-
一站制造项目中在数据采集时遇到了什么问题,以及如何解决这个问题?
-
技术选型:Sqoop
-
问题:发现采集以后生成在HDFS上文件的行数与实际Oracle表中的数据行数不一样,多了
-
原因:Sqoop默认将数据写入HDFS以普通文本格式存储,一旦遇到数据中如果包含了特殊字符\n,将一行的数据解析为多行
-
解决
-
方案一:Sqoop删除特殊字段、替换特殊字符【一般不用】
-
方案二:更换其他数据文件存储类型:AVRO
-
数据存储:Hive
-
数据计算:SparkSQL
-
什么是Avro格式,有什么特点?
-
二进制文本:读写性能更快
-
独立的Schema:生成文件每一行所有列的信息
-
对列的扩展非常友好
-
Spark与Hive都支持的类型
-
如何实现对多张表自动采集到HDFS?
-
需求
-
读取表名
-
执行Sqoop命令
-
效果:将所有增量和全量表的数据采集到HDFS上
-
目标:自动化的ODS层与DWD层构建
-
实现
-
掌握Hive以及Spark中建表的语法规则
-
实现项目开发环境的构建
-
实现所有代码注释
-
ODS层与DWD层整体运行测试成功

-
ODS层 :原始数据层
-
来自于Oracle中数据的采集
-
数据存储格式:AVRO
-
ODS区分全量和增量
-
实现
-
数据已经采集完成
/data/dw/ods/one_make/full_imp
/data/dw/ods/one_make/incr_imp
-
step1:创建ODS层数据库:one_make_ods
-
step2:根据表在HDFS上的数据目录来创建分区表
-
step3:申明分区
-
DWD层
-
来自于ODS层数据
-
数据存储格式:ORC
-
不区分全量和增量的
-
实现
-
step1:创建DWD层数据库:one_make_dwd
-
step2:创建DWD层的每一张表
-
step3:从ODS层抽取每一张表的数据写入DWD层对应的表中
Hive建表语法
sql
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
(
col1Name col1Type [COMMENT col_comment],
co21Name col2Type [COMMENT col_comment],
co31Name col3Type [COMMENT col_comment],
co41Name col4Type [COMMENT col_comment],
co51Name col5Type [COMMENT col_comment],
......
coN1Name colNType [COMMENT col_comment]
)
[PARTITIONED BY (col_name data_type ...)]
[CLUSTERED BY (col_name...) [SORTED BY (col_name ...)] INTO N BUCKETS]
[ROW FORMAT row_format]
row format delimited fields terminated by
lines terminated by
[STORED AS file_format]
[LOCATION hdfs_path]
TBLPROPERTIES
EXTERNAL:外部表类型
内部表、外部表、临时表
PARTITIONED BY:分区表结构
普通表、分区表、分桶表
CLUSTERED BY:分桶表结构
ROW FORMAT:指定分隔符
列的分隔符:\001
行的分隔符:\n
STORED AS:指定文件存储类型
ODS:avro
DWD:orc
LOCATION:指定表对应的HDFS上的地址
默认:/user/hive/warehouse/dbdir/tbdir
TBLPROPERTIES:指定一些表的额外的一些特殊配置属性
Hive中Avro建表方式及语法
指定文件类型
- 方式一:指定类型
sql
stored as avro- 方式二:指定解析类
sql
--解析表的文件的时候,用哪个类来解析
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
--读取这张表的数据用哪个类来读取
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
--写入这张表的数据用哪个类来写入
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'指定Schema
- 方式一:手动定义Schema
sql
CREATE TABLE embedded
COMMENT "这是表的注释"
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
TBLPROPERTIES (
'avro.schema.literal'='{
"namespace": "com.howdy",
"name": "some_schema",
"type": "record",
"fields": [ { "name":"string1","type":"string"}]
}'
);- 方式二:加载Schema文件
sql
CREATE TABLE embedded
COMMENT "这是表的注释"
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED as INPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
TBLPROPERTIES (
'avro.schema.url'='file:///path/to/the/schema/embedded.avsc'
);建表语法
- 方式一:指定类型和加载Schema文件
sql
create external table one_make_ods_test.ciss_base_areas
comment '行政地理区域表'
PARTITIONED BY (dt string)
stored as avro
location '/data/dw/ods/one_make/full_imp/ciss4.ciss_base_areas'
TBLPROPERTIES ('avro.schema.url'='/data/dw/ods/one_make/avsc/CISS4_CISS_BASE_AREAS.avsc');- 方式二:指定解析类和加载Schema文件
sql
create external table one_make_ods_test.ciss_base_areas
comment '行政地理区域表'
PARTITIONED BY (dt string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
location '/data/dw/ods/one_make/full_imp/ciss4.ciss_base_areas'
TBLPROPERTIES ('avro.schema.url'='/data/dw/ods/one_make/avsc/CISS4_CISS_BASE_AREAS.avsc');
create external table 数据库名称.表名
comment '表的注释'
partitioned by
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
location '这张表在HDFS上的路径'
TBLPROPERTIES ('这张表的Schema文件在HDFS上的路径')ODS层构建:需求分析
-
目标:将已经采集同步成功的101张表的数据加载到Hive的ODS层数据表中
-
问题
-
难点1:表太多,如何构建每张表?
