广播变量是分布式共享只读变量
一、广播变量功能
广播变量用来将一个较大的数据对象发送到 Executor 并保存在内存中,同一个 Executor 中的所有 Task 都可以读取且只能读取广播变量中的数据,从而达到共享的目的,避免 Executor 中存在大量冗余的数据
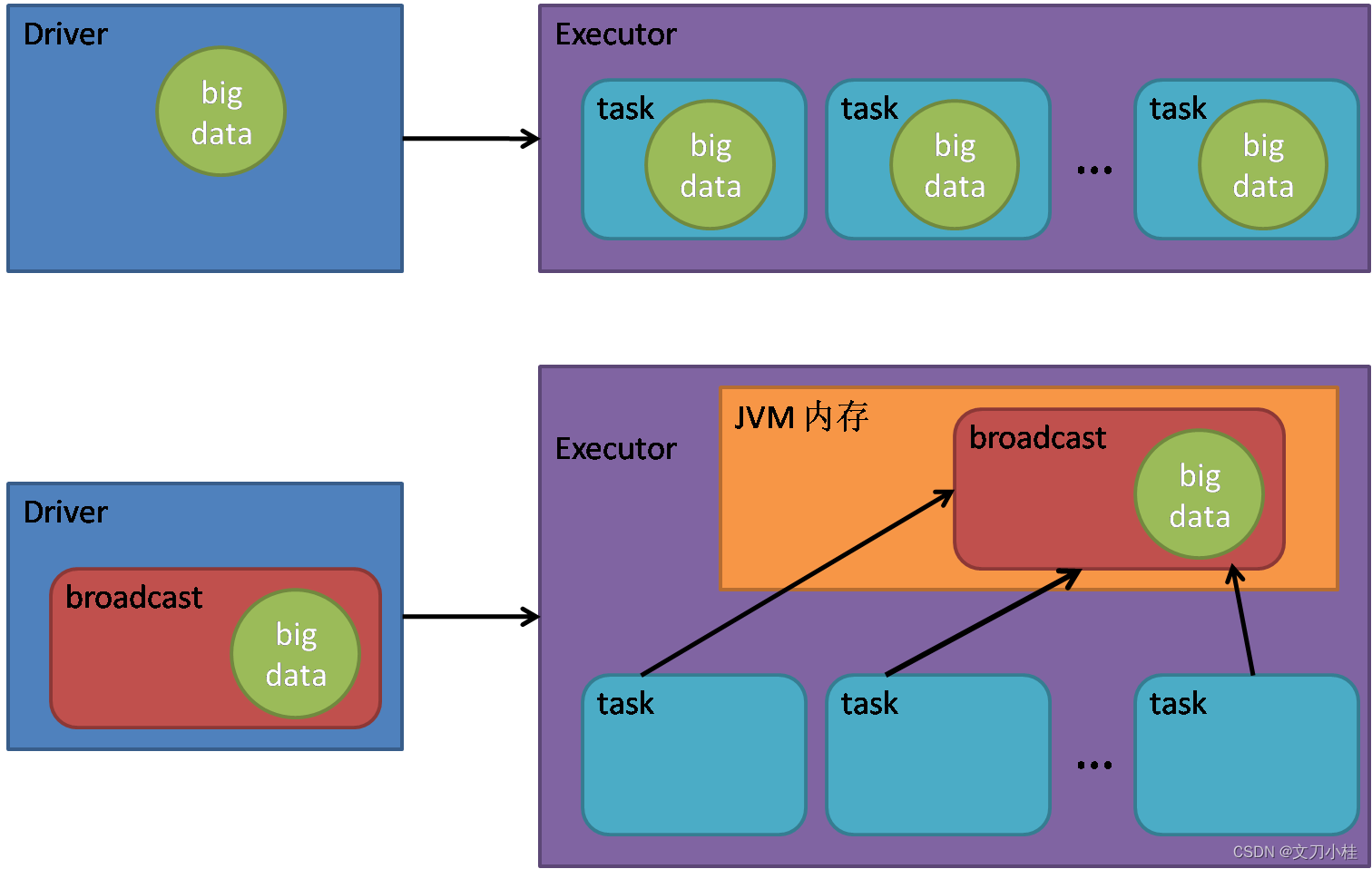
二、使用
scala
object TestRDDBroadcast {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("WCAcc")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(
("a", 1), ("b", 2), ("c", 3)
))
val map = mutable.Map(("a", 4), ("b", 5), ("c", 6))
// 封装广播变量
val bc: Broadcast[mutable.Map[String, Int]] = sc.broadcast(map)
rdd.map(word match {
case (w, c) => {
// 访问广播变量值
val n = bc.value.getOrElse(w, 0)
(w, (c, n))
}
}).collect().foreach(println)
sc.stop()
}
}