React 想实现一个打字机的效果,类似千问、Kimi 返回的效果。调用大模型时,模型的回答通常是流式输出的,如果等到模型所有的回答全部完成之后再展示给最终用户,交互效果不好,因为模型计算推理时间比较长。本文将采用原生 React 写一个简单的组件,调用本地 Ollama 模型进行对话。
服务端实现
由于要流式返回数据数据,正常的 http 请求是一来一回,不会一段一段返回,Websocket 是一个解决方案,Websocket比较重,模型对话只需要单向的返回就可以。所以,OpenAI提供的 API是基于 SSE (Server Sent Event)协议的,SSE 协议采用 Http Chunk Response 实现。下图中可以看到,Response 是 Chunked 编码的。
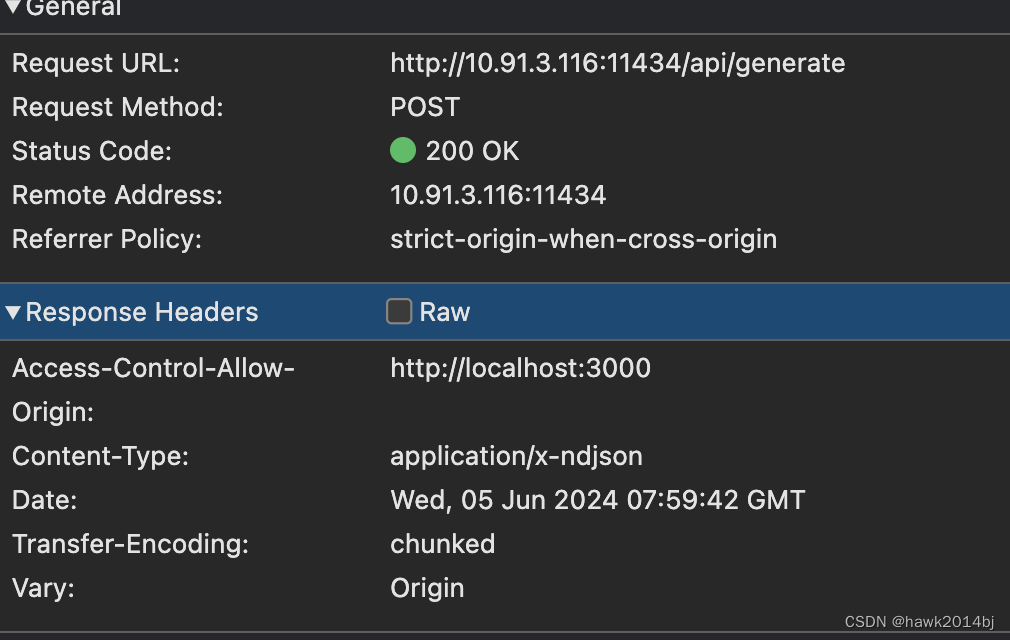
客户端实现
通过 Fetch 调用 Ollama 提供的接口,并对返回进行处理,Fetch API 默认支持 Chunk 编码。由于是流式输出,需要定义从 Reponse body 中获取一个 reader,代码如下:
import React, { useState, useEffect } from 'react';
const ChunkedJSONResponseComponent = () => {
const [responses, setResponses] = useState([]);
const [loading, setLoading] = useState(true);
useEffect(() => {
const fetchData = async () => {
const response = await fetch('http://10.91.3.116:11434/api/generate', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
model: "testllama3",
prompt: "Why is the sky blue?",
stream: true
})
});
const reader = response.body.getReader();
const decoder = new TextDecoder();
#处理返回值
const processChunk = ({ done, value }) => {
if (done) {
console.log('Stream complete');
setLoading(false);
return;
}
const chunk = decoder.decode(value, { stream: true });
const lines = chunk.split('\n').filter(line => line.trim() !== '');
lines.forEach(line => {
try {
const jsonObject = JSON.parse(line);
setResponses(prevResponses => [...prevResponses, jsonObject.response]);
} catch (e) {
console.error("Failed to parse JSON:", e);
}
});
reader.read().then(processChunk);
};
reader.read().then(processChunk);
};
fetchData();
}, []);
return (
<div>
<h1>Chunked JSON Response</h1>
<p>
{responses.map((response, index) => (
<span>{response}</span>
))}
</p>
{loading && <div>Loading...</div>}
</div>
);
};
export default ChunkedJSONResponseComponent;
总结
OpenAI 设计的接口比较简单,后续出来的大模型都遵循了 OpenAPI 的接口格式,感谢各位大佬没有再造轮子。打字机效果实现很简单,由于原生 Fetch API 就支持 Chunk 编码,做对应的处理既可以完成。