-
101张表的数据已经存储在HDFS上
-
建表
-
方法1:手动开发每一张表建表语句,手动运行
-
方法2:通过程序自动化建表
-
拼接建表的SQL语句
sql
create external table 数据库名称.表名
comment '表的注释'
partitioned by
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
location '这张表在HDFS上的路径'
TBLPROPERTIES ('这张表的Schema文件在HDFS上的路径')-
-
-
- 表名、表的注释、表在HDFS上的路径、Schema文件在HDFS上的路径
-
-
-
将SQL语句提交给Hive或者Spark来执行
-
申明分区
sql
alter table 表名 add partition if not exists partition(key=value)-
难点2:如果使用自动建表,如何获取每张表的字段信息?
-
Schema文件:每个Avro格式的数据表都对应一个Schema文件
-
统一存储在HDFS上
-
需求:加载Sqoop生成的Avro的Schema文件,实现自动化建表
-
分析
-
step1:代码中构建一个Hive/SparkSQL的连接
-
step2:创建ODS层数据库
sql
create database if not exists one_make_ods;- step3:创建ODS层全量表:44张表
sql
create external table one_make_ods_test.ciss_base_areas
comment '行政地理区域表'
PARTITIONED BY (dt string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
location '/data/dw/ods/one_make/full_imp/ciss4.ciss_base_areas'
TBLPROPERTIES ('avro.schema.url'='hdfs://bigdata.itcast.cn:9000/data/dw/ods/one_make/avsc/CISS4_CISS_BASE_AREAS.avsc');-
读取全量表表名
-
动态获取表名:循环读取文件
-
获取表的信息:表的注释
-
Oracle:表的信息
-
从Oracle中获取表的注释
-
获取表的文件:HDFS上AVRO文件的地址
/data/dw/ods/one_make/full_imp
- 获取表的Schema:HDFS上的Avro文件的Schema文件地址
/data/dw/ods/one_make/avsc
-
拼接建表字符串
-
方式一:直接相加:简单
python
str1 = "I "
str2 = "like China"
str3 = str1 + str2-
方式二:通过列表拼接:复杂
-
执行建表SQL语句
-
step4:创建ODS层增量表:57张表
-
读取增量表表名
-
动态获取表名:循环读取文件
-
获取表的信息:表的注释
-
Oracle:表的信息
-
从Oracle中获取表的注释
-
获取表的文件:HDFS上AVRO文件的地址
/data/dw/ods/one_make/incr_imp
- 获取表的Schema:HDFS上的Avro文件的Schema文件地址
/data/dw/ods/one_make/avsc
-
拼接建表字符串
-
执行建表SQL语句
工程代码结构
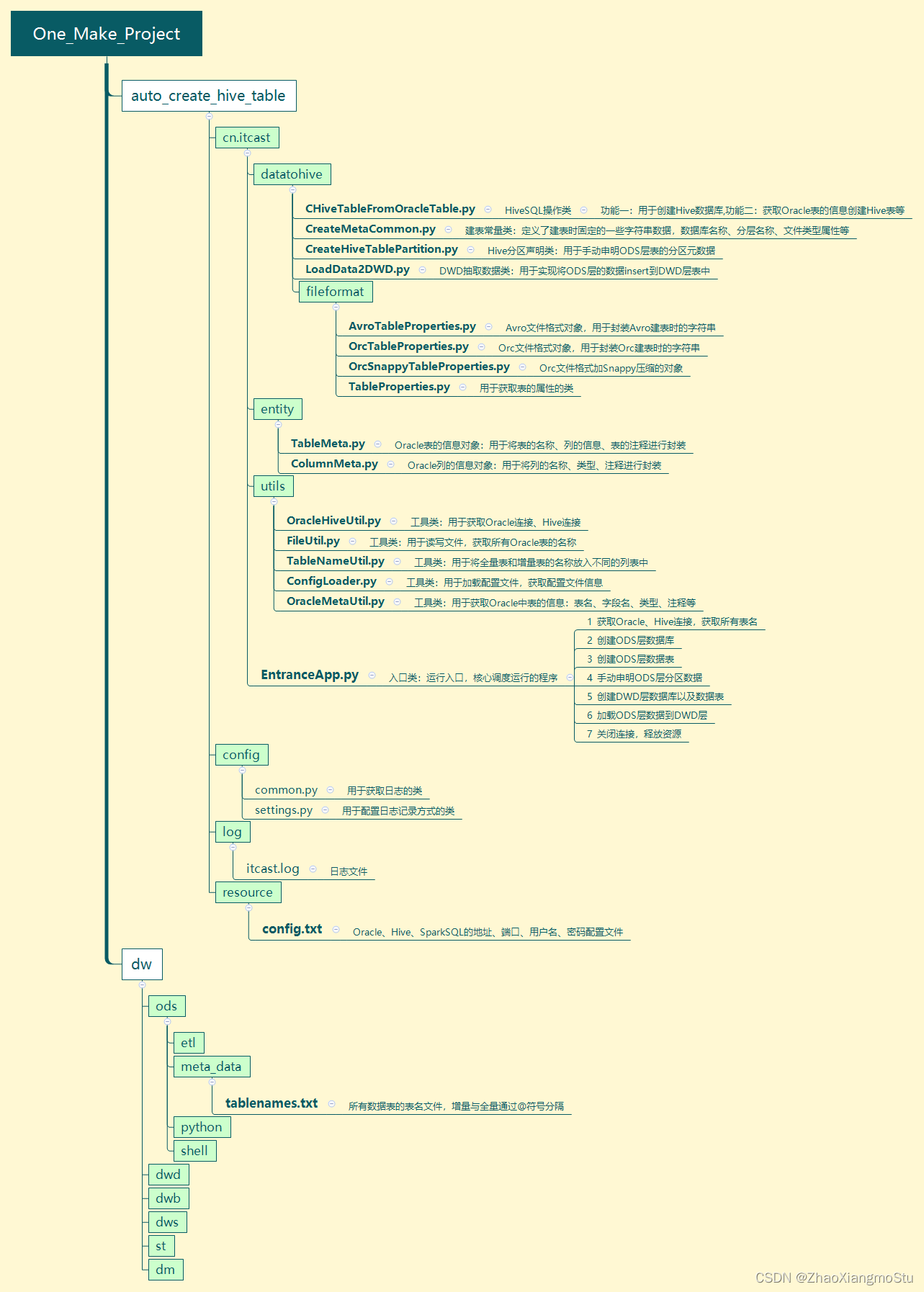
代码模块功能**
-
`auto_create_hive_table`:用于实现ODS层与DWD层的建库建表的代码
-
`cn.itcast`
-
`datatohive`
