常见的可作为消息队列的工具有:RabbitMQ,RocketMQ,Kafka(以及Redis);以下是我对这些产品的总结
这些消息队列的不同可以归纳为:
- 架构
- 使用 & 生态
依次总结
架构
## RabbitMQ
rabbitMQ相较于RocketMQ和Kafka这两款为大数据而生的消息队列,自身架构相对简单;是对AMQP协议的简单实现
> [深入理解AMQP协议-CSDN博客](https://link.juejin.cn?target=https%3A%2F%2Fblog.csdn.net%2Fweixin_37641832%2Farticle%2Fdetails%2F83270778 "https://blog.csdn.net/weixin_37641832/article/details/83270778")
基础架构图如下数据流转案例(Topic模式): Producer生产的消息中带有routing key,broker中的queue绑定有用于模糊匹配的binding key;
- 生产者封装好消息,通过网络推送到server
- 消息到达server(broker),被传递给交换机
- 消息到达交换机,通过routing key匹配关系,被路由到队列;等待消费者消费
- 消费者可以选择Push & Poll模式进行消费
注意的点:
-
消息会在生产者到队列的过程中丢失吗?按照上述流程分析,消息丢失有以下几个可能性 但是在确定可能性之前,需要配置RabbitMQ的回调功能,由回调信息观察数据在链路中哪里丢失
开启回调的方式理论上只需要绑定具体回调函数,而Springboot也确实帮我们简化到这一步
JAVAimport org.springframework.amqp.core.Message; import org.springframework.amqp.rabbit.connection.ConnectionFactory; import org.springframework.amqp.rabbit.connection.CorrelationData; import org.springframework.amqp.rabbit.core.RabbitTemplate; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class RabbitConfig { @Bean public RabbitTemplate createRabbitTemplate(ConnectionFactory connectionFactory){ RabbitTemplate rabbitTemplate = new RabbitTemplate(); rabbitTemplate.setConnectionFactory(connectionFactory); //设置开启Mandatory,才能触发回调函数,无论消息推送结果怎么样都强制调用回调函数 rabbitTemplate.setMandatory(true); rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback() { @Override public void confirm(CorrelationData correlationData, boolean ack, String cause) { System.out.println("ConfirmCallback: "+"相关数据:"+correlationData); System.out.println("ConfirmCallback: "+"确认情况:"+ack); System.out.println("ConfirmCallback: "+"原因:"+cause); } }); rabbitTemplate.setReturnCallback(new RabbitTemplate.ReturnCallback() { @Override public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) { System.out.println("ReturnCallback: "+"消息:"+message); System.out.println("ReturnCallback: "+"回应码:"+replyCode); System.out.println("ReturnCallback: "+"回应信息:"+replyText); System.out.println("ReturnCallback: "+"交换机:"+exchange); System.out.println("ReturnCallback: "+"路由键:"+routingKey); } }); return rabbitTemplate; } }原因分析
-
消息推送到broker,但是到不了交换机 可能是消息绑定的交换机写错了导致没找到 报错信息:
