 ****
****
万卡 GPU 集群实战:探索 LLM 预训练的挑战
****
一、背景
在过往的文章中,我们详细阐述了LLM预训练的数据集、清洗流程、索引格式,以及微调、推理和RAG技术,并介绍了GPU及万卡集群的构建。然而,LLM预训练的具体细节尚待进一步探讨。本文旨在为您揭秘这一核心环节,提供更为深入的解读。
已构建万卡GPU训练集群并备妥数据,预训练任务启动并非一蹴而就。启动前需精心选择分布式策略,实施高效Checkpointing,故障巡检修复,并考虑弹性训练等优化与容错策略,确保训练顺利高效完成。
本文聚焦大规模LLM预训练,通过Meta OPT、BigScience Bloom、TII Falcon-180B、字节MegaScale及阿里DLRover等案例,深入解析分布式策略、优化方案及容错弹性机制,为您揭示预训练技术的核心奥秘。
二、引言
2.1 训练预估
LLM的预训练成本高昂,常需上千GPU训练数十天。早期百B规模LLM训练Token量仅几百B,如今已跃升至几T级别,如LLaMA-3系列模型,其训练Token数高达15T,显示了技术的飞速进步与投入的巨大增长。
Decoder Only LLM训练时长可通过模型参数量、Token数及训练资源预估。Token的Forward计算量近似为模型参数量的两倍(W代表参数量),为精确规划训练资源提供了有力依据。
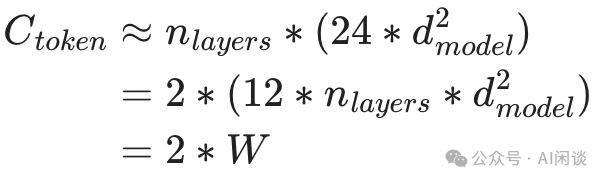
鉴于总计算量与Forward计算量之比通常接近3:1,我们可以精确估算每个Token在训练中的计算量,这一发现与论文2001.08361中关于神经语言模型缩放规律的结论相吻合,为训练效率提供了可靠的数据支持。
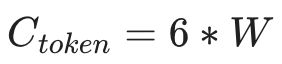
通过Token计算量和资源,可预估训练时长。MFU(模型浮点运算利用率)作为衡量分布式训练效率的指标,为我们提供了训练效率的直观参考。
训练天数计算公式:天数 = Token数 × Ctoken ÷ (GPU数 × FLOPs × MFU) ÷ 86400万。快速估算训练时长。
使用8192个H100-80G GPU和10T Token数据训练175B模型,预估仅需30天即可完成,高效且强大。
10T*6*175B/(8192*1000T*50%)/3600/24=30 天
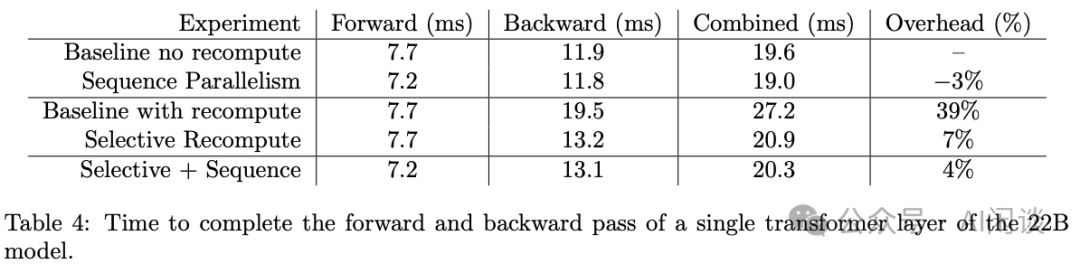
NVIDIA在《Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM》中运用了Activation重计算策略,这一创新要求额外进行一次Forward操作。因此,整体计算量相应增加,为训练大型语言模型提供了高效且规模化的解决方案。
Ctoken =8 * W
在论文2205.05198中,作者对大型Transformer模型的Activation重计算进行了显著优化,基本维持了3:1的比例效率。因此,后续研究仍以此比例为指导。如图Table 4所示,这一优化为实现更高效的大型模型训练提供了重要参考。