-
CHiveTableFromOracleTable.py:用于创建Hive数据库、以及获取Oracle表的信息创建Hive表等
-
CreateMetaCommon.py:定义了建表时固定的一些字符串数据,数据库名称、分层名称、文件类型属性等
-
CreateHiveTablePartition.py:用于手动申明ODS层表的分区元数据
-
LoadData2DWD.py:用于实现将ODS层的数据insert到DWD层表中
-
`fileformat`
-
AvroTableProperties.py- - - Avro文件格式对象,用于封装Avro建表时的字符串
-
OrcTableProperties.py:Orc文件格式对象,用于封装Orc建表时的字符串
-
OrcSnappyTableProperties.py:Orc文件格式加Snappy压缩的对象
-
TableProperties.py:用于获取表的属性的类
-
`entity`
-
TableMeta.py:Oracle表的信息对象:用于将表的名称、列的信息、表的注释进行封装
-
ColumnMeta.py:Oracle列的信息对象:用于将列的名称、类型、注释进行封装
-
`utils`
-
OracleHiveUtil.py:用于获取Oracle连接、Hive连接
-
FileUtil.py:用于读写文件,获取所有Oracle表的名称
-
TableNameUtil.py:用于将全量表和增量表的名称放入不同的列表中
-
ConfigLoader.py:用于加载配置文件,获取配置文件信息
-
OracleMetaUtil.py:用于获取Oracle中表的信息:表名、字段名、类型、注释等
-
EntranceApp.py:程序运行入口,核心调度运行的程序
todo:1-获取Oracle、Hive连接,获取所有表名
todo:2-创建ODS层数据库
todo:3-创建ODS层数据表
todo:4-手动申明ODS层分区数据
todo:5-创建DWD层数据库以及数据表
todo:6-加载ODS层数据到DWD层
todo:7-关闭连接,释放资源
-
`config`
-
common.py:用于获取日志的类
-
settings.py:用于配置日志记录方式的类
-
`log`
-
itcast.log:日志文件
-
`dw`:用于存储每一层构建的核心配置文件等
-
重点关注:dw.ods.meta_data.tablenames.txt:存储了整个ODS层的表的名称
代码配置修改
- 修改1:auto_create_hive_table.cn.itcast.EntranceApp.py
python
# 51行:修改为你实际的项目路径对应的表名文件
tableList = FileUtil.readFileContent("D:\\PythonProject\\OneMake_Spark\\dw\\ods\\meta_data\\tablenames.txt")- 修改2:auto_create_hive_table.cn.itcast.utils.ConfigLoader
python
config.read('D:\\PythonProject\\OneMake_Spark\\auto_create_hive_table\\resources\\config.txt')连接代码及测试
-
为什么要获取连接?
-
Python连接Oracle:获取表的元数据
-
表的信息:TableMeta
-
表名
-
表的注释
-
list:列的信息
-
列的信息:ColumnMeta
-
列名
-
列的注释
-
列的类型
-
类型长度
-
类型精度
-
Python连接HiveServer或者Spark的ThriftServer:提交SQL语句
-
连接代码讲解
-
step1:怎么获取连接?