channel error; protocol method: #method<channel.close>(reply-code=404, reply-text=NOT_FOUND - no exchange 'non-existent-exchange' in vhost 'JCcccHost', class-id=60, method-id=40) -
消息会在交换机到队列的过程中丢失 可能是binding key写错了导致无法匹配 报错信息:
NO_ROUTE
此处的消息丢失可以被Producer观测并附带兜底处理,但是消息如果在消费过程中丢失,那看起来是真的丢失
消费者消息确认
- 默认没有确认机制,即AcknowledgeNode.NONE;生产者将消息成功发出后就不管消费者是否成功处理本次投递
这种情况据说是由于消费端异常导致,可以手动try-catch将异常消息重新入队,或者至少能够在日志中体现异常;但是如果数据丢失不会产生异常,那就需要一种更加保险的,类似ack的机制
- 手动确认;消费者在收到消息后,手动调用basic.ack 或者basic.nack 或者 basic.reject,broker在收到这些信息后,根据具体内容确保消息成功消费
-
-
消费模式
- 推模式(Push):broker主动将消息推送到消费者
- broker中需要感知consumer节点
- consumer被动的接收来自broker的消息,在大量消息轰炸的时候可能会导致consumer被打垮【即:消费能力不足】 以上就是Kafka选择拉模式的原因
- 好处是实时性高,消息一旦到达Broker就会推到consumer(类似webSocket)
- 将缓冲的任务交给Consumer:适用于消息量不大、或者Consumer消费能力强的场景
- 拉模式(Pull):消费者主动从broker拉取消息
- 消费者根据自身的消费能力拉取消息
- 将海量消息积压的隐患从consumer移到broker
- 但是代价是消息的实时性不好,pull的频率需要小心考虑
- 轮询
- 长轮询:Kafka使用long polling,简单而言就是建立长连接后等待broker响应消息,未收到消息则维持着此长连接;这种方式和Kafka十分契合,因为Kafka的broker也是批量处理数据,正好批量发给consumer的longpolling,同时consumer个数有限,也不会有太多长连接的压力
集群模式架构:
- 推模式(Push):broker主动将消息推送到消费者
简单践行集群思路防止单点故障
注意的点:
-
集群中节点的身份/职能不同
- RAM node:存储所有队列,交换机,绑定信息,权限...用来横向扩展broker
- Disk node:将元数据存储在磁盘中,作为数据备份防止系统宕机后消息丢失
-
按照网上的说法,RabbitMQ集群的数据一致性实现方案是:每条消息都会同步的发到集群中 其他一致性实现方案:
Master-slave
最直观的集群一致性确保方案,分为
- 同步复制
master收到消息后,即可将消息向slave同步,全都确认后master才返回确认信息
过程简单,并且可以通过两阶段提交方式实现分布式事务
- 异步复制
master将即将同步到slave的消息缓存到某个数据结构,再由其他线程,按照某种策略完成同步
很容易想到牺牲了一定的一致性,换取了一定的可用性
WNR
主要用于去中心化(P2P)的分布式系统中
- N表示副本数,W表示每次写操作最少保证写成功的副本数,R代表每次读至少读取的副本数
- 确保W + R > N,即可保证每次读取的数据中至少有一个是最新的
类似思路:
- RAFT中 通知超过半数的思路
- Redis实现分布式锁中 红锁RedLock Paxos 及其变种
联邦模式架构:
通过使用Federation插件可以给rabbitMQ的节点间实现信息交换;但不同于我们在HDFS联邦的概念,此处的联邦主要目的就是在多个broker节点中实现消息的高效传递
具体分为:
- 联邦交换机可以实现相距千里的broker的交换机的访问效果一致 下面先假设一种场景,BrokerA服务部署在上海,BrokerB服务部署在北京。来自上海的ClientA向BrokerA的exchangeA发送消息网络延迟很小,但是北京的ClientB向BrokerA的exchangeA发送消息那么将会面临网络延迟的问题。Federation机制则可以帮助我们解决这个问题。
- 联邦队列可以实现不同broker的队列负载均衡 如果两个队列互为联邦队列,队列中的消息除了被消费,还会转向有多余消费能力的一方,如果这种"多余的消费能力"在broker1和broker2中来回切换,那么消费也会在broker1和broker2中的队列queue中来回转发
详情请见大佬博文
RocketMQ
早期架构:
早期的架构和RabbitMQ类似,同时由于要适配大数据,各端都需要集群配置;参考了Kafka的ZK管理集群,使用nameServer管理元数据
5.0升级:
个人感觉升级后的变化对于我这种初级开发者而言并不重要,其实主要也是看不懂
官方所说的升级:
云原生化升级
轻量API和多语言SDK
事件、流处理场景集成
数据备份方案:Controller & DLedger
数据如果只在一台broker的一个Queue(一个CommitLog)中,自然有服务器宕机导致不可用的风险。在RocketMQ 4.5 版本之前,解决方案是Broker层面的主从:
