全局注意力结合位置注意力 是学术界与工业界共同的研究热点,它可以有效提升深度学习模型的性能,助力涨点。
这种结合策略充分利用全局注意力(擅长捕捉序列或图像中的长距离依赖)和位置注意力(专注于序列中元素的具体位置)各自的优势,让模型在处理数据时同时考虑元素的内容及其在序列中的位置。这不仅提高了模型的表达能力,还能在保持计算效率的同时增强模型对复杂模式的理解和预测能力。
比如全局位置自注意力网络GPS-Net,通过空间自注意力学习结构化依赖性,并通过通道自注意力捕捉全局有序的语义和位置依赖性,在多个识别任务中超越了SOTA方法。
本文分享全局注意力+位置注意力8种创新结合方案,可借鉴的方法和创新点我做了简单介绍,已经开源的代码都整理了,方便同学们学习。
论文原文以及开源代码需要的同学看文末
Global Positional Self-Attention for Skeleton-Based Action Recognition
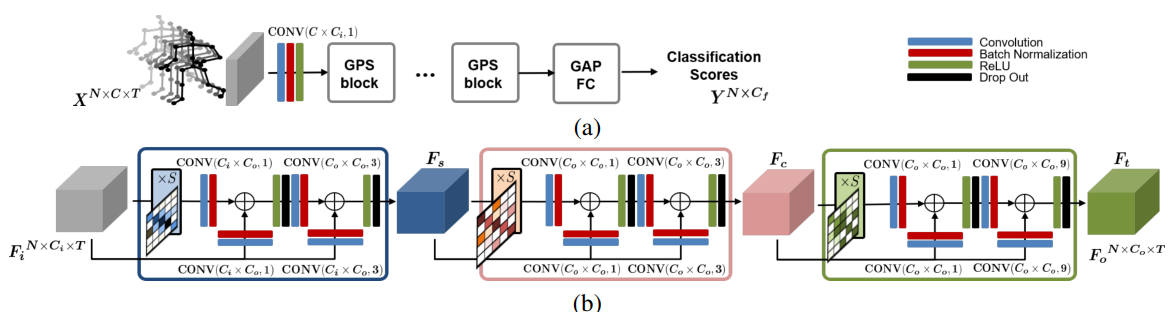
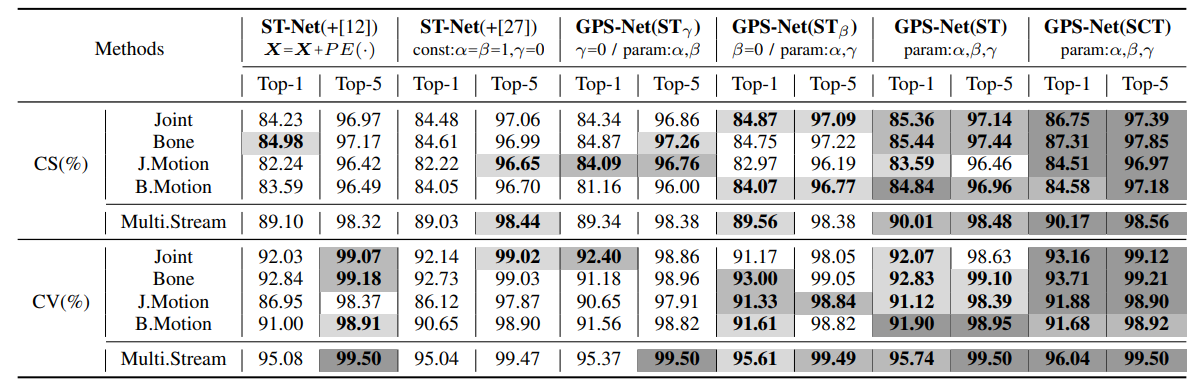
**方法:**论文介绍了一种新颖的全局位置自注意力网络(GPS-Net),可以表示基于骨骼的动作识别中的空间结构依赖和全局有序的语义信息。通过空间自注意和通道自注意,结构依赖和全局有序的语义和位置依赖可以捕获到。
创新点:
-
引入了一种新颖的全局位置自注意网络,通过空间自注意和通道自注意两个模块来捕捉骨骼动作识别中的空间结构依赖和全局语义信息。这种网络结构简单而有效,能够准确地进行动作预测。
-
提出了一种新的结构位置编码方法。通过定义一组基于测地距离的结构位置,将身体关节分成多个部分,并使用同一结构位置编码来编码每个部分的关节。这种编码方法能够反映身体的结构特征,并提高动作识别的性能。
