02_ES索引规范&kibana
第一站我们先把ElasticSearch整明白
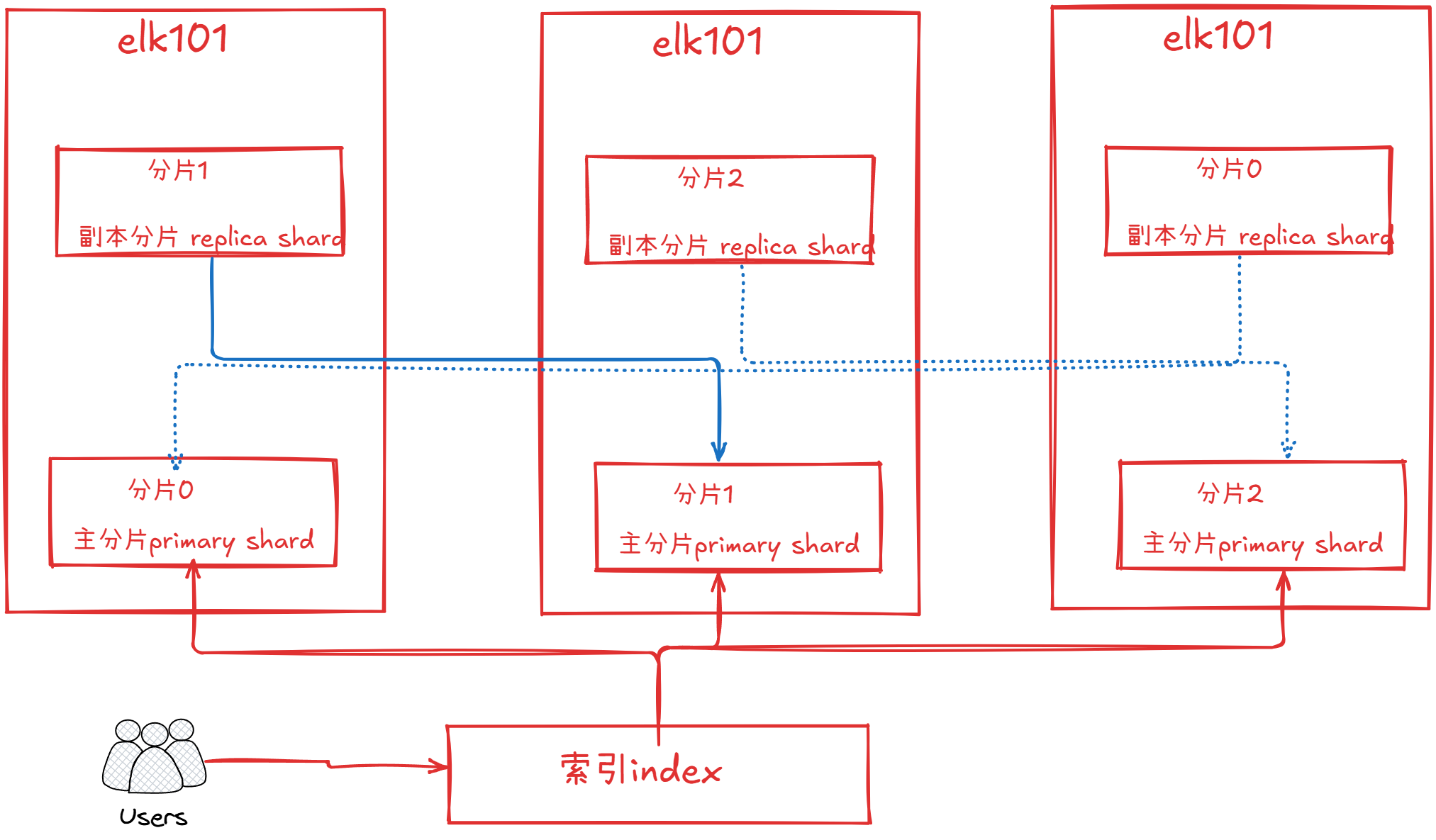
- index索引,用户读取数据的逻辑单元
- shard 分片,将索引的数据分布式存储于es中
- replica副本,为同一个分片提供数据冗余
- 一个索引对应多个分片
- 如果一个分片挂点,那么对应的副本就会立马顶起来干活
总结
副本就是分片的一个备份
主分片和副本分片的区别
主分片可以用于读写操作rw
副本分片可以读取操作ro
集群的颜色
- green
- 所有的主分片和副本分片都正常的额工作
- yellow
- 表示有部分副本不正常的工作
- red
- 表示有部分主分片不正常工作
索引管理
-
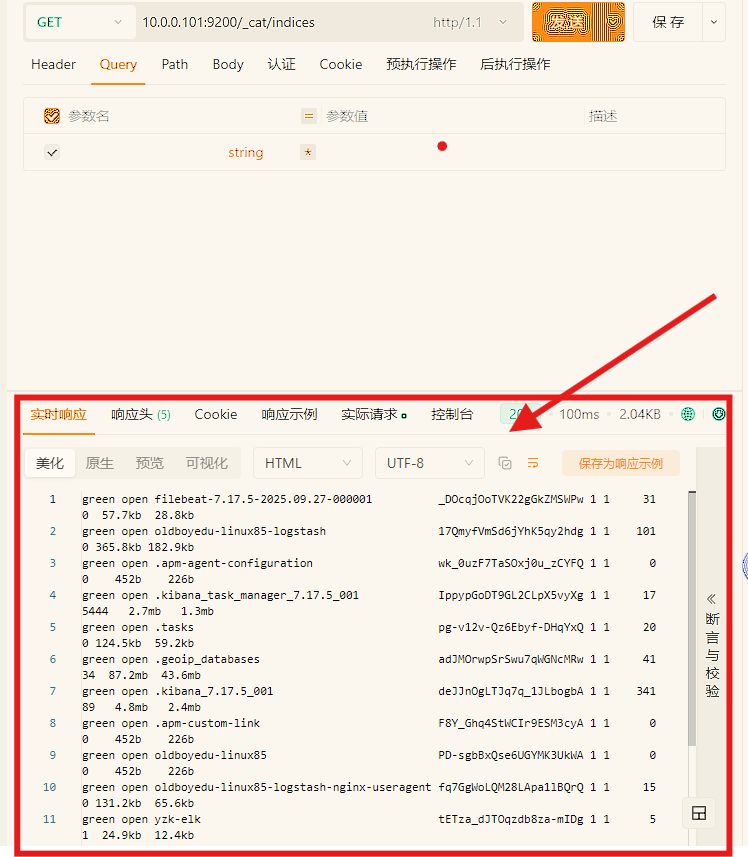
查看索引
curl -X GET 10.0.0.101:9200/_cat/indices
-
创建指定的分片
(1)创建默认索引,默认是一个分片和一个副本
curl -XPUT 10.0.0.101:9200/oldboyedu-linux85curl -XPUT 10.0.0.101:9200/oldboyedu-linux86
{
"settings":{
"number_of_shards": 3
}
} -
创建指定的分片和副本
curl -XPUT 10.0.0.101:9200/oldboyedu-linux87-003
{
"settings":{
"number_of_shards": 5,
"number_of_replicas":2
}
}

5个副本2个分片
修改索引
-
修改副本
curl -XPUT 10.0.0.101:9200/oldboyedu-linux87-003/_settings
{
"number_of_replicas": 1
} -
对于修改分片,不能修改
删除索引
-
删除单个索引
curl -XDELETE 10.0.0.101:9200/oldboyedu-linux87-003
一般不要乱删除。一般多使用索引的关闭就好
-
基于通配符删除多个索引
curl -XDELETE 10.0.0.101:9200/oldboyedu-linux87-*
索引别名
-
添加索引别名
POST http://10.0.0.101:9200/_aliases
{
"actions": [
{
"add": {
"index": "oldboyedu-linux85",
"alias": "Linux2023"
}
},
{
"add": {
"index": "oldboyedu-linux86",
"alias": "Linux2023"
}
},
{
"add": {
"index": "oldboyedu-linux87",
"alias": "Linux2023"
}
}
]
}(2)查看索引别名GET http://10.0.0.101:9200/_aliases
(3)删除索引别名POST http://10.0.0.101:9200/_aliases