一组Broker集群内有一个Master,零到多个Slave,Slave通过同步复制或者异步复制的方式去同步Master的数据,这和RabbitMQ设计类似;但是这样的部署需要解决故障转移的问题;常见方案有两个:
-
需要第三方来做,要么人为手动从Slave中选出新Master,要么依赖于类似ZK或etcd的注册中心;RocketMQ中可以使用轻量级的nameServer服务;实际解决方案是抽象出另一个模块Controller
Controller的部署有两种方式,一种是嵌入NameServer,通过更改nameServer以及Broker的配置文件即可完成部署;另一种是独立部署,在一台独立的服务器上执行官方给出的脚本即可;
问题: 第一种内嵌模式中有一个矛盾的点:nameServer本身是无状态的,每个producer都可以随机访问一个NameServer即可,但是当给nameServer添加Controller的任务后,controller就需要选出master来负责权威的选主任务,(或者用类似某种共识算法的方式从去中心化的controller中选出唯一的结果吗?)所以感觉还是需要独立部署。
-
使用类似Raft协议的方案完成自动选主,RocketMQ采用Raft在文件同步场景下的改版Dledge
Deldger是一个轻量级的Java库,作用就是对Raft的API实现,开发人员只需要关注业务即可;
Raft协议本身是对状态机的同步,但在RocketMQ中需要对CommitLog进行同步;Deldger的工作需要完成选主+数据复制+安全性保障三部分;
对于数据复制的工作原理,类似于,代理CommitLog的写入,写入任务原本由Broker完成,但使用Deldger会代理写入操作,并在代理层实现一致性算法【Raft的数据复制】;
Dledger架构如图所示
参考博文: Dledger | RocketMQ (apache.org) 阿里数据一致性实践:Dledger 技术在消息领域的探索和应用_大数据_InfoQ精选文章
消息流转案例:
- 生产者首先和NameServer集群中的随机一台建立长连接,得知当前要发送的Topic存在在哪些个Broker Master上
- 生产者准备好一条消息message,确定其主题Topic,标签Tag
- 根据某种选择策略 / 负载均衡算法,选择某个broker进行消息发送
- Broker配置有集群 + 主从的模式,启动时,broker注册到nameServer,并定期上传心跳报
- broker收到消息后即可将消息存入相应queue中 具体而言是通过commitlog + consumerQueue两个文件的配合,实现基于磁盘而非内存的运作
- broker将本机所有Topic的消息存入Commitlog,并且在不同的ConsumerQueue中存储消息索引,用于对CommitLog中的消息精准定位
- consumer向broker发起拉取请求,其中包含要拉取的目标queue,消息的offset,以及消息tag 消费完数据A后直接销毁A,这是最直观的想法,但是出于某些原因,RocketMQ & Kafka选择通过offset指针逻辑删除A,真正删除需要其他任务来执行 某些原因:
- 维护顺序写:这是保证基于磁盘读写效率高的重要因素,如果消费完就销毁,哪磁盘的指针就要回到A开头的位置,同时A的长度不确定,这就等同于随机写了
- 给予消费方式的灵活性,不同的消费者可以相互独立的消费相同的内容而互不干扰
- 或许还有消息回滚 / 恢复的场景...
- broker收到consumer的请求后,首先计算消息在consumerQueue中的offset,获取到消息索引后,定位到commitlog中的offset,读取并返回给consumer
参考博客:图解RocketMQ消息发送和存储流程-腾讯云开发者社区-腾讯云 (tencent.com)
注意的点:
-
老生常谈的点:RocketMQ & Kafka基于磁盘操作为什么会比基于内存操作更快?
之前我也以为这种说法一定是营销人员为了鼓吹产品的片面之词,但是Kafka在官方文档中提到:Don't fear the file system! 不要害怕文件系统;这让我重新考虑了有没有可能真的做到更快呢?
- OS层面的PageCache 针对磁盘IO的优化,提供更快的磁盘读写
- Java FileChannel对零拷贝的实现
- 通过ByteBuffer类将数据直接写入直接内存的pageCache,避免JVM内外的复制
- 通过MappedByteBuffer调用Linux的mmap内存映射机制,是的处理文件就像处理内存
- 通过FileChannel.transferTo相当于Linux的sendfile系统调用,避免OS层面的复制
- 配合DMA,直接将数据赋值给网卡,避免网卡的复制
- Kafka磁盘写操作设计为顺序写,数据结构采用队列而非B+树;可以将数据大小与性能解耦,保证读写操作时间复杂度都在常数内。
//TODO
-
RocketMQ相比于RabbitMQ,没有exchange交换机层,是否意味着不灵活?