Global Self-Attention Networks for Image Recognition
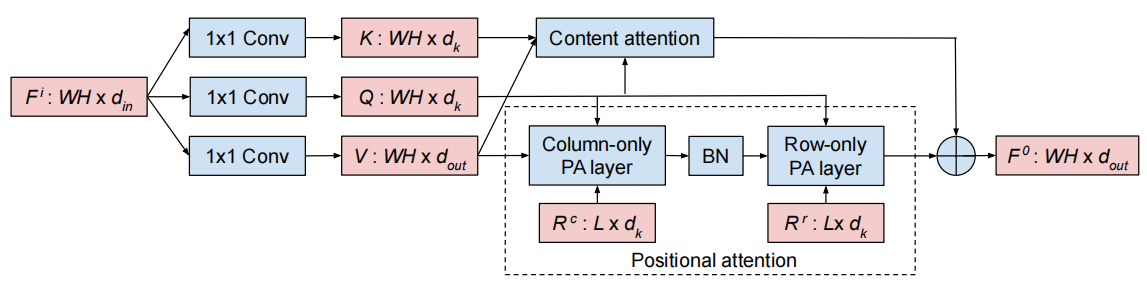
**方法:**论文中提出了一种新的全局自注意力模块GSA,它同时考虑了像素的内容和空间位置。这个模块包含两个并行的层次:内容注意力层:这一层基于像素的内容进行注意力的分配。位置注意力层:这一层根据像素的空间位置进行注意力的分配。
创新点:
-
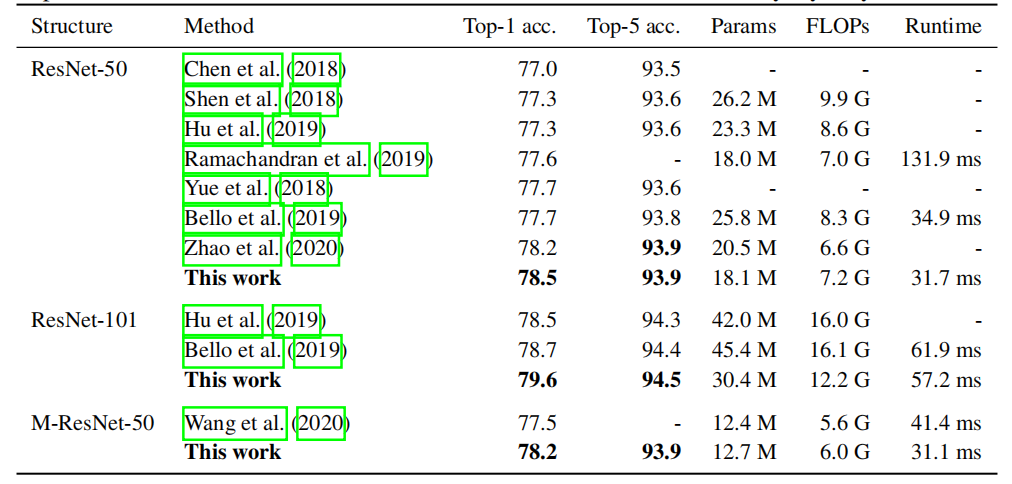
提出了一种新的全局自注意力模块,称为GSA模块,该模块同时考虑像素的内容和空间位置。该模块由并行的内容注意力分支和位置注意力分支组成,最后将它们的输出相加。相比于传统的空间卷积,该GSA模块具有更高的效率,并可以作为深度网络的主要组件。
-
基于GSA模块提出了GSA网络,用GSA模块代替空间卷积来建模像素间的长距离相互作用。相比于使用卷积的网络,GSA网络在CIFAR-100和ImageNet数据集上取得了显著的性能提升,且使用的参数和计算量更少。
Combining Global and Local Attention with Positional Encoding for Video Summarization
**方法:**论文提出了一种新的监督视频摘要方法,该方法结合了全局和局部多头注意力机制,以在不同粒度级别发现帧依赖性的不同建模方式。此外,所使用的注意力机制还整合了一个编码视频帧时间位置的组件,这在生成视频摘要时非常重要。
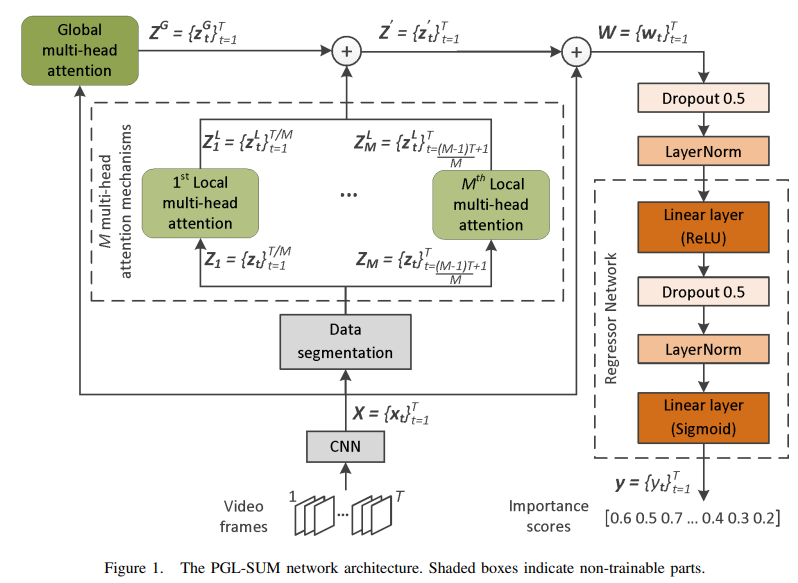
创新点:
-
PGL-SUM模型采用了全局和局部多头注意力机制,以不同的粒度发现视频帧的依赖关系,进而提高视频摘要的性能。