-
Oracle:安装Python操作Oracle库包:cx_Oracle
python
cx_Oracle.connect(ORACLE_USER, ORACLE_PASSWORD, dsn)- Hive/SparkSQL:安装Python操作Hive库包:PyHive
python
hive.Connection(host=SPARK_HIVE_HOST, port=SPARK_HIVE_PORT, username=SPARK_HIVE_UNAME, auth='CUSTOM', password=SPARK_HIVE_PASSWORD)-
step2:连接时需要哪些参数?
-
Oracle:主机名、端口、用户名、密码、SID
-
Hive:主机名、端口、用户名、密码
-
step3:如果有100个代码都需要构建Hive连接,怎么解决呢?
-
将所有连接参数写入一个配置文件:resource/config.txt
-
通过配置文件的工具类获取配置:ConfigLoader
-
step4:在ODS层建101张表,表名怎么动态获取呢?
-
读取表名文件:将每张表的名称都存储在一个列表中
-
step5:ODS层的表分为全量表与增量表,怎么区分呢?
-
通过对@符号的分割,将全量表和增量表的表名存储在不同的列表中
连接代码测试
- 启动虚拟运行环境
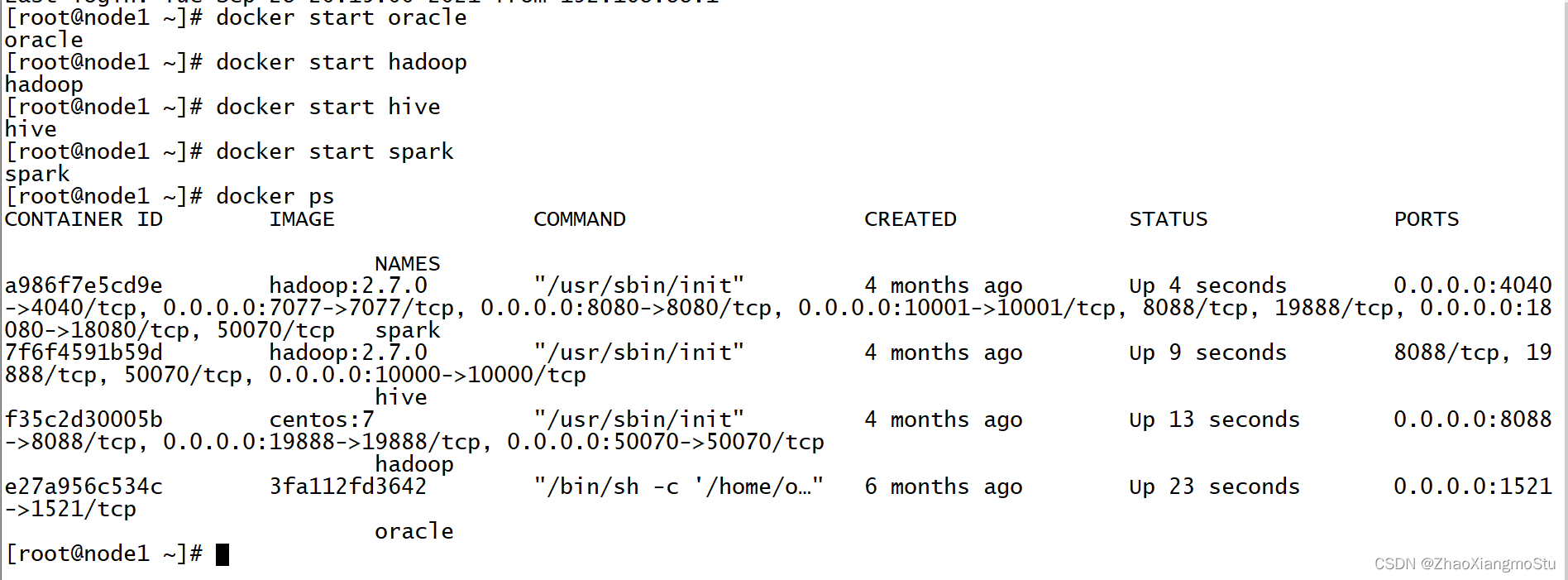
运行测试代码
python
def getOracleConn():
"""
用户获取Oracle的连接对象:cx_Oracle.connect(host='', port='', username='', password='', param='')
:return:
"""
oracleConn = None #构建Oracle连接对象
try:
ORACLE_HOST = ConfigLoader.getOracleConfig('oracleHost') # 获取Oracle连接的主机地址
ORACLE_PORT = ConfigLoader.getOracleConfig('oraclePort') # 获取Oracle连接的端口
ORACLE_SID = ConfigLoader.getOracleConfig('oracleSID') # 获取Oracle连接的SID
ORACLE_USER = ConfigLoader.getOracleConfig('oracleUName') # 获取Oracle连接的用户名
ORACLE_PASSWORD = ConfigLoader.getOracleConfig('oraclePassWord') # 获取Oracle连接的密码
# 构建DSN
dsn = cx_Oracle.makedsn(ORACLE_HOST, ORACLE_PORT, ORACLE_SID)
# 获取真正的Oracle连接
oracleConn = cx_Oracle.connect(ORACLE_USER, ORACLE_PASSWORD, dsn)
# 异常处理
except cx_Oracle.Error as error:
print(error)
# 返回Oracle连接
return oracleConn
def getSparkHiveConn():
"""
用户获取SparkSQL的连接对象
:return:
"""
# 构建SparkSQL的连接对象
sparkHiveConn = None
try:
SPARK_HIVE_HOST = ConfigLoader.getSparkConnHiveConfig('sparkHiveHost') # 获取Spark连接的主机地址
SPARK_HIVE_PORT = ConfigLoader.getSparkConnHiveConfig('sparkHivePort') # 获取Spark连接的端口
SPARK_HIVE_UNAME = ConfigLoader.getSparkConnHiveConfig('sparkHiveUName') # 获取Spark连接的用户名
SPARK_HIVE_PASSWORD = ConfigLoader.getSparkConnHiveConfig('sparkHivePassWord') # 获取Spark连接的密码
# 获取一个Spark TriftServer连接对象
sparkHiveConn = hive.Connection(host=SPARK_HIVE_HOST, port=SPARK_HIVE_PORT, username=SPARK_HIVE_UNAME, auth='CUSTOM', password=SPARK_HIVE_PASSWORD)