其实我认为:按照人类正常思维就不该有交换机层,生产者想要发到哪个Queue就直接指定就好了,没必要非要用binding key和routing key再匹配了吧 其次更重要的是:
RabbitMQ中,队列的作用更偏向消费者,队列中元素的进入条件就是考虑了消费者的过滤条件,而RocketMQ中队列的作用更偏向于生产者,之后消费的过程再通过订阅关系中的tag过滤或者SQL过滤实现
换句话说:RabbitMQ在入队前过滤,RocketMQ在出队时过滤 具体过滤方式有:
- Tag标签过滤 据网友分析,消息首先基于业务分成多个Topic,而Tag标签是对Topic下又一次细分
我们当然可以将原本topic下的许多tag都升级为Topic,这样无需tag过滤,直接在物理上区分了,岂不美哉?但是问题在于Topic这种资源太重了,一个Topic会注册到nameServer,并且可能在多个broker中存在queue;低频的消息并不适合直接注册Topic;
官网的一张图说明了Topic和Tag的普遍粒度
2. SQL属性过滤 消息过滤 | RocketMQ (apache.org)
适合复杂的场景,RocketMQ兼容了部分SQL语法,便于精准筛选
- Tag标签过滤 据网友分析,消息首先基于业务分成多个Topic,而Tag标签是对Topic下又一次细分
Kafka
不知道从哪里听说过一句话:人类三大发明------火、轮子、Kafka
bash
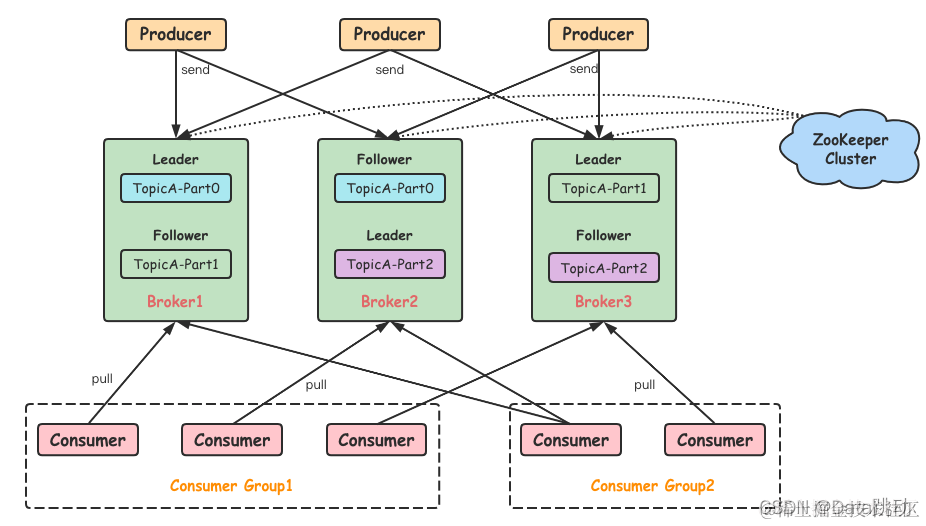典型的Kafka架构和RocketMQ几乎雷同,其中定义的概念也都是(其实应该是RocketMQ大量的参考了Kafka) 以下总结几点架构与RocketMQ不同的点
-
主备 / master-slave / leader-follower 的方式 RocketMQ的主备方案是:按照broker粒度复制出备份来,而Kafka是按照Partition粒度复制到不同的Broker中 RocketMQ
Kafka
如图所示,整个Topic有三个分区P0,P1,P2,副本因子设置为3,即在所有broker中会存有9个partition;对于P0而言,Leader需要和follower分布在不同的broker上;
方式不同可能会带来数据可靠性有所不同,Kafka的多个副本都是活的,而RocketMQ多副本在主从上,主节点失效后需要经过选主才能拉起来slave,其中的延迟可能有潜在问题
-
数据管理的粒度堪称雷同
- RocketMQ中,Topic下就是最小的存储单元MessageQueue,每个Topic就是由多个MessagesQueue组成的;对底层而言,一个broker下每个messageQueue对应多个commitlog,写满一个再写另一个(1G算满)
- Kafka中,Topic下是partition,partition下的segment才是最小管理单元,不同segment对应不同的.log文件(最大也是1G)
二者相比,
-
都是为了能够实现顺序写入,使用日志形式记录消息,并辅以索引文件,用以快速查找
-
RocketMQ和Kafka都在Topic概念下将消息分层(分段)并提出各自的几个概念;分层的意义在于:① 便于利用稀疏索引加快查询速度;② 简化数据管理,例如可以基于段批量淘汰 RocketMQ的MessageQueue,commitlog分别对应Kafka的Partiton和segment
-
查找日志的过程类似,参考博客 什么是kafka segment详解 - 掘金 (juejin.cn)
-
消费方式
- Kafka和RocketMQ的消费者都是通过拉模式从broker获取消息,并且都有长轮询优化;而Kafka让人感觉比较纯粹,使用强大的long polling同时解决实时性和安全性的问题;RocketMQ就像打了一个经典拉模式的补丁,可能有比较适合的场景吧。
-
队列数
据说:RocketMQ单机最高支持五万个队列,而Kafka单机超过64哥队列后性能就会下降(暂无找到测试数据)
Redis
Redis实现消息队列的两种方式是:List(底层是链表) & Streams
- List
rpop命令如果获取不到,会直接返回空,而brpop类似长轮询,获取不到则阻塞在redis
2. Streams
数据结构:
- 有序集合 --- 基数树
- 哈希表 --- listpack
数据流转案例: Stream中,每个消息有消息ID
- 当向Stream中add消息时,将ID插入基数树中,并将消息ID和消息村日哈希表中