-
PGL-SUM模型引入了绝对位置编码组件,用于编码视频帧的时间顺序,提高了视频摘要的时序连贯性。
-
在SumMe数据集上的实验证明了PGL-SUM模型相对于现有注意力机制的有效性,并与其他最先进的有监督摘要方法竞争性能。
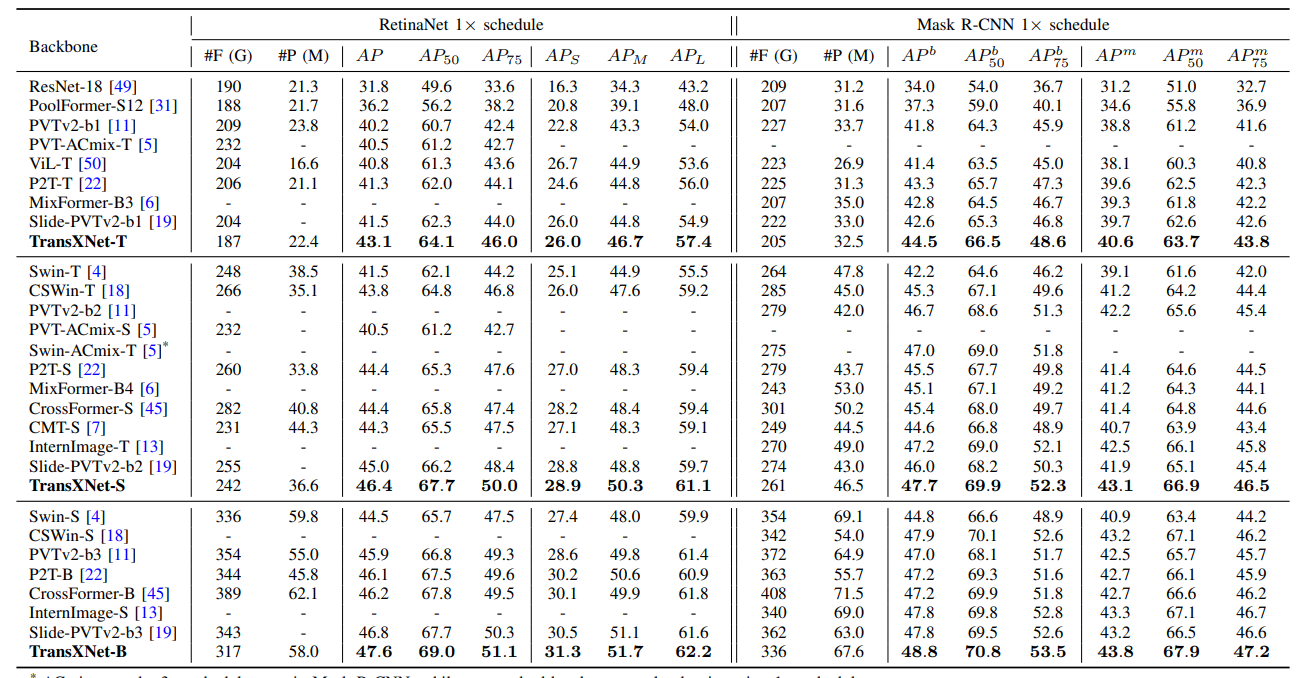
TransXNet: Learning Both Global and Local Dynamics with a Dual Dynamic Token Mixer for Visual Recognition
**方法:**本研究提出了一种高效的双动态令牌混合器(D-Mixer),利用重叠空间降维注意力(OSRA)和输入相关的深度卷积(IDConv)提供的混合特征提取。通过将基于D-Mixer的块堆叠到深层网络中,使用前面块中收集的局部和全局信息动态生成IDConv中的卷积核和OSRA中的注意力矩阵,从而赋予网络更强的表示能力,融合强大的归纳偏差和扩展的有效感受野。

创新点:
-
提出了一种高效的双动态令牌混合器(D-Mixer),利用重叠空间缩减注意力(OSRA)和输入依赖深度卷积(IDConv)提供的混合特征提取。通过将基于D-Mixer的块堆叠到深度网络中,利用先前块中收集的局部和全局信息动态生成IDConv中的卷积核和OSRA中的注意力矩阵,通过融合强归纳偏差和扩展有效感受野,使网络具备更强的表示能力。
-
设计了一种名为TransXNet的新型混合CNN-Transformer网络,通过交替使用D-Mixer和MS-FFN构建。在各种视觉任务中,TransXNet展现出了领先的性能。
关注下方《学姐带你玩AI》🚀🚀🚀
回复"全局位置"获取全部论文+代码
码字不易,欢迎大家点赞评论收藏