Codeforces Round 950 (Div. 3)A、B题解

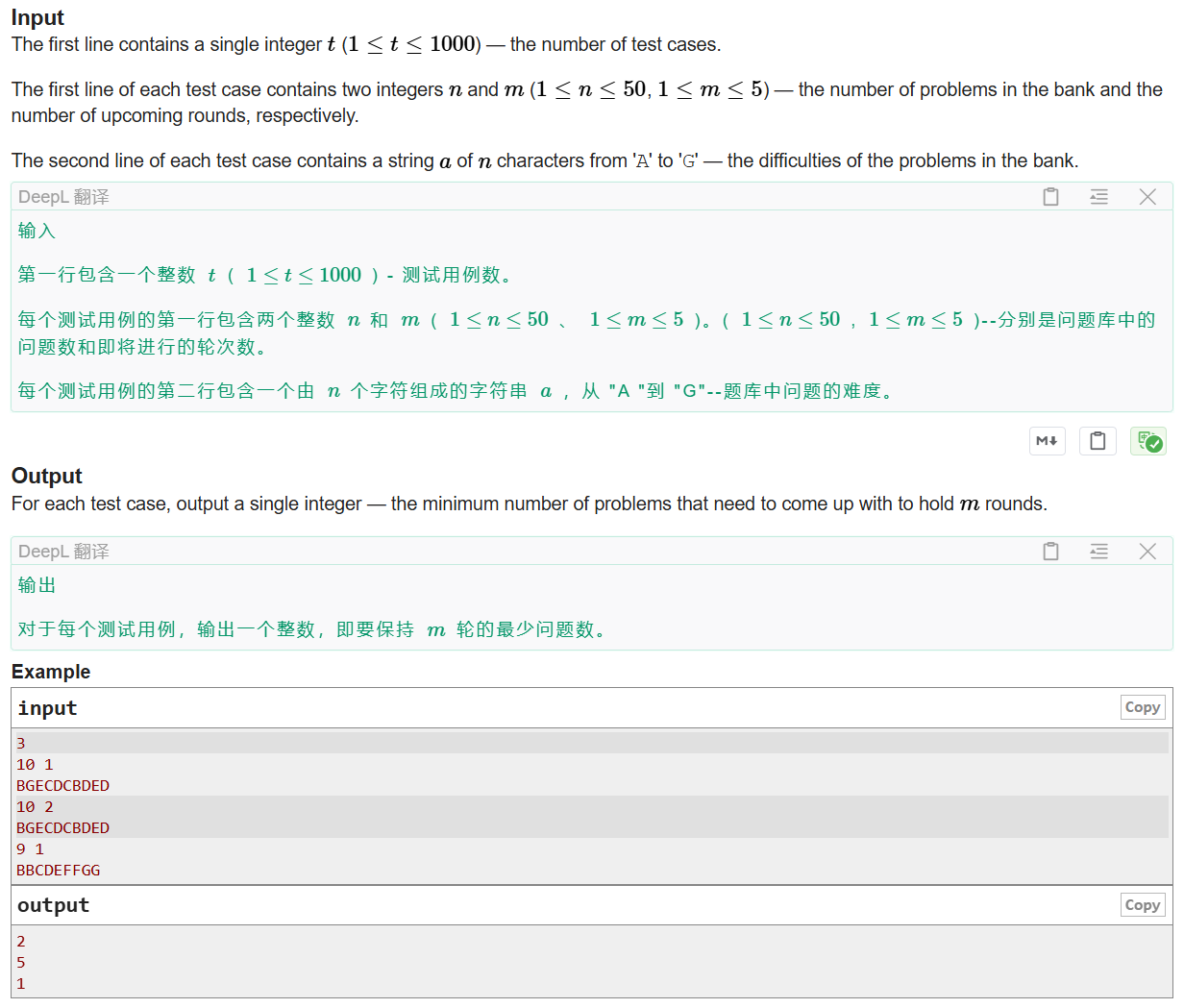
解题思路
开一个数组来记录A,B,C,D,E,F,G难度题目出现的次数,因为每一轮比赛都需要每一种难度都有一题,所以我们只要根据要出的比赛的轮数对每一个难度的题目进行自减,最后遍历数组把所有为负数的题目的数量记录下来就是需要出的题目的数量了。
代码
#include <iostream>
#include <cstdio>
#include <fstream>
#include <algorithm>
#include <cmath>
#include <deque>
#include <vector>
#include <queue>
#include <string>
#include <cstring>
#include <map>
#include <stack>
#include <set>
using namespace std;
int main()
{
int t,n,m;
char a[100];
int b[10];
scanf("%d",&t);
for(int i=0;i<t;i++)
{
int sum=0;
scanf("%d%d",&n,&m);
for(int x=0;x<7;x++)
{
b[x]=0;
}
for(int x=0;x<n;x++)
{
cin>>a[x];
b[a[x]-'A']++;
}
for(int x=0;x<7;x++)
{
b[x]-=m;
if(b[x]<0)
{
sum-=b[x];
}
}
printf("%d\n",sum);
}
return 0;
}


解题思路
用一个数组来保存正方体的顺序,记录魔方的值,然后对数组进行排序。应为如果两个立方体的数值相同,它们可以按照任意顺序排列所以我们不需要找到魔方的位置,只需要找到与魔方有着相同的值的立方体(应为魔方可能出现在任何与魔方有着相同的值的立方体的位置),然后对所有的与魔方有着相同的值的立方体的位置进行判断看是否有可能被丢掉(一定、有可能、不可能)。
代码
#include <iostream>
#include <cstdio>
#include <fstream>
#include <algorithm>
#include <cmath>
#include <deque>
#include <vector>
#include <queue>
#include <string>
#include <cstring>
#include <map>
#include <stack>
#include <set>
using namespace std;
int cmp(int x,int y)
{
return x>y;
}
int main()
{
int t,n,f,k;
scanf("%d",&t);
for(int i=0;i<t;i++)
{
int a[105]={0};
scanf("%d%d%d",&n,&f,&k);
for(int x=0;x<n;x++)
{
scanf("%d",&a[x]);
}
f=a[f-1];
sort(a,a+n,cmp);
int g=0;
while(g<=n&&a[g]!=f)
{
g++;
}
int y=g;
int flat=0,flat1=0;
while(a[y]==f&&y>=0)
{
if(y<k)
{
flat=1;
break;
}
y--;
}
if(!flat)
{