- 当一个消费者要消费Stream中消息时,需要一个起始ID,Redis将之后的消息都从哈希表返回并返回给消费者,并从基数树中删除这些消息。
持久化: Redis将这两个数据结构分别保存到两个独立的RDB文件中。
-
什么是基数树(Radix Tree)?
很像之前学过的前缀树
就是一种多叉搜索树,每个非叶子节点表示这支上的前缀 在Redis中,基数树被用于实现消息ID的有序集合;相较于传统有序数组,通过二分查找可以在O(logn)中找到目标ID,基数树通常按照key的长度从root往下遍历节点即可,做到时间复杂度为O(k); 但是很容易想到,这种做法比较适合英文,因为每个节点下最多只有26个节点,这样整棵树即使挂了很多key,公用的路径很多导致内存占用并不高;而中文很明显字符太多了,想要以基数树的方式优化可能需要些转化
参考博客:
-
什么是listpacks
要说为什么出现litpack,就要从ziplist说起
ziplist的设计目的是为了节约内存,传统链表的使用会产生内存碎片,并且next指针空间占用可能也不小;于是出现ziplist这个数据结构;redis中的有序集合,hash,list都直接或间接使用了ziplist(有的使用quicklist,而quicklist空i是双向链表 + ziplist);
-
ziplist的数据结构
一切为了压缩,一切为了连续
ziplist列表结构如下:
yamlzlbytes: zl列表总字节数,32bits zltail: zl列表最后一个entry的指针,32bits zllen: zl列表entry总数,16bits entry: zl列表元素 zlend: zl列表结束标志,8bits ziplist元素entry包括三部分内容: prevlen:前一项的长度。方便快速找到前一个元素地址,如果当前元素地址是x,(x-prelen)则是前一个元素的地址 encoding:当前项长度信息的编码结果。比较复杂,稍后介绍 data:当前项的实际存储数据这种通过 在大范围上取消结构化,小范围上固定含义 的操作其实很常见,在许多为了节约空间的地方都有类似操作,比如说:JVM会将.java文件编译成.class文件,而.class文件的每个字节基本都有固定的意义;MySQL-innodb中存储每行数据的Compact行格式,存储方式也是取消结构化+固定含义
不足之处:
-
查找复杂度高
链表的通病,当查找中间数据时,需要从头或尾遍历
-
transfer时间太长
-
固定大小空间的通病,当像链表中间插入元素时,需要一个比原来连续空间更大的空间,就只能重新申请相应内存空间,并且transfer过去
-
潜在的连锁更新风险 首先我们知道ziplist中每个entry记录着前一个entry的长度,用于反向遍历时找到前一个结点;其中这个pre_entry_length可能占用一字节或者五字节,具体而言是:
- 如果前一节点长度小于254字节,那么使用1字节保存长度
- 如果前一字节长度大于等于254字节,那么使用5字节,第一个是flag,后四个是实际长度
连锁更新的问题是:插入一个比较长的entryA后,entry的next(entryB)的pre_entry_length可能会撑不住;一旦由1字节需要变成5字节,就需要重新申请内存(如果整个内存后面没有被占用的话,只需要将后面的entry都平移一定量,而如果后面以及有内容了,只好将整个空间transfer到新空间),移动后,再去看entryC...最坏场景可能会是O(n2)的时间复杂度。
但是最坏场景的出现比较苛刻,需要后面所有节点长度都小于254,并且大于250;概率非常小,于是官网说:一般情况下,代价视为O(N)
-
quicklist数据结构
双向链表 + ziplist
传统LinkedList和ziplist各有好处和坏处,LinkedList虽然内存消耗较大,但是能够在大数据量下实现低成本的插入和删除,而ziplist虽然内存成本小,但是只适合小数据量,数据规模大时连锁更新风险大,内存移动消耗大。于是出现quicklist
======== 合成 ========
参考博客:
-
listpack数据结构
Entry:
在quicklist中,通过引入列表将原本连续空间打散,从而避免潜在的连续更新;但是quicklist并没有完全解决连续更新的问题,在一个ziplist中O(N2)的成本插入entry也不好受;
listpack在entry中剔除了pre_len属性,从而根本的避免了节点间的影响;
但是没有pre_len,如何反向遍历呢?