2.2 显存占用
训练中显存占用通常包含四个部分:模型参数,优化器状态,梯度以及中间激活。
Adam优化器,融合动量与RMSprop自适应学习率技术,为深度学习模型训练提供强大动力。其独特之处在于能根据参数更新历史自适应调整学习率,显著提升收敛速度并保障训练稳定性。通过维护两个额外参数(或"矩"),Adam为每个参数量身打造优化策略,确保模型训练的高效与精准。
- 二阶矩:基于梯度平方的指数移动平均,反映梯度变化率,实现参数自适应学习率。参数更新依据梯度不确定性,智能调整学习步长,确保参数空间内步进适中,优化效果更佳。
分布式训练中,指数加权平均(EMA)是减少噪声、保障稳定性的关键。尽管EMA引入需额外维护其指数平均值,占用一定空间,但其在提升训练效果上不可或缺,后续计算中可暂时忽略其影响。
- 模型参数高达175B,占用约350GB存储空间。在混合精度训练中,为确保训练稳定并减少误差,常保留一份FP32精度的参数,此时模型参数总量约达750GB,充分保障训练效果与数据安全性。
- Adam优化器状态占用高达700GB(350GB*2),包括一阶矩m和二阶矩v。若采用FP32存储,显存需求翻倍至1400GB,确保计算效能与数据精度。
- 梯度达350 GB。训练时,得益于链式法则,无需永久保存所有梯度。通过边反向传播边更新(如Pytorch默认操作),更新后即刻释放空间,这是显存优化的关键。然而,若采用梯度累积或需梯度常驻的方案,则无法实时销毁,需额外管理显存。
- 激活:相对以上参数会小一些,暂时忽略。
LLM预训练显存占用高达8倍参数量(或12倍),如175B模型占显存1400GB,远超单机8*H100 80G限制。为确保运行,至少需3台8*H100 80G设备,体现了模型训练的硬件挑战与资源需求。
2.3 分布式策略
2.3.1 DP + PP + TP
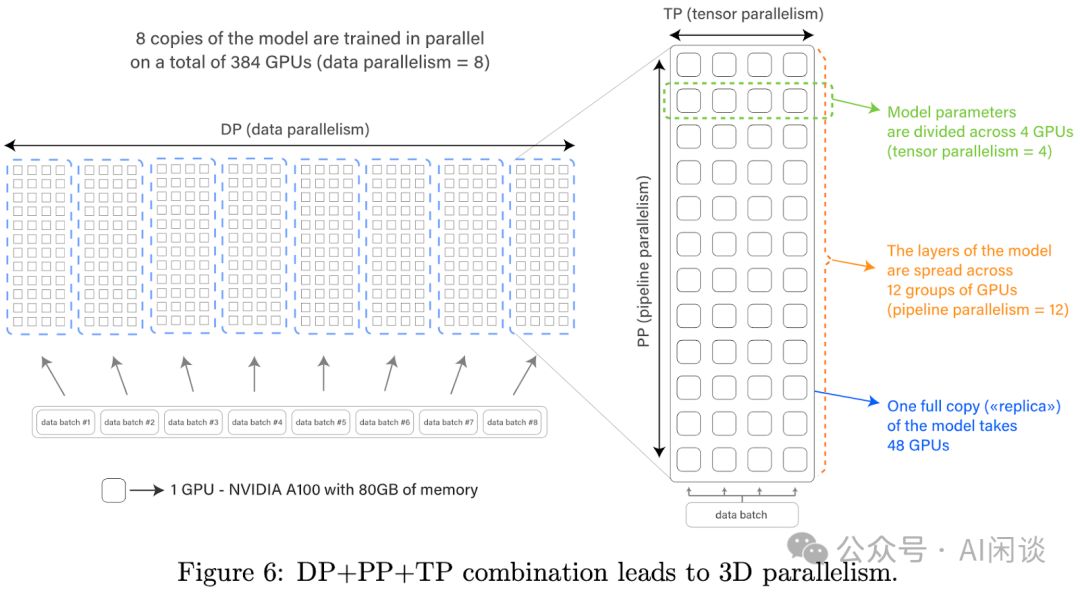
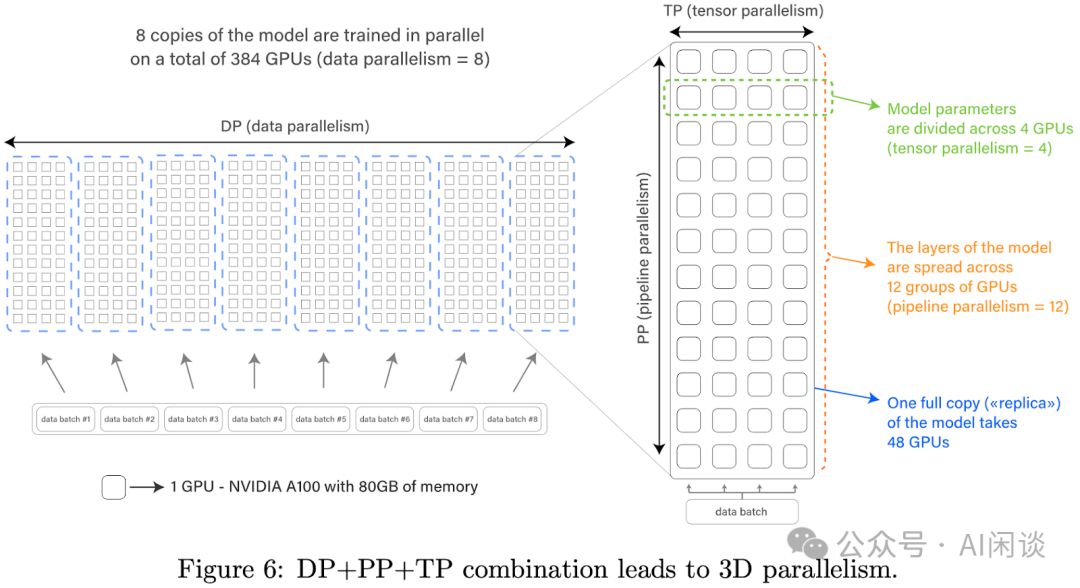
LLM模型庞大,单一GPU或机器难以容纳,故需进行切分处理。同时,为提高训练效率,普遍采用数据并行策略。图6展示了一种经典组合方案,结合数据并行(DP)、流水线并行(PP)及张量并行(TP),实现高效训练。这一策略不仅解决了模型容量问题,还显著提升了训练速度。
- DP切片实现并行处理,每片含完整模型副本,独立处理不同数据。完成训练步骤后,各切片通过All Reduce聚合梯度,并同步更新模型参数。这种策略显著提升了训练效率,确保模型更新的一致性和准确性。
