前言
Redis 的主从复制模式下,⼀旦主节点由于故障不能提供服务,需要⼈⼯进⾏主从切换,同时⼤量的客户端需要被通知切换到新的主节点上,对于上了⼀定规模的应⽤来说,这种⽅案是⽆法接受的, 于是 Redis 从 2.8 开始提供了 **Redis Sentinel(哨兵)**来解决这个问题。
也就是说 Redis 哨兵(Sentinel)的核心就是当 Redus 主节点出现故障时能够自动恢复(选取一个子节点作为新的主节点)
Redis Sentinel 相关名词解释

Redis Sentinel 是 Redis 的⾼可⽤实现⽅案,在实际的⽣产环境中,对提⾼整个系统的⾼可⽤是⾮常有帮助的
主从复制的问题
关于 Redis 主从复制的细节推荐看Redis 主从复制
Redis 的主从复制模式可以将主节点的数据改变同步给从节点,这样从节点就可以起到两个作⽤:
第⼀,作为主节点的⼀个备份,提高主节点的可用性,⼀旦主节点出了故障,从节点可以作为后备 "顶" 上 来,并且保证数据尽量不丢失(主从复制表现为最终⼀致性)。
第⼆,从节点可以分担主节点上的读压⼒,让主节点只承担写请求的处理,将所有的读请求负载均衡到各个从节点上。
但是主从复制模式并不是万能的,它遗留下以下⼏个问题:
-
主节点发⽣故障时,进⾏主备切换的过程是复杂的,需要完全的**⼈⼯参与**(人工是最不靠谱的,靠人工相当于必定出意外),导致故障恢复时间⽆法保障。
-
主节点可以将读压⼒分散出去,但写压⼒/存储压⼒是⽆法被分担的,主节点还是性能瓶颈。
其中第⼀个问题是⾼可⽤问题,即 Redis 哨兵主要解决的问题。第⼆个问题是属于存储分布式的问题,留给 Redis 集群去解决
⼈⼯恢复主节点故障
Redis 主从复制模式下,主节点故障后需要进⾏的**⼈⼯⼯作是⽐较繁琐**的,我们在图中⼤致展示了整体过程。
Redis 主节点故障后需要进行的操作
1)运维⼈员通过监控系统,发现 Redis 主节点故障宕机。
2)运维⼈员从所有从节点中,选择⼀个从节点执⾏ slaveof no one(断开主从关系),使其作为新的主节点。
3)运维⼈员让剩余从节点执⾏ slaveof {newMasterIp} {newMasterPort} 与新主节点建立主从关系。
4)更新应⽤⽅(连接 redis 的客户端)连接的主节点信息到 {newMasterIp} {newMasterPort}。
5)如果原来的主节点恢复,执⾏ slaveof {newMasterIp} {newMasterPort}(与新主节点建立主从关系) 让其成为⼀个从节点。
上述过程可以看到基本需要**⼈⼯介⼊,⽆法被认为架构是⾼可⽤的。⽽这就是Redis Sentinel** 所要做的。
哨兵自动恢复主节点故障
当主节点出现故障时,Redis Sentinel能⾃动完成故障发现和故障转移,并通知应⽤⽅(主节点发生改变),从⽽实现真正的⾼可⽤。
Redis Sentinel 是⼀个分布式架构,其中包含若⼲个 Sentinel 节点和 Redis 数据节点,每个 Sentinel 节点会对所有数据节点和其余 Sentinel 节点进⾏监控,当它发现节点故障时,会对节点做下线操作。
如果下线的是主节点,它还会和其他的 Sentinel 节点进⾏"协商",当⼤多数 Sentinel 节点对 主节点不可达这个结论达成共识之后,它们会在内部"选举"出⼀个代表节点来完成恢复主节点的工作,同时将这个变化实时通知给所有 Redis 应⽤⽅。
为什么要大多数 Sentinel 节点达成共识才能下线主节点
这是为了避免出现"误判",因为哨兵节点可能会因为自己的网络波动导致没有收到主节点的心跳回应,就误判主节点故障,所以只有大部分哨兵节点都认为主节点故障才能确定主节点故障,下架主节点。