# 异常处理
except Exception as error:
print(error)
# 返回连接对象
return sparkHiveConn
def readFileContent(fileName):
"""
加载表名所在的文件
:param fileName:存有表名的文件路径
:return:存有所有表名的列表集合
"""
# 定义一个空的列表,用于存放表名,最后返回
tableNameList = []
# 打开一个文件
fr = open(fileName)
# 遍历每一行
for line in fr.readlines():
# 将每一行尾部的换行删掉
curLine = line.rstrip('\n')
# 把表名放入列表
tableNameList.append(curLine)
# 返回所有表名的列表
return tableNameList
def getODSTableNameList(fileNameList):
"""
基于传递的所有表名,将增量表与全量表进行划分到不同的列表中
:param fileNameList: 所有表名的列表
:return: 增量与全量列表
"""
# 定义全量空列表
full_list = []
# 定义增量空列表
incr_list = []
# 用于返回的结果列表
result_list = []
# 定义一个bool值,默认为true
isFull = True
# 取出集合中的每一个表名
for line in fileNameList:
# 如果isFull = True
if isFull:
# 如果当前取到的表名为@
if "@".__eq__(line):
# 将 isFull = False
isFull = False
# 跳过本次循环
continue
# 将表名放入全量表的列表中
full_list.append(line)
# 如果isFull = False
else:
# 将表名放入增量列表
incr_list.append(line)
# 将全量列表和增量列表放入一个结果列表中
result_list.append(full_list)
result_list.append(incr_list)
# 返回结果列表
return result_list
python
if __name__ == '__main__':
# =================================todo: 1-初始化Oracle、Hive连接,读取表的名称=========================#
# 输出信息
recordLog('ODS&DWD Building AND Load Data')
# 定义了一个分区变量:指定当前要操作的Hive分区的值为20210101
partitionVal = '20210101'
# 调用了获取连接的工具类,构建一个Oracle连接
oracleConn = OracleHiveUtil.getOracleConn()
# 调用了获取连接的工具类,构建一个SparkSQL连接
hiveConn = OracleHiveUtil.getSparkHiveConn()
# 调用了文件工具类读取表名所在的文件:将所有表的名称放入一个列表:List[102个String类型的表名]
tableList = FileUtil.readFileContent("D:\\PythonProject\\OneMake30\\dw\\ods\\meta_data\\tablenames.txt")
# 调用工具类,将全量表的表名存入一个列表,将增量表的表名存入另外一个列表中,再将这两个列表放入一个列表中:List[2个List元素:List1[44张全量表的表名],List2[57张增量表的表名]]
tableNameList = TableNameUtil.getODSTableNameList(tableList)
# ------------------测试:输出获取到的连接以及所有表名
print(oracleConn)
print(hiveConn)
for tbnames in tableNameList:
print("---------------------")
for tbname in tbnames:
print(tbname)- 执行代码观察结果
ODS建库代码及实现测试
step1:ODS层的数据库名称叫什么?
one_make_ods
-
step2:如何使用PyHive创建数据库?