- PP:将模型按照层次切分,不同 GPU 上可以放置一部分的层,通常需要切分尽可能的均衡。由于 Transformer 模型(Decoder)每一层参数量和计算量是固定的,因此相对比较好切分。不过也需要考虑开始的 Token Embedding 和最后 lm_head 中的 World Embedding,因此也有论文中会在第一个 PP 和 最后一个 PP 时让 Transformer Layer 少一点,以便更加的均衡(2210.02414 GLM-130B: An Open Bilingual Pre-trained Model 中的 PP 为 8,共 70 层,中间各 9 层,起始各 8 层)。PP 的通信量相对比较小,因此常常会放在不同的机器上。
- TP技术可将模型如PP切片对应层分散至多个GPU,实现Tensor跨GPU划分。虽通信量增大,但置于单机内可充分利用NVLink高速带宽,优化性能。这种布局最大化机器内部资源,实现高效并行处理。
2.3.2 Zero-DP
为减少显存占用,我们常采用Zero-DP优化技术,包括Zero-1、Zero-2、Zero-3和Zero-offload等方案。这些优化技术源自Microsoft Research的ZeRO & DeepSpeed研究,它们让训练超过1000亿参数的模型成为可能。具体显存占用优化效果显著,为您的深度学习项目提供高效且经济的解决方案。
- Zero-1:在不同 DP 组之间进一步切分优化器状态。
- Zero-2:除了优化器状态外,进一步切分梯度。
- Zero-3:进一步切分模型参数。
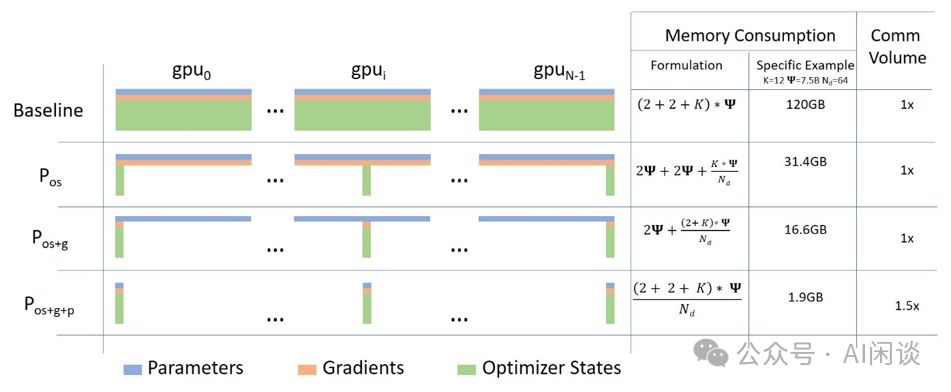
2.3.3 EP
随着混合专家(MoE)模型的普及,其参数量激增。为高效训练,专家并行(EP)策略被广泛应用,即将不同专家分配至不同GPU上,也可与其他切分方案融合。如图6所示,2个专家E0和E1可被切分至4个GPU,每个GPU承载1/4的专家,实现高效并行处理,确保训练过程的高效与准确。
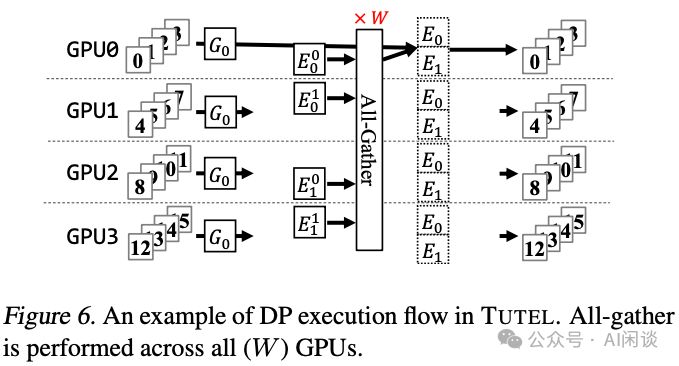
2.3.4 SP
其实有两个序列并行(Sequence Parallel,SP)的工作,一个是 ColossalAI 的 2105.13120 Sequence Parallelism: Long Sequence Training from System Perspective,一个是 Megatron-LM 的 2205.05198 Reducing Activation Recomputation in Large Transformer Models。两者都叫 SP,但是实际上方法不太一样,解决的问题也不同。
ColossalAI SP策略核心在于将序列数据细分为小子序列,并分发至多GPU并行运算。如图Figure 1,长L的序列被切割为N个L/N的子序列,实现N个GPU的高效并行处理,大幅提升处理效能。
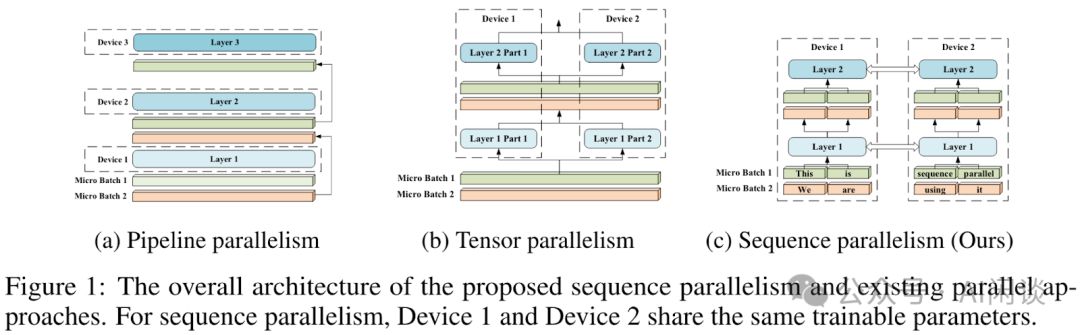
序列间依赖关系需通过图2中的Ring Self-Attention机制实现通信,确保计算结果的等价性,实现高效信息交互。
如图Figure 5所示,Megatron-LM SP专注于解决TP中显存分摊难题。研究发现,LayerNorm和Dropout的输入输出未跨GPU分摊。由于它们在Token间无依赖,可按Sequence维度分割,各GPU仅处理序列部分,实现高效计算。此举显著提升显存利用率,为深度学习模型训练提供新策略。