printf("NO\n");
continue;
}
y=g;
while(a[y]==f&&y<n)
{
if(y>=k)
{
flat1=1;
break;
}
y++;
}
if(flat1)
{
printf("MAYBE\n");
}
else
{
printf("YES\n");
}
}
return 0;
}Mysql学习总结
联结(补)
表别名
别名不只是可以给列和计算字段使用,还可以给表使用,这样用有两个好处:
- 缩短SQL语句
- 允许在单条SELECT语句中多次使用相同的表。
SELECT cust_name, cust_contact
FROM customers AS c, orders AS o, orderitems AS oi
WHERE c.cust_id = o.cust_id
AND oi.order_num = o.order_num
AND prod_id = 'TNT2';
自联结
例:如果某物品(ID为DTNTR)存在问题,因此想知道生产该物品的供应商生产的其他物品是否也存在这些问题。此查询要求首先找到ID为DTNTR的物品的供应商,然后找出这个供应商生产的其他物品。
SELECT p1.prod_id, p1.prod_name
FROM products AS p1, products AS p2
WHERE p1.vend_id = p2.vend_id AND p2.prod_id ='DTNTR';
组合查询
执行多个查询并将结果作为单个查询结果返回。
使用情况:
- 在单个查询中从不同的表返回类似结构的数据
- 对单个表执行多个查询,按单个查询返回数据
UNION关键字
只需要把给出的每一条select语句之间用union关键字连接就行了。
#单条语句
SELECT vend_id, prod_id, prod_price
FROM products
WHERE prod_price <= 5;
SELECT vend_id, prod_id, prod_price
FROM products
WHERE vend_id IN (1001,1002);
#组合上述语句
SELECT vend_id, prod_id, prod_price
FROM products
WHERE prod_price <= 5
UNION
SELECT vend_id, prod_id, prod_price
FROM products
WHERE vend_id IN (1001, 1002);
#等于
SELECT vend_id, prod_id, prod_price
FROM products
WHERE prod_price <= 5
OR vend_id IN (1001, 1002);
union使用须知
- union必须由两条或两条以上的select语句组成,语句之间用关键字union分隔。
- 所有的查询必须有着相同的语句结构(列数相同)
- 所有的查询的列的数据类型要相同(实际上只要列的数据类型兼容就行了例如整形和浮点型时相互兼容的)。
- union会自动的从查找到的结果集中去除相同的行,如果要显示搜索到的所有行需要使用 union all关键字。
- 如果使用order by关键字进行排序,那么只能使用一次,要放在最后的一条select语句中。
全文本搜索
全文本搜索是指在数据库中查找包含特定关键词或短语的文本的过程 。它与传统的基于精确匹配的搜索不同,全文本搜索允许进行模糊匹配 和部分匹配,以便找到与搜索条件相关的文本。