-
第一步:先获取连接
-
第二步:拼接SQL语句,从连接对象中获取一个游标
-
第三步:使用游标执行SQL语句
-
第四步:释放资源
python
class CHiveTableFromOracleTable:
# 构建当前类的对象时,初始化Oracle和Hive的连接
def __init__(self, oracleConn, hiveConn):
self.oracleConn = oracleConn
self.hiveConn = hiveConn
# 创建数据库方法
def executeCreateDbHQL(self, dbName):
"""
根据传递的数据库名称,在Hive中创建数据库
:param dbName: 数据库名称
:return: None
"""
# 拼接建库的SQL语句
createDbHQL = 'create database if not exists ' + dbName
# 从SparkSQL连接获取一个游标:理解为执行SQL语句的对象
cursor = self.hiveConn.cursor()
try:
# 使用游标对象执行SQL语句
cursor.execute(createDbHQL)
# 异常处理
except hive.Error as error:
print(error)
# 执行结束,最后释放游标
finally:
if cursor:
cursor.close()
python
# =================================todo: 2-ODS层建库=============================================#
# 构建了一个建库建表的类的对象:实例化的时候给连接赋值
cHiveTableFromOracleTable = CHiveTableFromOracleTable(oracleConn, hiveConn)
# 打印日志
recordLog('ODS层创建数据库')
# 调用这个类的创建数据库的方法:传递ODS层数据库的名称
cHiveTableFromOracleTable.executeCreateDbHQL(CreateMetaCommon.ODS_NAME)运行代码,查看结果
ODS建表代码及实现测试
表名怎么获取?
tableNameList【full_list,incr_list】
full_list:全量表名的列表
incr_list:增量表名的列表
step2:建表的语句是什么,哪些是动态变化的?
sql
create external table 数据库名称.表名
comment '表的注释'
partitioned by
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
location '这张表在HDFS上的路径'
TBLPROPERTIES ('这张表的Schema文件在HDFS上的路径')-
- 表名
-
表的注释
-
表的HDFS地址
-
Schema文件的HDFS地址
-
step3:怎么获取表的注释?
-
从Oracle中获取:从系统表中获取某张表的信息和列的信息
sql
select
columnName, dataType, dataScale, dataPercision, columnComment, tableComment
from
(
select
column_name columnName,
data_type dataType,
DATA_SCALE dataScale,
DATA_PRECISION dataPercision,
TABLE_NAME
from all_tab_cols where 'CISS_CSP_WORKORDER' = table_name) t1
left join (
select
comments tableComment,TABLE_NAME
from all_tab_comments WHERE 'CISS_CSP_WORKORDER' = TABLE_NAME) t2
on t1.TABLE_NAME = t2.TABLE_NAME
left join (
select comments columnComment, COLUMN_NAME
from all_col_comments WHERE TABLE_NAME='CISS_CSP_WORKORDER') t3
on t1.columnName = t3.COLUMN_NAME;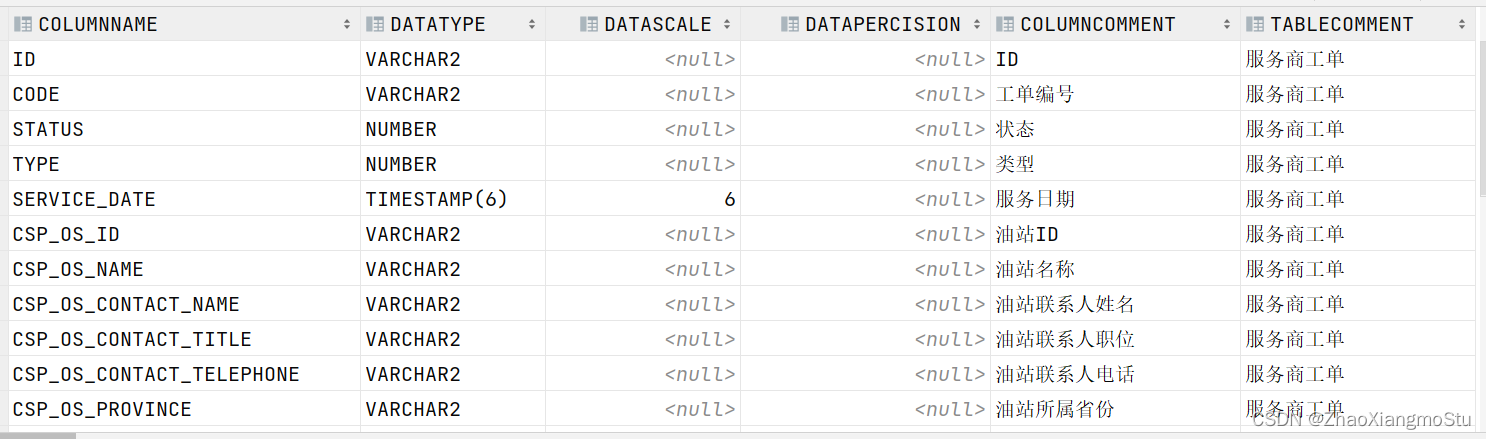
-
step4:全量表与增量表有什么区别?
-
区别1:表名不一样
-
full_table_list
-
incr_table_list
-
区别2:路径不一样
-
`/data /dw /ods /one_make /full /Oracle库名.表名`
-
`/data /dw /ods /one_make /incr /Oracle库名.表名`
-
step5:如何实现自动化建表?