无法计算上一个节点的偏移量,就无法准确的从当前entry移动到pre的entry头部;但其实我们一直忽略了一个点,当前entry的pre_length和上一个entry中记录的length是冗余的,或者是如果当前entry获取到上一个节点内记录的length。并且这个length就在entry最后,可以直接指向entry头部,那么就可以通过两步(获取length,再计算到头部)成功去到前一个entry头部;
-
使用 & 生态
RabbitMQ
-
在win下安装RabbitMQ需要首先安装Erlang环境,而对于Erlang这门语言,无论是版本、常见异常、特性等,想必大伙的了解都不如Java或C,所以这就是技术选型中不选它的第一个原因;其次在企业内没有对口的维护人员,对Erlang严重依赖于Erlang社区(语言层面出问题没人担责),所以大企业想必也不会用
-
插件生态:在RabbitMQ中,许多与需求十分接近的功能都通过插件实现;比如说:Managed Plugin用以提供一个Web管理界面,用于监控和管理RabbitMQ服务器,以查看queue、exchange、channel等状态,并且可以进行配置和操作;Federation Plugin是用来搞集群和联邦系统的;Delayed Message Plugin用来实现延迟消息队列,定时任务,延迟重试等等
但是问题在于:这些插件的开发维护都是第三方开发者而不是官方,也就导致生态和社区可能并不可靠;比如演出消息插件作者在:github.com/rabbitmq/ra... 其中issue中记录了一个bug,但contributor给出的解决方案并不成熟,十分复杂
-
Springboot集成为starter,这对我们这些初级开发者而言,几乎可以实现一键使用。
RocketMQ
-
-
重试机制 & 流控机制
-
重试:和RabbitMQ一样,producer发送消息失败也会触发重试操作,不同的是RabbitMQ的重试需要手动实现:当ConfirmCallback或者ReturnCallback回调显示异常,producer端可以对该消息进行处理;
其中,选择同步处理还是异步处理我认为都可以,区别在于异步处理时需要返回能够唯一确认消息的标识 而RocketMQ天然实现了重试机制,并提供同步重试和异步重试两种选择,以及关键参数的默认配置
-
问题:
- 重试并不意味着成功,还是需要兜底策略
- 重试也会带来很多不确定性,比如说由于网络阻塞导致超时未收到ack而引发的重试,就需要在对端解决幂等性问题
- 重试可能会破坏原本消息间的有序性
- 重试最大的诟病是资源占用太多 RocketMQ采用 指数退避策略,给出生产环境下的更优解,简单而言就是:每次重试失败后,等待的时间间隔按指数增长,从而减少重试频率,减去系统负载。
-
消费重试:生产端有重试,消费端也有;消费重试主要解决的是业务处理逻辑失败导致的消费完整性问题;我的理解就是对小概率异常事件的兜底操作;
具体做法是:消费者在消费某条消息失败后,Apache RocketMQ 服务端会根据重试策略重新消费该消息,超过一次定数后若还未消费成功,则该消息将不再继续重试,直接被发送到死信队列中。
官网给出两类使用场景:可见在此做重试是一种性能向业务妥协的操作
- 业务处理失败,且失败原因跟当前的消息内容相关,比如该消息对应的事务状态还未获取到,预期一段时间后可执行成功。
- 消费失败的原因不会导致连续性,即当前消息消费失败是一个小概率事件,不是常态化的失败,后面的消息大概率会消费成功。此时可以对当前消息进行重试,避免进程阻塞。
- 流控机制:当broker容量或水位过高,会通过快速失败返回流控错误,来避免底层资源承受过高压力。(就是微服务调用中的熔断或者限流)
- 流控对当前服务器是一种保障,但是对上层而言 相当于不保障提供可靠服务;RocketMQ官方给出的处理建议有:提前监控 + planB,大意是在流控触发前 调用方可以平滑切换到应急处理系统
-
-
消费者类型
- RocketMQ提供了两类消费者,分别为PushConsumer & SimpleConsumer。本质上是对消费者确保可靠消费的不同策略的封装。 虽然叫Push Consumer,但我怀疑实现方式还是Poll
-
PushConsumer是高度封装,保守主义,约定大于配置的;它的确认方式和RabbitMQ的手动确认方式类似,通过给consumer绑定回调函数 从而得知消费结果;除此之外RocketMQ还为其封装了高并发处理,负载均衡...
