间结果)
* 2、流处理模式,有界流和无界流都可以处理
*/
//设置处理模式,如果不设置,默认是流处理模式
environment.setRuntimeMode(RuntimeExecutionMode.BATCH);
//2、读取文件(有向流)
DataStream<String> wordDs = environment.readTextFile("flink/data/words.txt");
//3、统计单词数量
DataStream<Tuple2<String, Integer>> kvDS = wordDs.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT));
//3.1分组统计单词数量
KeyedStream<Tuple2<String, Integer>, String> keyBy = kvDS.keyBy(kv -> kv.f0);
//3.2对下标为1的列求和
DataStream<Tuple2<String, Integer>> wordCounts = keyBy.sum(1);
//打印数据
wordCounts.print();
//启动flink
environment.execute();
}
}运行结果:
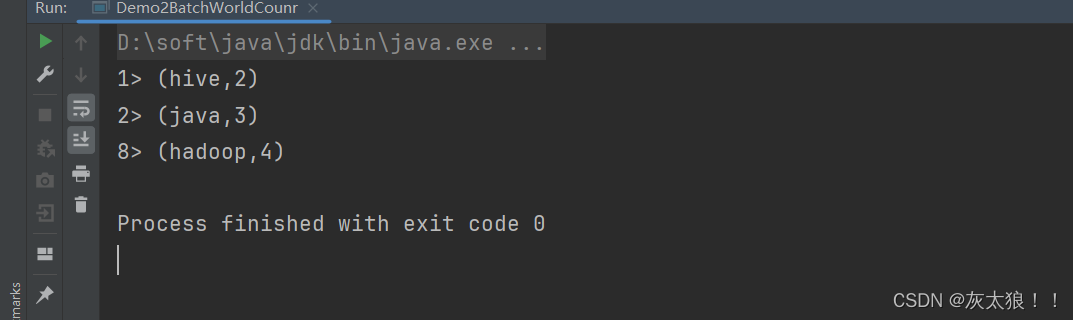
注意:在引入便提到过,上述两个案例用的都是同一套代码,flink能够使用同一套代码执行流处理和批处理,完成了流批统一(批流一体)。