-
自动化创建全量表
-
获取全量表名
-
调用建表方法:数据库名称、表名、全量标记
-
通过Oracle工具类获取表的信息【表的名称、表的注释、字段信息等】
-
拼接建表语句
-
执行SQL语句
-
自动化创建增量表
-
获取增量表名
-
调用建表方法:数据库名称、表名、增量标记
-
通过Oracle工具类获取表的信息【表的名称、表的注释、字段信息等】
-
拼接建表语句
-
执行SQL语句
运行代码,查看结果
python
# 执行Hive建表
def executeCreateTableHQL(self, dbName, tableName, dynamicDir):
"""
用于根据传递的数据库名称、表名在Hive中创建对应的表,self为当前类的实例对象
:param dbName: 数据库名称【ODS、DWD】
:param tableName: 表名
:param dynamicDir: 全量或者增量【full_imp、incr_imp】
:return: None
"""
# 构建一个空的列表:用于拼接字符串:SQL语句
buffer = []
# 构建一个游标对象
cursor = None
try:
# 调用工具类,从Oracle中获取这张表的元数据【表的信息 = 表名 + 表的注释 + list[列的信息]】
tableMeta = OracleMetaUtil.getTableMeta(self.oracleConn, tableName.upper())
# 拼接SQL:create external table if not exists one_make_ods.
buffer.append("create external table if not exists " + dbName + ".")
# 拼接SQL:CISS_CSP_WORKORDER
buffer.append(tableName.lower())
# 拼接SQL:列的信息,【ODS层不执行】,DWD层用于拼接每一列信息
buffer = getODSStringBuffer(buffer, dbName, tableMeta)
# 拼接SQL:如果表有注释,就将表的注释拼接到建表语句中
if tableMeta.tableComment:
buffer.append(" comment '" + tableMeta.tableComment + "' \n")
# 拼接SQL:指定分区
buffer.append(' partitioned by (dt string) ')
# 拼接SQL:Schema的路径以及文件的存储格式
buffer.append(CreateMetaCommon.getTableProperties(dbName, tableName))
# ODS => ods,DWD => dwd
dbFolderName = CreateMetaCommon.getDBFolderName(dbName)
# ODS => ciss4. ,DWD => 空
userName = CreateMetaCommon.getUserNameByDBName(dbName)
# 拼接SQL:location
buffer.append(" location '/data/dw/" + dbFolderName + "/one_make/" + CreateMetaCommon.getDynamicDir(dbName,dynamicDir) + "/" + userName + tableName + "'")
# 获取SparkSQL的游标
cursor = self.hiveConn.cursor()
# 执行SQL语句
cursor.execute(''.join(buffer))
logging.warning(f'oracle表转换{dbFolderName}后的Hive DDL语句为:\n{"".join(buffer)}')
# 异常处理
except Exception as exception:
print(exception)
# 释放游标
finally:
if cursor:
cursor.close()
python
def getTableMeta(oracleConn, tableName) -> TableMeta:
"""
用于读取Oracle中表的信息【表名、列的信息、表的注释】封装成TableMeta
:param oracleConn: Oracle连接对象
:param tableName: 表的名称
:return:
"""
# 从连接中获取一个游标【SQL对象】
cursor = oracleConn.cursor()
try:
# 定义Oracle查询表信息的SQL语句
oracleSql = f"""select columnName, dataType, dataScale, dataPercision, columnComment, tableComment from
(select column_name columnName,data_type dataType, DATA_SCALE dataScale,DATA_PRECISION dataPercision, TABLE_NAME
from all_tab_cols where '{tableName}' = table_name) t1
left join (select comments tableComment,TABLE_NAME from all_tab_comments WHERE '{tableName}' = TABLE_NAME) t2 on t1.TABLE_NAME = t2.TABLE_NAME
left join (select comments columnComment, COLUMN_NAME from all_col_comments WHERE TABLE_NAME='{tableName}') t3 on t1.columnName = t3.COLUMN_NAME
"""
# 记录运行的SQL语句
logging.warning(f'query oracle table {tableName} metadata sql:\n{oracleSql}')
# 执行SQL语句
cursor.execute(oracleSql)
# 获取执行的结果
resultSet = cursor.fetchall()
# 构建返回的表的信息对象:表名 + 列的信息 + 表的注释
tableMeta = TableMeta(f'{tableName}', '')
# 表信息 = 表名 + 表的注释 + list[列的信息]
for line in resultSet:
# 获取每一列的信息
columnName = line[0] # 获取列的名称
dataType = line[1] # 获取列的类型
dataScale = line[2] # 获取列值长度
dataScope = line[3] # 获取列值精度
columnComment = line[4] # 获取列的注释
tableComment = line[5] # 获取表的注释
if dataScale is None: # 如果列值的长度为空,则设置为0
dataScale = 0
if dataScope is None: # 如果列值的精度为空,则设置为0
dataScope = 0
# 将每条数据封装成一个列的信息对象【列名 + 类型 + 长度 + 精度 + 注释】
columnMeta = ColumnMeta(columnName, dataType, columnComment, dataScope, dataScale)
# 将列的信息添加到表的对象中
tableMeta.addColumnMeta(columnMeta)
# 将表的注释添加到表的对象中
tableMeta.tableComment = tableComment
# 返回当前表的所有信息【表名 + 所有列的信息 + 表的注释】
return tableMeta
# 异常处理
except cx_Oracle.Error as error:
print(error)
# 关闭游标
finally:
if cursor:
cursor.close()
python
# =================================todo: 3-ODS层建表=============================================#
# 打印日志
recordLog('ODS层创建全量表...')