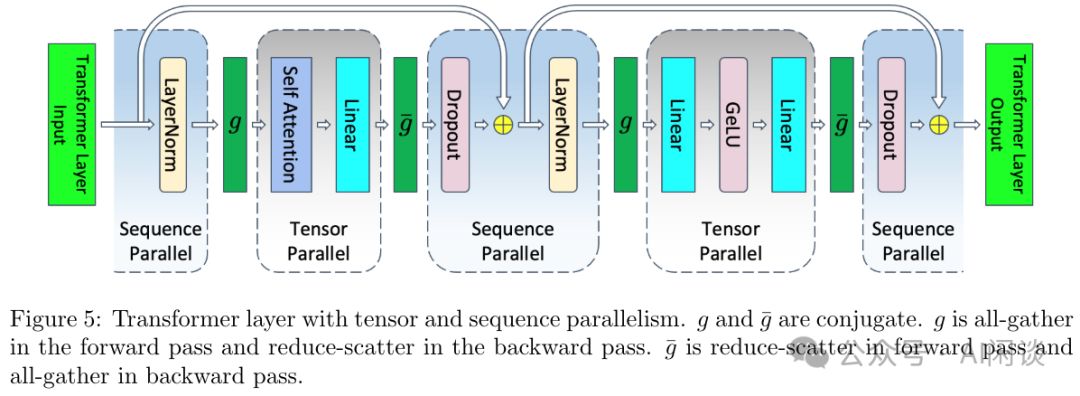
2.3.5 CP
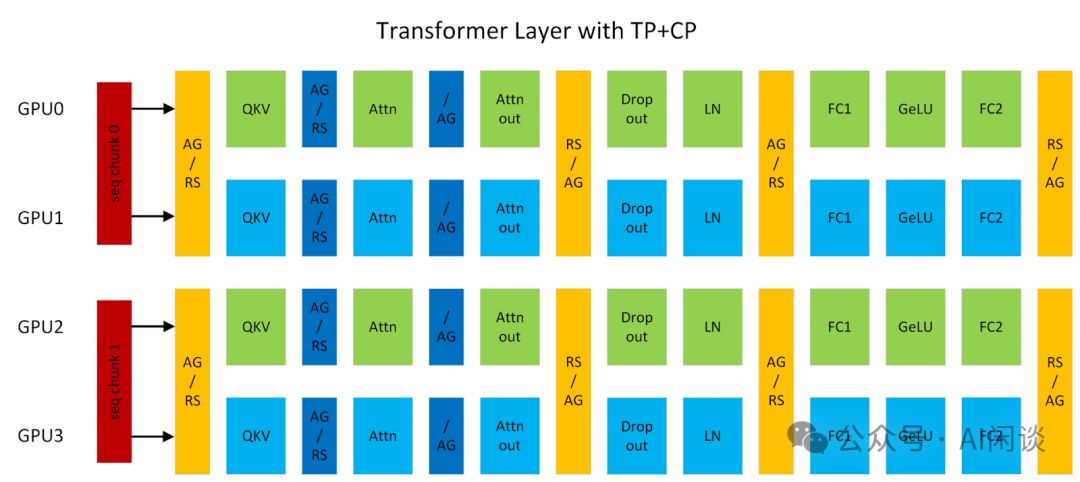
在 Megatron-LM 中还有上下文并行(Context Parallelism,CP),实际上就是 ColossalAI SP,也就是按照输入序列进行切分。如下图所示为 Megatron-LM 中 TP 和 CP 的组合,其中 AG/RS 表示 Forward 为 All Gather,Backward 为 Reduce Scatter;RS/AG 表示前向为 Reduce Scatter,反向为 All Gather。具体可参考 Context parallelism overview - NVIDIA Docs:
2.4 GPU 故障
GPU 故障是大规模 GPU 集群中最常见的问题之一,通常会暴露 ECC Error 或 Xid Code,有关 Xid Code 的错误可以参考 NVIDIA 的官方文档 XID Errors :: GPU Deployment and Management Documentation。也可参考一些公有云平台上的 FAQ,比如 常见 Xid 事件的处理方法--机器学习平台-火山引擎,此外也会提供一些排查手段,比如 自助诊断GPU节点问题-阿里云。
GPU 故障最大的挑战是其数量比较多,故障率比较高,一个 GPU 异常往往意味这个训练任务的暂停,而且通常需要按照整机的方式替换。比如 1 个 GPU 异常,通常是直接驱逐整机。这是因为大规模 LLM 预训练往往要利用单机内高速的 NVLink,如果不是整机调度很可能会影响整体吞吐。假设一天内 GPU 发生故障的概率为 0.1%,则一台 8 卡 GPU 机器每天发生故障的概率为 1-(1-0.1%)^8=0.8%,万卡 GPU 一天内有 GPU 发生故障的概率为 1-(1-0.1%)^10000=99.99%。
三、Meta OPT
3.1 概述
Meta 在 2022 年上半年开源了 OPT(Open Pre-trained Transformer)系列模型,期望复现 OpenAI 的 GPT-3 模型。并且公开模型、代码等,以便促进 NLP 技术在学术、工业界的研究和应用。对应的 Paper 为 2205.01068 OPT: Open Pre-trained Transformer Language Models。除了论文之外,Meta 也公开了其训练的 logbook Meta OPT-175B Logbook,详细的记录了整个模型的训练过程,包括遇到的各种问题,相关的分析讨论以及采取的相应措施等,具有很大的参考价值。