并非所有的引擎都是支持全文本搜索的,所以如要使用全文本搜索最好在使用之前了解一下使用的引擎是否支持全文本搜索。Mysql常用的两个引擎innodb和Myisam都是支持全文本搜索的,如果要对中文进行搜索还需要进一步的了解。
like关键字和正则表达式的限制
- 搜索花费的时间多。(因为搜索时会遍历整个数据表对每一个数据进行对比)
- 无法明确的控制匹配的条件。(当对搜索数据的要求多起来,就会很难被实现。例:指定一个词不允许匹配,另一个词必须匹配,而第二个词必须在第一个词的匹配条件成立之后才生效)。
- 没有提供一种智能化的选择结果的方法。(例如,一个特殊词的搜索将会返回包含该词的所有行,而不区分包含单个匹配的行和包含多个匹配的行(按照可能是更好的匹配来排列它们)。类似,一个特殊词的搜索将不会找出不包含该词但包含其他相关词的行。)
而以上这些缺陷甚至更多都可以通过全文本来避免。
使用全文本搜索的准备
为了进行全文本搜索,必须索引被搜索的列,而且要随着数据的改变不断地重新索引。在对表列进行适当设计后,MySQL会自动进行所有的索引和重新索引。
在索引之后,SELECT可与Match()和Against()一起使用以实际执行搜索。
启用全文本搜索
一般在创建表的时候就启用。
CREATE TABLE语句接收FULLTEXT子句,它需要被索引列的使用逗号分隔的列表(当fulltext语句中有多个列时使用逗号隔开)。
CREATE TABLE productnotes //创建一个表
(
note_id int NOT NULL AUTO_INCREMENT, //创建一个int型的列,不能为空,会自动递增
pord_id char(10) NOT NULL,
note_date datetime NOT NULL.
note_text text NULL,
PRIMARY KEY(note_id), //设置主键
FULLTEXT(note_text) //启用note_text列的全文本搜索功能
)ENGINE=MyISAM; //指定储存引擎为MyISAM
如果正在导入数据到一个新表,此时不应该启用 FULLTEXT 索引。应该首先导入所有数据,然后再修改表,定义 FULLTEXT 。这样有助于更快地导入数据(使索引数据的总时间小于在导入每行时分别进行索引所需的总时间。
进行全文本搜索
match():指定要搜索的列。(match()中的参数必须和fulltext()中的参数保持一致)
against():指定要搜索的表达式。
如想区分大小写使用binary关键字。
例:
SELECT note_text,
Match(note_text) Against('rabbit') AS rank
FROM productnotes;
SELECT note_text AS rank
FROM productnotes
WHERE note_text like 'rabbit';
这两段代码的区别就是:使用全文本搜索的根据搜索词出现的次数自动的进行排序,而like关键字则不会。
扩展搜索
全文本搜索还提供了扩展搜索的功能,也就是说它不仅仅局限于你给出的来进行搜索,还会根据你给出的词对相关的词进行扩展搜索,比如你要搜索apple,他会帮你扩展搜索tree、fruit等。
需要使用时需要在against()中加上with query expansion就行了。
例:
SELECT note_text,
Match(note_text) Against('rabbit'WITH QUERY EXPANSION) AS rank
FROM productnotes;