# 从表名的列表中取出第一个元素:全量表名的列表
fullTableList = tableNameList[0]
# 取出每张全量表的表名
for tblName in fullTableList:
# # 创建全量表:ODS层数据库名称,全量表的表名,full_imp
cHiveTableFromOracleTable.executeCreateTableHQL(CreateMetaCommon.ODS_NAME, tblName, CreateMetaCommon.FULL_IMP)
# 打印日志
recordLog('ODS层创建增量表...')
# # 从表名的列表中取出第二个元素:增量表名的列表
incrTableList = tableNameList[1]
# 取出每张增量表的表名
for tblName in incrTableList:
# # Hive中创建这张增量表:ODS层数据库名称,增量表的表名,incr_imp
cHiveTableFromOracleTable.executeCreateTableHQL(CreateMetaCommon.ODS_NAME, tblName, CreateMetaCommon.INCR_IMP)
ODS申明分区的代码及实现测试
- step1:为什么要申明分区?
- 表的分区数据由Sqoop采集到HDFS生成AVRO文件
/data/dw/ods/one_make/full_imp/ciss4.ciss_base_areas/20210101/part-m-00000.avro
-
- HiveSQL基于表的目录实现了分区表的创建
sql
create external table if not exists one_make_ods.ciss_base_areas
partitioned by (dt string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
tblproperties ('avro.schema.url'='hdfs:///data/dw/ods/one_make/avsc/CISS4_CISS_BASE_AREAS.avsc')
location '/data/dw/ods/one_make/full_imp/ciss4.ciss_base_areas'-
- 但是Hive中没有对应分区的元数据,无法查询到数据
-
step2:怎么申明分区?
-
Alter Table
sql
alter table 表名 add if not exists partition (dt='值')
location 'HDFS上的分区路径'- 例如
sql
alter table one_make_ods.ciss_base_areas add if not exists partition (dt='20210101')
location '/data/dw/ods/one_make/full_imp/ciss4.ciss_base_areas/20210101'-
step3:如何自动化实现每个表的分区的申明?
-
获取分区工具类实例
-
调用申明分区的方法
-
对所有全量表调用申明分区的方法:数据库名称、表名、全量标记、分区值
-
对所有增量表调用申明分区的方法:数据库名称、表名、增量标记、分区值
-
拼接SQL
-
执行SQL
代码测试
python
# =================================todo: 4-ODS层申明分区=============================================#
recordLog('创建ods层全量表分区...')
# 构建专门用于申明分区的类的对象
createHiveTablePartition = CreateHiveTablePartition(hiveConn)
# 全量表执行44次创建分区操作
for tblName in fullTableList:
# # 调用申明分区的方法申明全量表的分区:ods层数据库名称、表名、full_imp,20210101
createHiveTablePartition.executeCPartition(CreateMetaCommon.ODS_NAME, tblName, CreateMetaCommon.FULL_IMP, partitionVal)
recordLog('创建ods层增量表分区...')
# 增量表执行57次创建分区操作
for tblName in incrTableList:
createHiveTablePartition.executeCPartition(CreateMetaCommon.ODS_NAME, tblName, CreateMetaCommon.INCR_IMP, partitionVal)
python
def executeCPartition(self, dbName, hiveTName, dynamicDir, partitionDT):
"""
用于实现给Hive表的数据手动申明分区
:param dbName: 数据库名称
:param hiveTName: 表名称
:param dynamicDir: 全量或者增量
:param partitionDT: 分区值
:return: None
"""
# 构建空的列表,拼接SQL语句
buffer = []
# 定义一个游标
cursor = None
try:
# SQL拼接:alter table one_make_ods.
buffer.append("alter table " + dbName + ".")
# SQL拼接:表名
buffer.append(hiveTName)
# SQL拼接:add if not exists partition (dt='
buffer.append(" add if not exists partition (dt='")
# SQL拼接:20210101
buffer.append(partitionDT)
# SQL拼接:') location 'data/dw/ods/one_make/full_imp/ciss4.'
buffer.append("') location '/data/dw/" + CreateMetaCommon.getDBFolderName(dbName) +
"/one_make/" + CreateMetaCommon.getDynamicDir(dbName, dynamicDir) + "/ciss4.")
# SQL拼接:表名
buffer.append(hiveTName)
# SQL拼接:/
buffer.append("/")
# SQL拼接:分区目录
buffer.append(partitionDT)
buffer.append("'")
# 实例化SparkSQL游标
cursor = self.hiveConn.cursor()
# 执行SQL语句
cursor.execute(''.join(buffer))
# 输出日志
logging.warning(f'执行创建hive\t{hiveTName}表的分区:{partitionDT},\t分区sql:\n{"".join(buffer)}')
# 异常处理
except Exception as e:
print(e)
# 释放游标
finally:
if cursor:
cursor.close()