OPT-175B模型依托992台80GB A100 GPU,每台GPU性能高达147 TFLOP/s,MFU占比约47%。为确保训练稳定,我们额外准备了12台备用机器,每日平均替换2台以应对机器异常(故障率1.61%)。这一举措充分展示了我们对训练过程稳定性和可靠性的高度重视。
经过长达两个多月的密集训练,涵盖了从2021年10月20日至11月11日的半月测试期,以及随后57天的正式训练,直至2022年1月6日圆满结束。相较于预期,训练时间超出预估的25天,展现了团队的专业与毅力。
300B*6*175B/(992*147)/3600/24=25 天
在训练中,实际有效时间仅占44%,问题频发。初期任务手动重启达35次,后引入自动重启机制。但硬件故障又触发70+次重启,平均日重启一次。这表明,提高训练效率和稳定性,仍是亟待解决的关键。
3.2 监控&容错
自11-06起,训练任务即已启动,然而至11-11,尽管尝试了多种方案,效果仍未达到预期。据数据记录(OPT/chronicles/10_percent_update.md),此期间共发生10次重启,每种颜色标记一次,彰显挑战之严峻。我们持续努力,力求突破。
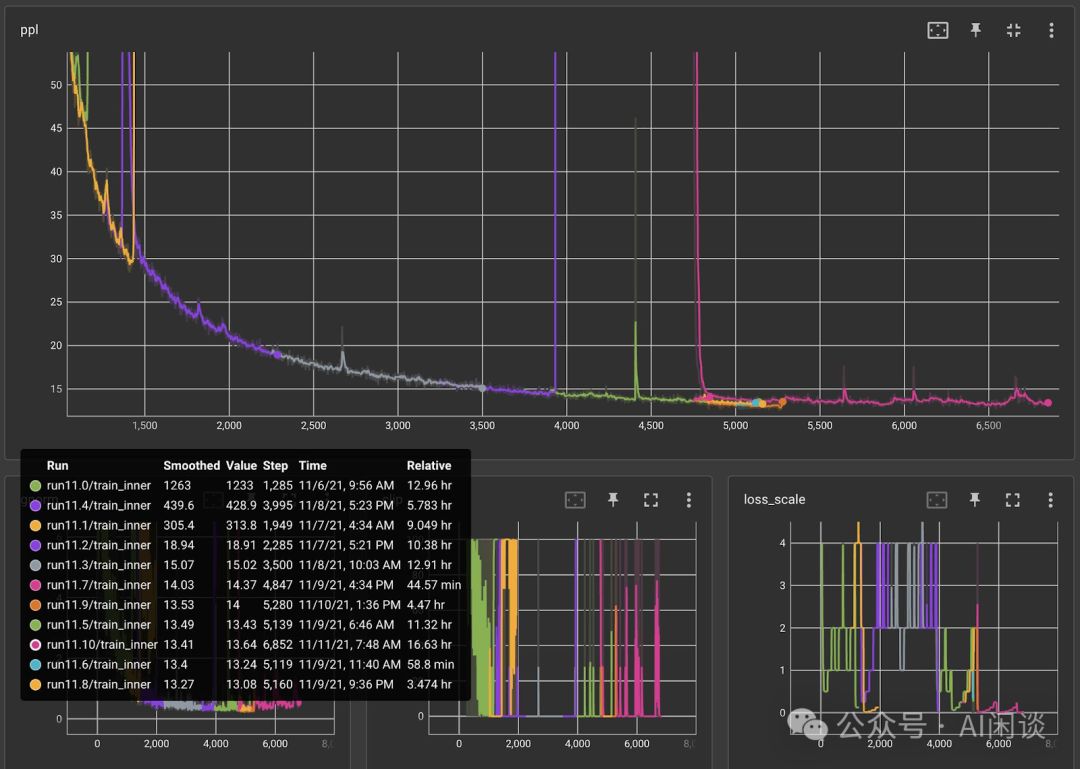
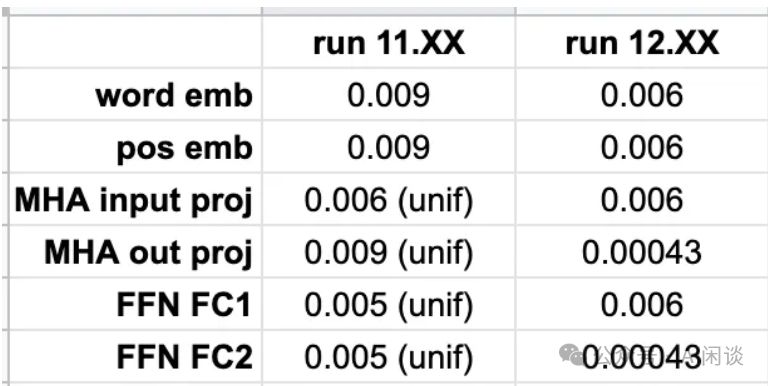
作者经过深思熟虑,决定与OpenAI同步配置,以图为证,11.XX为旧配置,12.XX为同步后新配置,现正式开启11-11训练,从头出发,精益求精。
OPT-175B模型训练中,除配置重训外,常遇硬件异常需重启,如XX%的故障案例源于此类问题,确保系统稳定运行至关重要。
- GPU ECC错误频发,每1-2天就有1/128节点受影响,建议定期重启机器或重置GPU以确保稳定运行。
- 任务异常风险不容忽视,如"p2p_plugin.c:141 NCCL WARN NET/IB:端口错误"的警告提示,直接指向潜在的任务异常,需及时排查处理。
- OPT-175B训练多次遭遇与IB/NCCL问题紧密相关的任务停滞,需人工介入检测,以确保训练顺利进行。
- GPU故障常见表现为CUDA Error或程序异常退出,如"RuntimeError: 捕获到设备4的pin memory线程中的RuntimeError",这些信号均指示GPU可能出现掉卡问题,需及时排查解决。
- 机器异常:GPU 之外的硬件异常,比如硬盘、CPU 等异常,甚至机器直接挂掉。
- 机器配置异常:比如发现某个机器开启了 MIG。
任务异常的核心挑战在于计算资源的显著浪费。尽管Checkpointing机制支持从断点恢复训练,但因其体积庞大且伴随额外开销,需设定合理间隔进行保存。例如,每300步保存一次,异常后仅能从最新点恢复,平均损失150步的计算量。因此,优化Checkpointing策略,对于提升训练效率和资源利用率至关重要。
四、BigScience Bloom
4.1 概述