{
"actions": [
{
"remove": {
"index": "oldboyedu-linux87",
"alias": "Linux2023"
}
}
]
}(4)修改索引别名POST http://10.0.0.101:9200/_aliases
{
"actions": [
{
"remove": {
"index": "oldboyedu-linux85",
"alias": "DBA"
}
},
{
"add": {
"index": "oldboyedu-linux85",
"alias": "数据库运维工程师"
}
}
]
}
关闭索引
POST 10.0.0.101:9200/oldboyedu-linux85/_close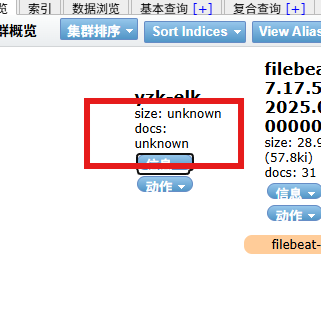
打开索引
POST 10.0.0.101:9200/oldboyedu-linux85/_open文档基础操作
-
创建文档
POST 10.0.0.101:9200/yzk-elk/_doc
{
"name": "李文轩",
"hobby": ["吃鸡","丝袜","rap"]
}
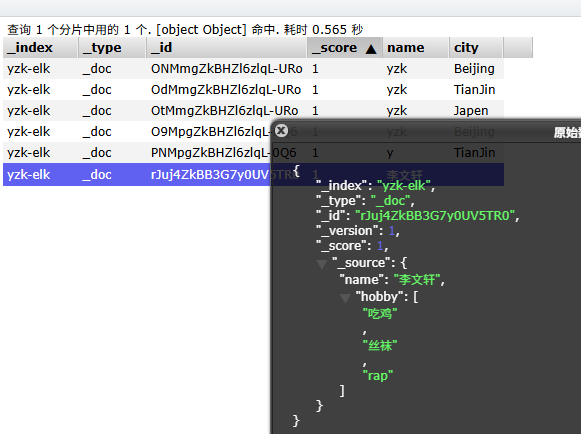
-
指定文档id
POST 10.0.0.101:9200/yzk-elk/_doc/1001
{
"name": "彭斌北京分斌",
"hobby": ["浏览网站","小电影","熬夜"]
}
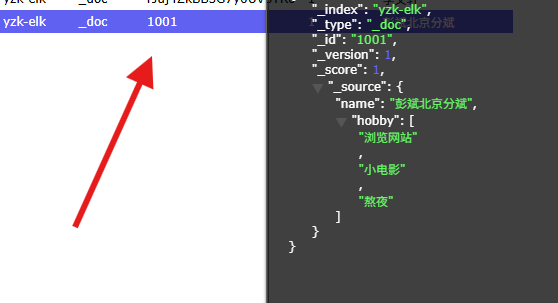
2.文档修改
2.1 全量更新
POST 10.0.0.101:9200/oldboyedu-linux85-student/_doc/YhF3SocBX1qpvxZ-PePd
{
"name": "李文轩2023"
}
2.2 局部更新
POST 10.0.0.101:9200/oldboyedu-linux85-student/_doc/1001/_update
{
"doc":{
"age":20,
"hobby":["抽烟","喝酒","烫头"]
}
}使用mapping自定义数据类型
这个我们了解即可,不需要太深入了解
标准分词器,以及ik分词器
3.1 创建IK分词器目录
mkdir /oldboyedu/softwares/es7/elasticsearch-7.17.5/plugins/ik
3.2 解压软件包
cd /oldboyedu/softwares/es7/elasticsearch-7.17.5/plugins/ik
wget http://192.168.15.253/ElasticStack/day02/softwares/elasticsearch-analysis-ik-7.17.5.zip
unzip elasticsearch-analysis-ik-7.17.5.zip
rm -f elasticsearch-analysis-ik-7.17.5.zip
3.3 重启服务