Redis Sentinel 架构
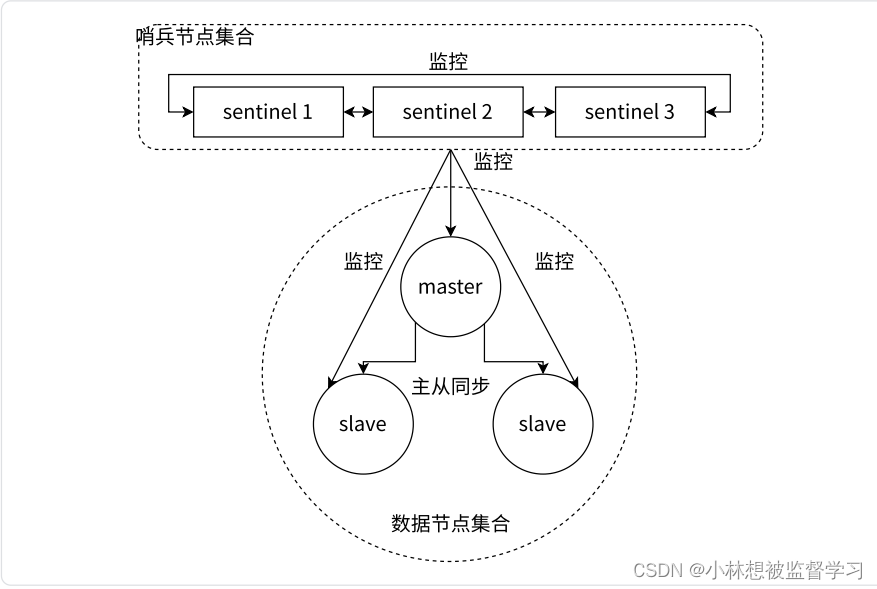
Redis Sentinel 相⽐于主从复制模式是多了若⼲(建议保持奇数)Sentinel 节点⽤于实现监控数据节点,哨兵节点会定期监控所有节点(包含数据节点和其他哨兵节点)。
针对主节点故障的情况,故障转移流程⼤致如下:
1)主节点故障,从节点同步连接中断,主从复制停⽌。
2)哨兵节点通过定期监控发现主节点出现故障。哨兵节点与其他哨兵节点进⾏协商,如果多数认同主节点发生故障,则确定主节点故障。这步主要是防⽌该情况:出故障的不是主节点,⽽是发现故障的哨兵节点,该情况 经常发⽣于哨兵节点的⽹络有波动的场景下。
3)哨兵节点之间使⽤ Raft 算法选举出⼀个代表⻆⾊,由该节点负责后续的故障转移⼯作。
4)哨兵代表开始执⾏故障转移:在从节点中选择⼀个作为新主节点;让其他从节点与新主节点建立主从关系;通知应⽤层转移到新主节点。

通过上⾯的介绍,可以看出Redis Sentinel具有以下⼏个功能:
• 监控: Sentinel 节点会定期检测 Redis 数据节点、其余哨兵节点是否可达。
• 故障转移:实现从节点晋升(promotion)为主节点并维护后续正确的主从关系。
• 通知: Sentinel 节点会将故障转移的结果通知给应⽤⽅。
为什么哨兵节点最好保持奇数
因为在下线主节点时会根据算法从内部选取一个哨兵节点来进行处理,而这个算法在总数为奇数的哨兵节点中选取时效率更高。
但哨兵节点只有一个显然也是不行的,因为要考虑哨兵节点的可用性,要是只有一个哨兵节点,这个哨兵节点挂了就无法再提供服务了,而且用一个哨兵节点来判断主节点是否出现故障可靠性也不高,所以哨兵节点一般是 3个。
安装部署(基于 docker )
简单介绍 docker
我们进行 Redis 哨兵的部署练习,大致结构如下:

要是在真实的项目场景中,上图的 6 个节点应该部署在 6 个服务器上,但因为经济原因,目前只能将它们都部署在一个服务器上,但多个哨兵节点之间以及多个 Redis 数据节点之间会出现很多的配置,环境冲突问题,解决起来比较头疼。而且一个节点一个节点的去部署显然也过于麻烦,而通过 docker就可以解决节点之间的环境冲突问题,通过 docker-compose 就可以实现快速部署和管理。
docker
docker 是一个"容器",可以看作一个轻量级的虚拟机,在 docker 中部署的程序与外界隔离,拥有自己的环境,可以很好的解决环境冲突问题。
通过 Redis 镜像创建一个 docker 容器就可以快速的搭建好一个 Redis 服务器。
docker 中的"镜像"和"容器"类似于"可执行程序"和"进程"的关系。镜像可以自己构建也可以拿别人已经构建好的,docker hub 上就包含了许多大佬构建好的镜像,
docker-compose
通过 docker 可以快速的搭建一个节点,但目前我们有 6 个节点需要搭建,一个个搭建太麻烦了,可以使用 docker-compose 来进行容器编排,就可以快速的搭建和管理节点。
docker-compose 通过一个配置文件****(使用 yml 这样的格式来作为配置文件) ,把具体要创建哪些容器,每个容器运行的各种参数描述清楚,后续通过一个简单的命令就可以批量的启动/停止这些容器了。
安装 docker 和 docker-compose
部署
使⽤ docker 获取 redis 镜像
docker pull redis:5.0.9查看已有的镜像
docker images
编排 redis 主从节点
编写docker-compose.yml配置文件
docker-compose 会根据配置文件来快速的搭建和管理节点。