BigScience 的 Bloom(BigScience Large Open-science Open-access Multilingual Language Model)模型是一个开源、多语言的 LLM。它是众多研究机构和志愿者合作开发完成的,旨在解决多种语言和文化的通用性问题,并鼓励透明度和科学共享,以推动全球研究社区的协作。对应的论文为:2211.05100 BLOOM: A 176B-Parameter Open-Access Multilingual Language Model。
BigScience 也公布了 Bloom 的详细训练 log:bigscience/train/tr11-176B-ml/chronicles.md at master,甚至包含详细的 Tensorboard 记录:bigscience/tr11-176B-logs · Training metrics。其从 2022-03-11 正式启动训练,并在 2022-06-28 完成 1 个 Epoch 的训练。由于还有预算,又接着训练了一段时间,并在 2022-07-04 从 48 台机器切换为 24 台机器。
Bloom训练运用48台搭载8个A100 80G的GPU机器,总计384 GPU,并配备4台灾备机,资源规模不及OPT-175B之半。此次训练处理了366B Token,GPU最高效率达156 TFLOPs,实际运行中保持150 TFLOPs,历时3.5个月。相较于理论上的77天,实际效率达70%,展现了高效的计算能力和卓越的资源管理。
366B*6*175B/(384*150T)/3600/24=77 天
4.2 分布式并行方案
Bloom训练借助Megatron-DeepSpeed框架,融合Megatron-LM与DeepSpeed精髓。其分布式并行方案(8DP 12PP 4TP)如图6所示,显著提升训练效率。此外,还引入了ZeRO-1技术,进一步优化性能,确保训练的高效与精准。
4.3 监控&容错
训练中,作者遭遇硬件挑战,平均每周GPU异常1-2次。为减少损失,每3小时保存Checkpoint,重启时约损失1.5小时计算。同时,PyTorch死锁Bug和硬盘满载问题也导致5-10小时闲置。尽管面临诸多困难,作者仍持续努力,确保训练进程的稳定与高效。
在训练初期,Checkpoint保存间隔较大。然而,2022年3月21日,因GPU异常导致训练中断,浪费了7.5小时。随后,我们迅速调整策略,将保存间隔缩短至每200个Step一次,但次日再次遭遇失败,耗时再增。为减少损失,我们进一步将保存间隔缩减至每100个Step一次,确保每次中断最多仅损失3小时,极大提升了训练效率。
Bloom 训练时遭遇任务停滞问题(2022-04-xx)。为减少无效等待,作者在启动时设定"NCCL_ASYNC_ERROR_HANDLING=1",确保NCCL能迅速终止进程,重启任务。同时,评估任务停滞及任务异常但Slurm未正常退出等问题亦被关注。这些优化措施有效提升了训练效率与稳定性。
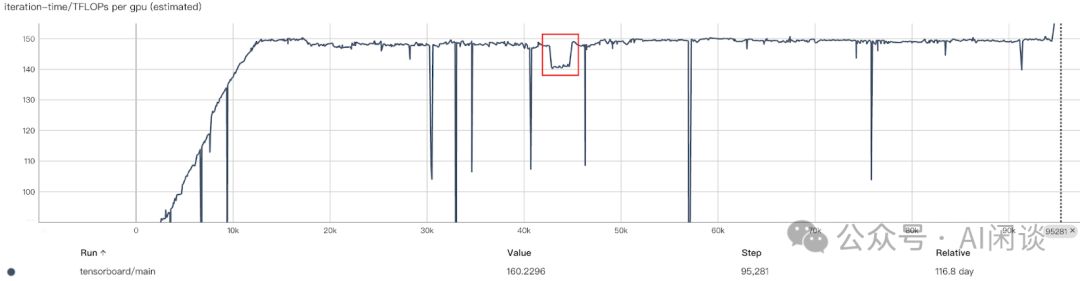