systemctl restart es7
3.4 测试IK中文分词器
3.4.1 测试IK中文分词器-细粒度拆分
GET http://10.0.0.101:9200/_analyze
{
"analyzer": "ik_max_word",
"text": "我爱北京天安门!"
}
3.4.1 测试IK中文分词器-粗粒度拆分
GET http://10.0.0.101:9200/_analyze
{
"analyzer": "ik_smart",
"text": "我爱北京天安门!"
}
自定义IK分词器的字典
(1)进入到IK分词器的插件安装目录
cd /oldboyedu/softwares/es/plugins/ik/config
(2)自定义字典
cat > oldboyedu-linux85.dic <<'EOF'
德玛西亚
艾欧尼亚
亚索
上号
带你飞
贼6
EOF
(3)加载自定义字典
vim IKAnalyzer.cfg.xml
...
<entry key="ext_dict">oldboyedu-linux85.dic</entry>
(4)重启ES集群
systemctl restart es7
(5)测试分词器
GET http://10.0.0.101:9200/_analyze
{
"analyzer": "ik_smart",
"text": "嗨,哥们! 上号,我德玛西亚和艾欧尼亚都有号! 我亚索贼6,肯定能带你飞!!!"
}kibana安装和部署
-
下载kibana安装包(这里就自己找找)rpm包
-
安装kibana包
rpm - ivh kibana-7.17.5-x86_64.rpm
-
修改kibana的配置文件(# 自己改一下)
vim /etc/kibana/kibana.yml
[root@localhost media]# yy /etc/kibana/kibana.yml
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://10.0.0.101:9200","http://10.0.0.102:9200","http://10.0.0.103:9200"]
i18n.locale: "zh-CN" -
启动kibana
systemctl enable --now kibana
-
访问kibana界面
我这里的主机ip是10.0.0.101
10.0.0.101:5601看一下端口信息
[root@localhost media]# ss -tnl
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 511 0.0.0.0:5601 0.0.0.0:*
LISTEN 0 128 0.0.0.0:22 0.0.0.0:*
LISTEN 0 2048 *:9200 *:*
LISTEN 0 2048 *:9300 *:*
LISTEN 0 128 [::]:22 [::]:*
[root@localhost media]# 
Stack Manager
可视化的界面
仪表盘