注意:docker-compose 的配置文件名固定是 docker-compose.yml,不能被修改为其他的。
docker-compose.yml的文件内容:
version: '3.7'
services:
master:
image: 'redis:5.0.9'
container_name: redis-master
restart: always
command: redis-server --appendonly yes
ports:
- 6379:6379
slave1:
image: 'redis:5.0.9'
container_name: redis-slave1
restart: always
command: redis-server --appendonly yes --slaveof redis-master 6379
ports:
- 6380:6379
slave2:
image: 'redis:5.0.9'
container_name: redis-slave2
restart: always
command: redis-server --appendonly yes --slaveof redis-master 6379
ports:
- 6381:6379- version: '3.7' 这指定了Docker Compose文件的版本为 3.7。确保您的 Docker Compose 工具支持这个版本。
- services`键下定义了你希望 Docker Compose 启动的容器服务。
- master,slave1,slave2 是 services 名字,是自己设定的。
- image: 'redis:5.0.9' 指定了使用
redis:5.0.9这个Docker镜像。这个镜像包含了 Redis 5.0.9 版本的服务器。 - container_name: redis-master 设置了容器的名称为
redis-master。如果您不指定这个,Docker Compose 会为您自动生成一个名称。 - restart: always 设置容器的重启策略为
always,这意味着如果容器因为某种原因退出,Docker Compose 会尝试重新启动它。 - command: redis-server --appendonly yes 覆盖了默认启动命令,为Redis服务器指定了额外的参数
--appendonly yes,这告诉Redis服务器启用 AOF(Append-Only File)持久化模式。 - ports:
- 6379:6379 定义了端口映射。它将宿主机的
6379端口映射到容器的6379端口。这样,您就可以通过宿主机的6379端口来访问Redis服务器了。
- 6379:6379 定义了端口映射。它将宿主机的
注意:.yml 文化对于格式十分严格,如果格式不对就会报错
启动所有容器
在包含 docker-compose.yml 配置文件的目录中执行下面的命令启动配置文件中定义的所有容器:
docker-compose up -d
查看运⾏⽇志
docker-compose logs
上述命令必须保证⼯作⽬录在 .yml 配置文件的同级⽬录中,才能⼯作.
编排 redis-sentinel 节点
可以把 redis-sentinel 放到和上⾯的 redis 的同⼀个 yml 中进⾏容器编排.此处分成两组,主要是为了两⽅⾯:
• 观察⽇志⽅便
• 确保 redis 主从节点启动之后才启动 redis-sentinel. 如果先启动 redis-sentinel 的话, 可能触发额外的选举过程,混淆视听.(不是说先启动哨兵不⾏,⽽是观察的结果可能存在⼀定随机性).