作者也在 2022-04-28 遇到了训练降速问题(上图中的红框),训练吞吐大概降低 5%,GPU 从 149 TFLOPs 降低到 140 TFLOPs。作者怀疑是某个机器存在性能问题,因此停掉任务进行相应的网络吞吐测试,但是并没有发现异常节点。由于正好处于周末,并且手头没有现成的对所有 GPU 进行快速基准测试的工具,只能采用 3 个备份机器逐次替换的方案来找到异常机器。
经过多次尝试后终于发现异常机器,并将其替换,再次重启后恢复到 149 TFLOPs 的速度。(PS:有趣的是,单独测试时该机器的性能只有 2.5% 的降低,而不是 5%,但是将其加入集群再次测试时又能复现 5% 的性能下降)。
五、TII Falcon-180B
5.1 分布式并行方案
Falcon-180B,阿联酋TII的杰作,凭借180B参数,基于RefinedWeb数据集精心训练,完成3.5T Token的累积。采用4096 A100 40G GPU,64DP 8PP 8TP配置,以惊人的43,500 PFLOP/s-days算力支持。若MFU设为50%,训练天数可观,彰显了强大的科技实力与效率。
43500*1000T/(4096*312T*0.5)=68天
按照之前的计算公式得出了和上述一致的结论:
3.5T*6*180B/(4096*312T*0.5)/3600/24=68天
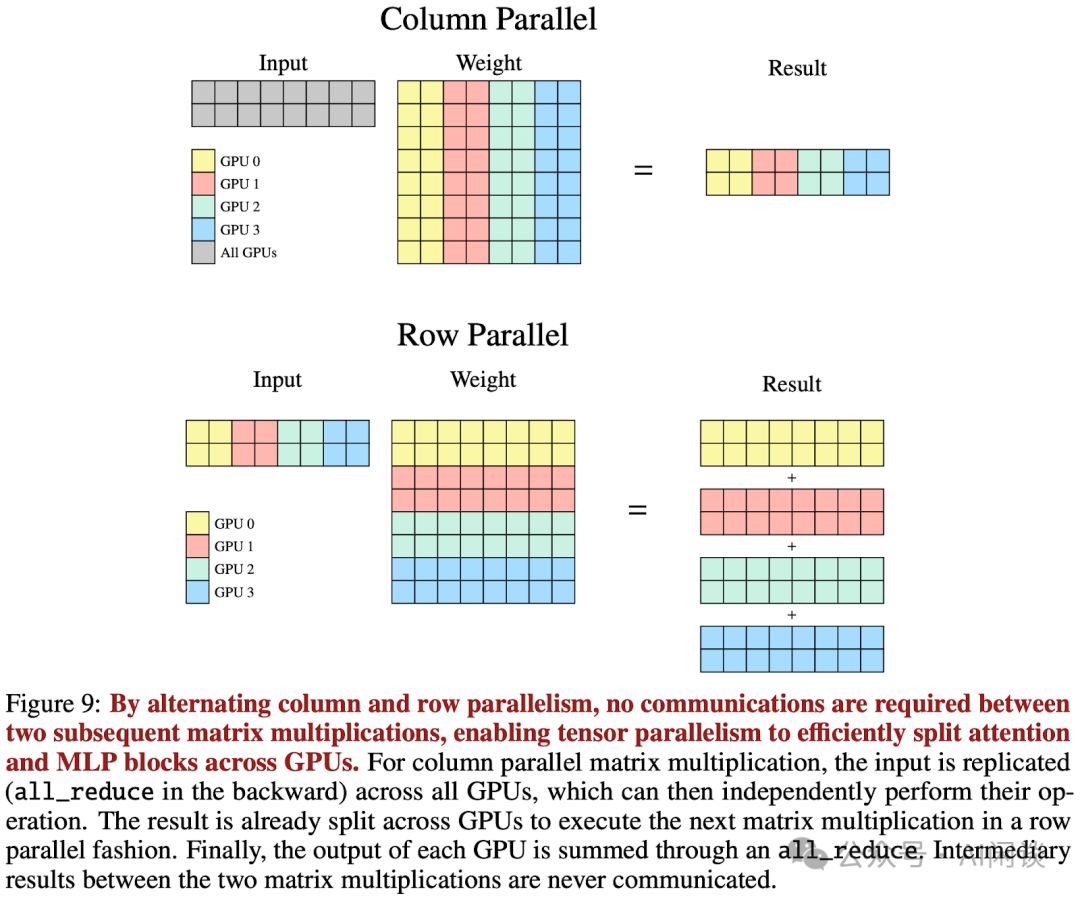
Falcon-180B采用GQA与8KV head设计,实现8TP方案,确保每个KV head独享GPU资源。这一布局充分利用单机内高速NVLink带宽,实现高效通信。在MLP Layer的矩阵乘法处理中,通过先列切后行切的优化策略,减少通信需求,显著提升计算效率。整个系统展现出卓越的并行处理能力和计算效率。
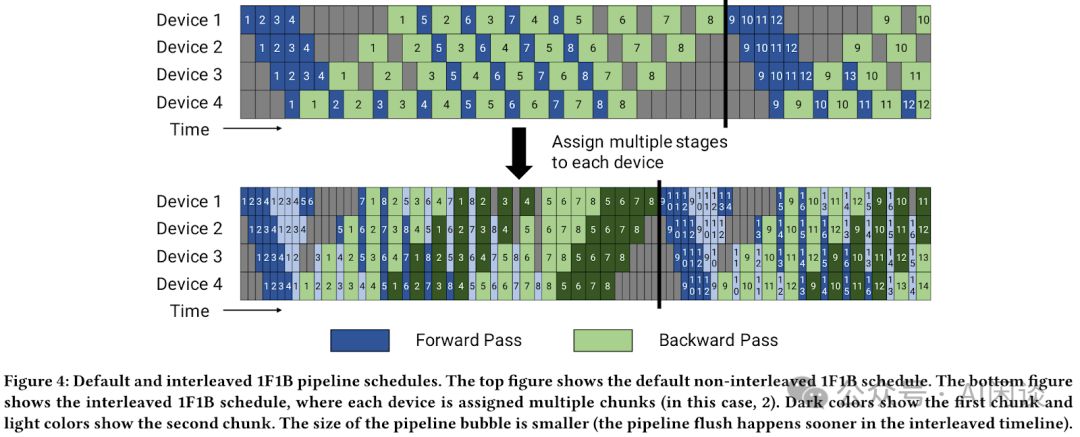
对于流水线并行(PP):作者同样进行了 PP 的切分,使用的 PP 为 8,也就是模型按层切分为 8 个切片。为了减少 PP 中的 Bubble,作者采用了 2006.09503 Memory-Efficient Pipeline-Parallel DNN Training 的 1F1B 方案。
此外,作者也尝试了 2104.04473 Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM 中的 Interleaved-1F1B 方案,当每个 DP 中 Micro-Batch 较小时,Interleaved-1F1B 会有一定收益,但是当 Micro-Batch 比较大时,并没有获得收益。
如图4所示,常规1F1B与创新的Interleaved-1F1B形成鲜明对比。Interleaved-1F1B通过灵活调整Micro Batch的Forward与Backend顺序,显著减少Bubble现象,优化性能。尽管调度策略更为复杂,但其对1F1B的改进效果不容小觑,为数据处理带来了新突破。
在1F1B优化的基础上,为减少通信量,作者还引入了Scatter-Gather优化策略,显著提升效率。