实现方式:
由图可知,消费者通过长轮询,get到一批消息存入自身缓存队列中,这种模式和Kafka的Poll方案一致,如果按pushConsumer语义理解为push,那何必使用long polling?都可以类似websocket从broker主动发了岂不是实时性可可控性更好?
-
SimpleConsumer就像RabbitMQ中acknowledge.NONE一样,消息确认需要自行处理;
-
- RocketMQ提供了两类消费者,分别为PushConsumer & SimpleConsumer。本质上是对消费者确保可靠消费的不同策略的封装。 虽然叫Push Consumer,但我怀疑实现方式还是Poll
-
特殊消息类型及实现
-
定时消息 / 延时消息
应用于分布式定时任务,作用类似xxl-job; 个人感觉区别在于:
-
RocketMQ作为中间件更加灵活,使用场景更广泛
-
而xxl-job作为任务调度平台,有UI界面,能够动态修改任务状态,有cron表达式触发任务...许多高级特性,功能更加强大
三十六条特性恐怖如斯 分布式任务调度平台XXL-JOB (xuxueli.com)
-
-
顺序消息 常规我们理解的队列都是FIFO模式,天生消息有序;但是RocketMQ在升级吞吐量的过程中牺牲了自身的天然有序 ------ 一个Topic下可以创建多个队列,消息会根据负载均衡算法进入到不同的队列上,不同队列之间自然无法轻松同步做到FIFO 另外,重试机制也会破坏原本的顺序
RocketMQ的解决方案也挺暴力:既然负载均衡和重试机制这些优化策略会带来问题,那就不优化了,实现顺序消息的方式就是退化成简单直接的方式
- 单个生产者串行的将消息发往一个Topic下的一个Queue,并且单条消息使用同步重试,超过最大重试次数后不再重试(有限的对头阻塞)
-
事务消息 分析下官网给出的分布式事务的几个解决方案
- 基于XA协议,使用事务协调器;上下游调用就是简单直接的二阶段提交
过程如下:
- 用户下订单后预提交,等待四个下游执行完毕后返回确认消息,最后用户提交结果 问题:
- 涉及两波网络通信,多次节点提交;并且时间不稳定;锁定的资源也很多
- 引入消息队列
基本原理:将创建事务和发布事务分成两步操作 用户下订单后,在本地创建订单事务,同时将消息发往消息队列,下游任务异步执行;从而缩短链路,提高并发度 问题:
- 最关键的问题是:如果下游任务失败,上游是无法回滚的;此时保障事务原子性的方案就只有对下游重试,尝试实现最终一致性
- 此外还有些其他场景问题:
3. 针对上图问题,RocketMQ给出它的方案,但我感觉挺鸡肋的
基本原理是:通过2PC的方式确保上游任务确认执行,也保证消息可靠到达RocketMQ,确实解决了图中所示问题 但是2PC的方案感觉并不优雅,在上游占用资源确保可靠就像是加悲观锁一样,上图的问题感觉有点"杀鸡焉用牛刀"。
-
RocketMQ中消费模式的Push & Pull
- 用户可以选择声明的消费者是使用拉还是推,根据上述我们对推拉模式各自的优劣;代码如下:
而风骚的是:RocketMQ底层推拉的实现方式都是拉(还和Kafka一致); RocketMQ的开发者用拉做了一个差强人意的推?还是用拉做了一个更好的推? 传统的推面临消费者OOM的风险,传统的拉有消息实时性不足的弊端;RocketMQ在拉的场景下使用长轮询解决实时性不足的问题,给出了具有实时性,安全性的方案(可能由于看起来像推,就把这种模式称为推模式)
长轮询的逻辑为:
-
消费者的PullMessageService模块发起拉取请求
发起前需要根据消费者当选下消费能力做判断,避免poll来超海量数据
-
Broker中PullMessageProcess模块 从底层查询结果(从磁盘文件ConsumeQueue+commitlog)
-
如果没有查到消息,将长轮询请求挂起
-
在Broker侧,由PullRequestHoldService周期性检查挂起的请求是否有消息准备好,如果有,则唤醒线程,并且通知消息对于offset
-
消息返回Consumer后,再发长轮询(也会根据消费能力动态优化过程)
Kafka
官方介绍:cwiki.apache.org/confluence/... 官方对于Kafka生态给出了很详细的分类,由于我本人没有接触过太多Kafka参与的案例,只能简单解读下官网
Kafka的生态大致分为两类,封装Kafka的产品 & Kafka上下游产品
- 封装Kafka 有许多项目对Kafka进行了在封装,以及根据不同环境的二次开发(比如云端、本地、基于Kubernates)
- Confluent Platform:cnfl.io/cplatform confluent Platform基于Kafka,简化了连接数据源到Kafka,能够使用户专注于如何获取商业价值而不是担心底层机制;其中官网摘出来说明了下Confluent Could cnfl.io/ccloud 一个基于云端托管的服务,对于用户而言更加省心; 阿里云也有Confluent云端实现,对国内企业或开发者会更友好 : www.aliyun.com/product/ali...
