介绍
在人像视频生成领域,使用单张图像生成人像视频已经变得越来越普遍。一种常见的方法涉及利用生成模型来增强适配器以实现受控生成。然而,控制信号的强度可能会有所不同,包括文本、音频、图像参考、姿态、深度图等。其中,较弱的条件往往由于较强条件的干扰而难以发挥作用,这对平衡这些条件提出了挑战。在我们关于肖像视频生成的工作中,我们发现音频信号特别弱,常常被姿势和原始图像等更强的信号所掩盖。然而,用弱信号直接训练往往会导致收敛困难。为了解决这个问题,我们提出了V-Express,这是一种通过一系列渐进式下降操作来平衡不同控制信号的简单方法。我们的方法逐渐能够通过弱条件进行有效控制,从而实现同时考虑姿势、输入图像和音频的生成能力。实验结果表明,我们的方法可以有效地生成由音频控制的肖像视频。此外,我们的方法为同时有效地使用不同强度的条件提供了潜在的解决方案。
网络结构图

网络解析
网络主要由Reference U-Net和Denoise U-Net组成
训练Reference U-Net主要是为主体Denoise U-Net提供参考图片的特征信息,以便生成以参考图片一致性的音频驱动图片数字人。
Denoise U-Net两个输入,基于视频序列帧的关键点,带有噪声的视频序列帧 。他们都会先通过特征编码器转换为特征输入到去噪UNet中,视频序列帧通过vae编码器转换到潜在空间,与器通过V-kps引导器生成的特征做相加,作为UNET的输入;而音频的特征和参考图片的特征作为注意力机制嵌入到UNET中。
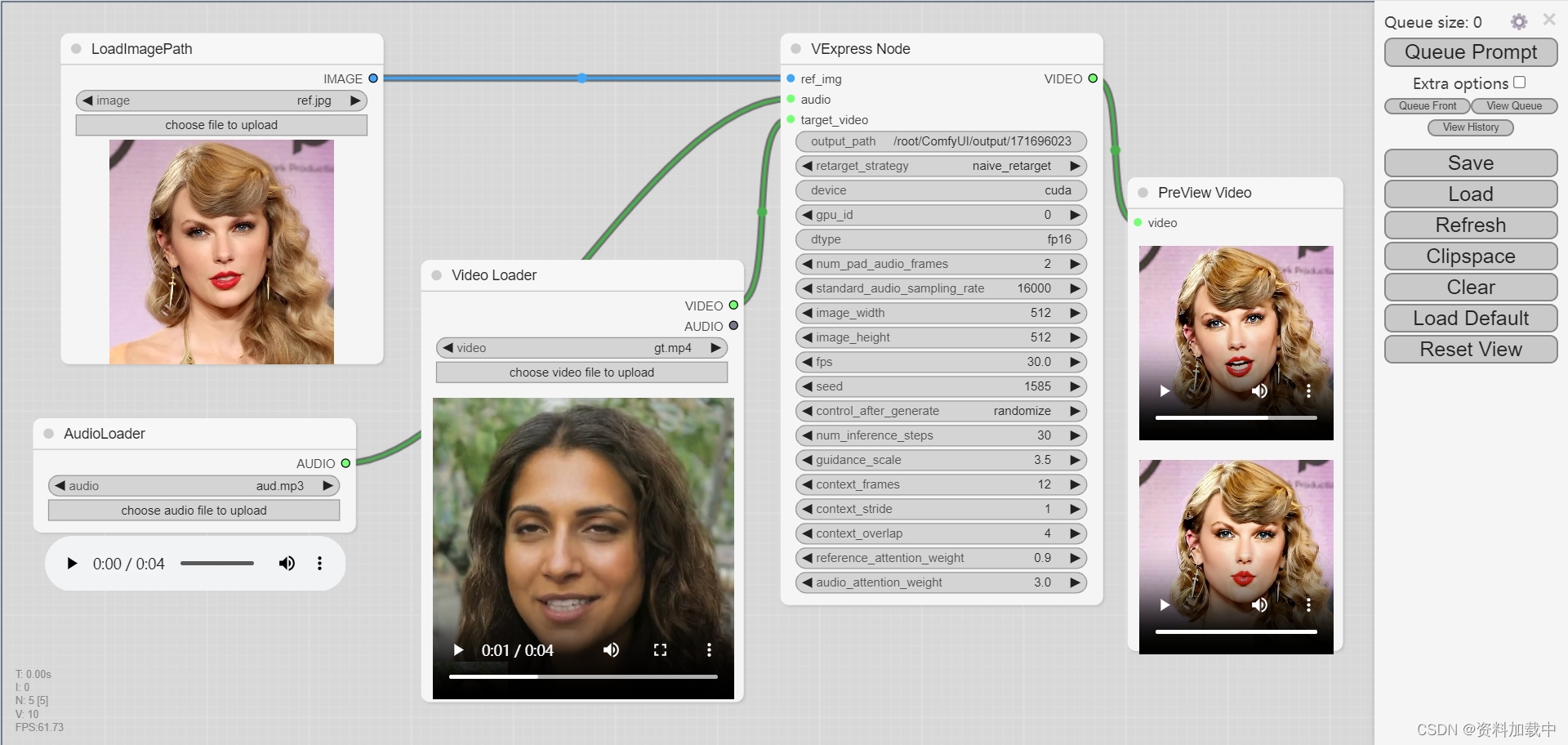
DEMO
github网址:
https://github.com/tencent-ailab/V-Express/
comfyui节点地址:
https://github.com/AIFSH/ComfyUI_V-Express
注意事项
截至目前官方还未公布训练代码,也没有论文