编写 docker-compose.yml 配置文件
version: '3.7'
services:
sentinel1:
image: 'redis:5.0.9'
container_name: redis-sentinel-1
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel1.conf:/etc/redis/sentinel.conf
ports:
- 26379:26379
sentinel2:
image: 'redis:5.0.9'
container_name: redis-sentinel-2
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel2.conf:/etc/redis/sentinel.conf
ports:
- 26380:26379
sentinel3:
image: 'redis:5.0.9'
container_name: redis-sentinel-3
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel3.conf:/etc/redis/sentinel.conf
ports:
- 26381:26379与编排 Redis 主从节点只多了 volumes 配置,这里只解释该配置
volumes:
- ./sentinel1.conf:/etc/redis/sentinel.conf 这将当前目录下的
sentinel1.conf文件映射到容器内的/etc/redis/sentinel.conf路径。这样,容器就可以使用宿主机上的配置文件了。
编写 redis-sentinel 的配置文件
每个哨兵的配置文件一开始是相同的,但随着哨兵的运行,配置文件中会有不同的内容添加进去,所以每个哨兵都要有一个配置文件。
sentinel1.conf
bind 0.0.0.0
port 26379
sentinel monitor redis-master redis-master 6379 2
sentinel down-after-milliseconds redis-master 1000- bind 0.0.0.0 这告诉 Redis Sentinel 绑定到所有可用的网络接口(即所有IP地址)
- port 是 sentinel 在 docker 容器中绑定的端口号
- sentinel monitor redis-master redis-master 6379 2 告诉哨兵节点,它需要监控哪个 redis 服务器,第一个 redis-master 是服务器名称,第二个 redis-master 是 IP 地址,不过通过 docker 部署的服务器 IP 地址是由 docker 分配的,这里输人容器名称,docker 会自动进行域名解析得到 IP 地址,6379是 redis 服务器在宿主机中对应的端口号,2代表法定票数,说明当两个哨兵节点都觉得 redis 节点出现故障,才能真正确定 redis 节点故障
- sentinel down-after-milliseconds redis-master 1000 心跳包的超时时间,单位是毫秒,表示当 redis 节点 1000毫秒内没有回应哨兵节点,就判定 redis 节点出现故障
另外两个哨兵节点的 sentinel2.conf ,sentinel3.conf 配置文件直接复制 sentinel1.conf 配置文件即可。
cp ./sentinel1.conf sentinel2.conf
cp ./sentinel1.conf sentinel3.conf启动所有容器
docker-compose up -d
如果启动后发现前⾯的配置有误,需要重新操作,使⽤ docker-compose down即可停⽌并删除刚才创建好的容器.
docker-compose down查看运⾏⽇志
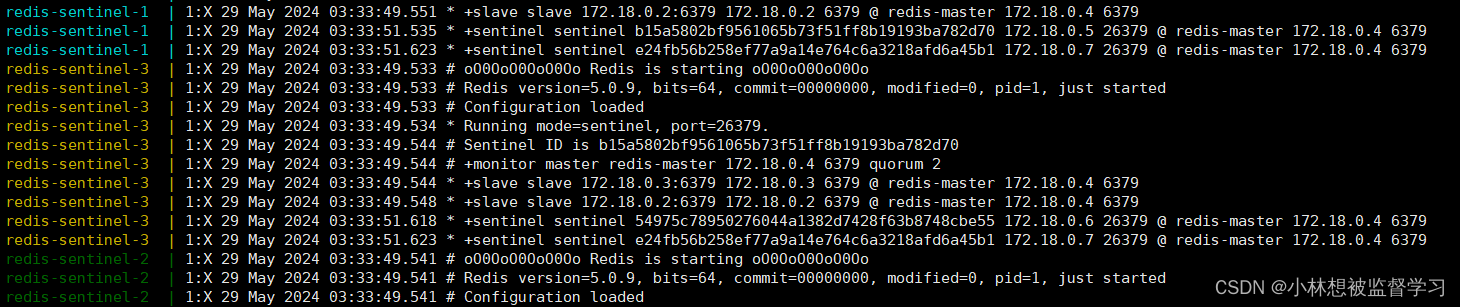
docker-compose logs我们可以看到,日志中报了很多错,错误内容都是 "哨兵节点不认识 redis-master " ,因为哨兵节点和 redis 主从节点我们是通过 redis-compose 分别进行编排的,而 redis-compose 会将一次编排后得到的节点放到一个局域网中,这就说明此时哨兵节点和 redis 主从节点不在一个局域网中,所以哨兵节点不认识 redis-master 也正常。

如何解决哨兵节点和主从节点不在同一局域网的问题
那该如何解决呢?