- Kafka上下游
-
Kafka Connect: 用于在Kafka与其他系统见进行数据迁移或者执行ETL操作 例如将文件系统中文件全部灌入Kafka的topic,然后将topic中消息导入外部数据库
核心由sources & sinks两部分组成
开源connect列表为:www.confluent.io/developers/...
-
流处理器 Stream Processing: 首先流是Kafka一个抽象的概念,代表一个无界的持续更新的数据集;处理流的程序就是流处理器,就像是在一根水管上依次添加的过滤器一样。
- 复杂事件处理 CEP:github.com/fhussonnois...
- Azkarra Streams:轻量级Java框架,更快构建Kafka Stream应用
others:
-
与hadoop的集成
偷懒复制官网
- Confluent HDFS Connector - A sink connector for the Kafka Connect framework for writing data from Kafka to Hadoop HDFS
- Camus - LinkedIn's Kafka=>HDFS pipeline. This one is used for all data at LinkedIn, and works great.
- Kafka Hadoop Loader A different take on Hadoop loading functionality from what is included in the main distribution.
- Flume - Contains Kafka source (consumer) and sink (producer)
- KaBoom - A high-performance HDFS data loader
-
管理系统
-
Kafka Manager - A tool for managing Apache Kafka.
-
kafkat - Simplified command-line administration for Kafka brokers.
-
Kafka Web Console - Displays information about your Kafka cluster including which nodes are up and what topics they host data for.
-
Kafka Offset Monitor - Displays the state of all consumers and how far behind the head of the stream they are.
-
Capillary -- Displays the state and deltas of Kafka-based Apache Storm topologies. Supports Kafka >= 0.8. It also provides an API for fetching this information for monitoring purposes.
-
Doctor Kafka - Service for cluster auto healing and workload balancing.
-
Cruise Control - Fully automate the dynamic workload rebalance and self-healing of a Kafka cluster.
-
Burrow - Monitoring companion that provides consumer lag checking as a service without the need for specifying thresholds.
-
Chaperone - An audit system that monitors the completeness and latency of data stream.
-
Sematext integration for Kafka monitoring that collects and charts 200+ Kafka metrics
-
Xinfra Monitor - A framework that monitors and exposes metrics showing availability and performance of Kafka clusters and mirrored pipelines.
-
-
其余还有与日志系统集成,与数据库集成,可观测性组件等等,详情见官网: cwiki.apache.org/confluence/...
-
-
参考许多大佬的博客,如有侵权,告知即删