我们可以修改哨兵节点的 docker-compose.yml 配置文件,让哨兵节点创建后放到和 redis 主从节点相同的局域网中。
首先查看哨兵节点和主从节点所在的局域网:
docker network ls可以看到哨兵节点和主从节点所在的局域网名称和 ID

根据主从节点的局域网名称对哨兵节点的 docker-compose.yml 配置文件添加配置:
networks:
default:
external:
name: redis-data_default
表示将创建出的哨兵节点放到 redis 主从节点的局域网中。
删除已经创建的哨兵节点,再重新创建,再查看日志:
可以看到哨兵节点已经正确的连接上了 redis 主节点。
哨兵重新选举主节点流程
redis-master 宕机之后
现在我们手动停止 redis 主节点,看哨兵会进行怎样的处理。
⼿动把 redis-master ⼲掉
docker stop redis-master
查看日志
docker-compose logs观察哨兵的⽇志

可以看到哨兵发现了主节点 sdown, 进⼀步的由于主节点宕机得票达到 3/2 ,达到法定得票,于是 master 被判定为 odown.
• 主观下线 (Subjectively Down, SDown):哨兵感知到主节点没⼼跳了.判定为主观下线(此时就该哨兵认为主节点下线)
• 客观下线(Objectively Down, ODown): 多个哨兵达成⼀致意⻅,才能认为 master 确实下线了
投票选一个哨兵处理
确定 redis 主节点下线后,哨兵节点间就需要通过投票来选择一个 leader 节点进行处理,在哨兵节点的日志中可以看到如下信息:
redis-sentinel-2 | 1:X 29 May 2024 06:18:01.730 # +vote-for-leader e24fb56b258ef77a9a14e764c6a3218afd6a45b1 1
redis-sentinel-2 | 1:X 29 May 2024 06:18:01.731 # 54975c78950276044a1382d7428f63b8748cbe55 voted for 54975c78950276044a1382d7428f63b8748cbe55 1
redis-sentinel-2 | 1:X 29 May 2024 06:18:01.735 # b15a5802bf9561065b73f51ff8b19193ba782d70 voted for e24fb56b258ef77a9a14e764c6a3218afd6a45b1 1这里哨兵节点间在进行投票,得票数最多的哨兵节点会作为 leader 节点去处理主节点下线的问题,一般最先发现 redis 主节点下线的哨兵节点会成为 leader 节点,假设 sentinel-1 节点先发现 redis 主节点下线,sentinel-1 节点会先给自己投一票,将这件事通知给其他哨兵节点后,其他哨兵节点大概率会给 sentinel-1 投票,最后处理问题的就是最先发现问题的 sentinel-1 节点。
处理 redis 节点下线问题
在哨兵节点中选出了一个 leader 节点后,就会由该 leader 节点来处理 redis 主节点下线的问题,leader 节点会在 redis 从节点中选取一个来作为新的主节点,选取的依据通常是以下几个方面:
- 优先级,每个 redis 节点都可以在配置文件中通过 slave-priority 配置优先级,优先级高的便优先选取成为主节点
- offset,如果 redis 节点的优先级都相同,那么就比较哪个 redis 节点的 offset 值较大,offset 代表 redis 从节点同步的数据量,offset 越大代表该从节点同步的数据越多,与主节点的数据越接近
- run id,每个 redis 节点运行时随机生成的数字,说明当 redis 节点的优先级和 offset 都相等时,就随机选取一个节点作为新的主节点
选取出新的主节点后,leader 会控制这个节点,执行 "slave on one" 命令,与之前的主节点断开连接,该节点升级成主节点,再控制其他的从节点执行 "slaveof 新主节点IP 新主节点port" 命令使其他的从节点绑定上新的主节点。
之后如果这个下线的主节点又恢复过来了,就作为一个从节点绑定到当前新的主节点上。