- 然后通过 P2P 通信传输到下一个 PP 切片对应的 GPU 上(跨机通信)。
- 最终,通过All Gather操作,下一个PP切片的所有GPU同步获取全量激活数据(本机NVLink加速)。
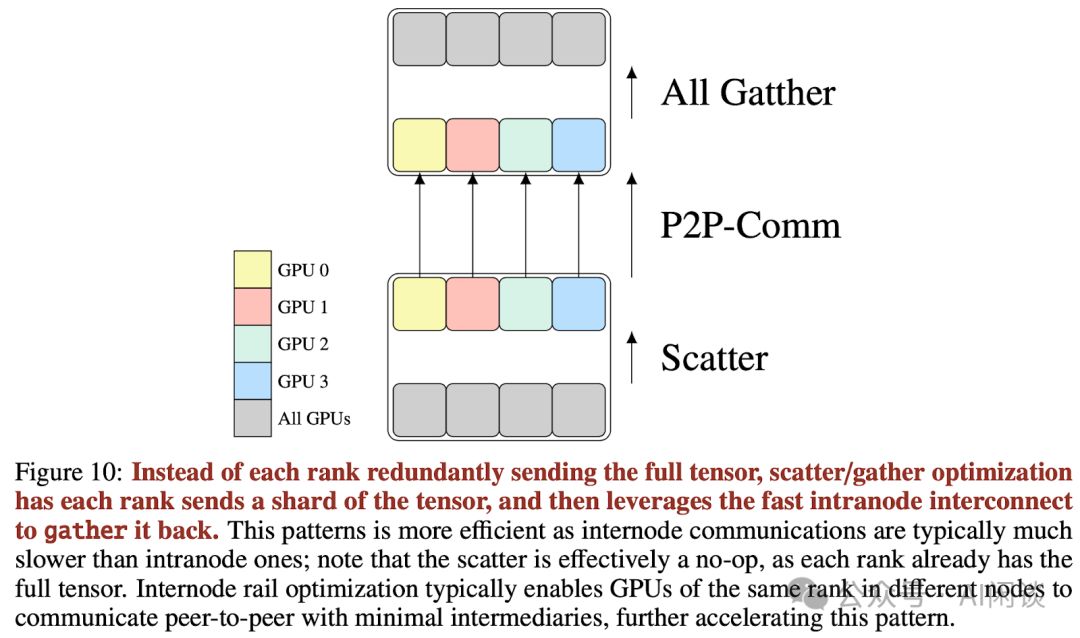
在优化显存占用方面,尽管尝试采用序列并行(SP)结合ZeRO和FlashAttention,但效果并未显著提升,反而略有下降,故未采用SP策略。
数据并行(DP)作为主流并行策略,在TP和PP确定后,需结合资源情况设定DP并行度。特别值得注意的是,DP间的All Reduce会随着Batch Size增大而加重,最终趋近带宽限制,故需全面考量。鉴于拥有4096个GPU,最终DP并行度优化至4096/8/8=64,实现高效资源配置。
5.2 监控&容错
当 GPU 数目比较大时,有一个 GPU 出现故障的概率会急剧增加,比如 4096 GPU 稳定运行一天相当于一个 GPU 连续稳定使用 11 年。作者同样面临了硬件故障的问题,其中主要是 A100 的故障,尤其是 ECC Error 等。但也并不是所有的故障都会返回 Xid Code,通常需要人工测试来捕获,因为它们通常会导致计算返回 NaN。因此,作者在任务启动是会运行一系列的大型矩阵乘法来捕获这些故障。此外,还会启动一些简单的通信测试,以保证网络的正常。
确保任务稳定可靠,监控至关重要。现有Web-Based监控工具如Prometheus,采样间隔较长(15s至60s),易遗漏如毛刺等问题。为解决此局限,作者专门部署了高效可视化工具,实现精准监控,确保任务无忧运行。
5.3 训练损失毛刺(Spike)
在训练过程中,除了稳定性,训练损失波动也需关注。Falcon作者巧妙应对损失毛刺问题,通过恢复最新Checkpoint并跳过1B Token数据继续训练。在训练Falcon-180B时,成功应对了9次此类挑战,确保了训练的高效与准确。
其实 Google 训练 PaLM 模型(2204.02311 PaLM: Scaling Language Modeling with Pathways)也遇到了同样的问题,作者在一个训练中遇到了 20 次的毛刺。针对此种情况,作者会重启训练,并从毛刺之前的 100 个 step 开始,然后跳过 200-500 个 Batch 的数据,通过这种方式,没有再出现毛刺现象。此外,作者也做了消融实验,发现并不是单个数据的问题,而可能是这连续的一系列 Batch 数据引起的。
在2211.05100 BLOOM模型中,为确保训练稳定,研究者创新地引入StableEmbedding Layer。这一策略借鉴了bitsandbytes库,通过在Embedding Layer后增设layer normalization,显著提升了训练稳定性。这一创新方法不仅体现了技术的精湛,更彰显了对训练效果精益求精的追求,为176B参数的多语言模型训练提供了强有力的保障。
如下图所示,是 Bloom 中遇到的毛刺现象:
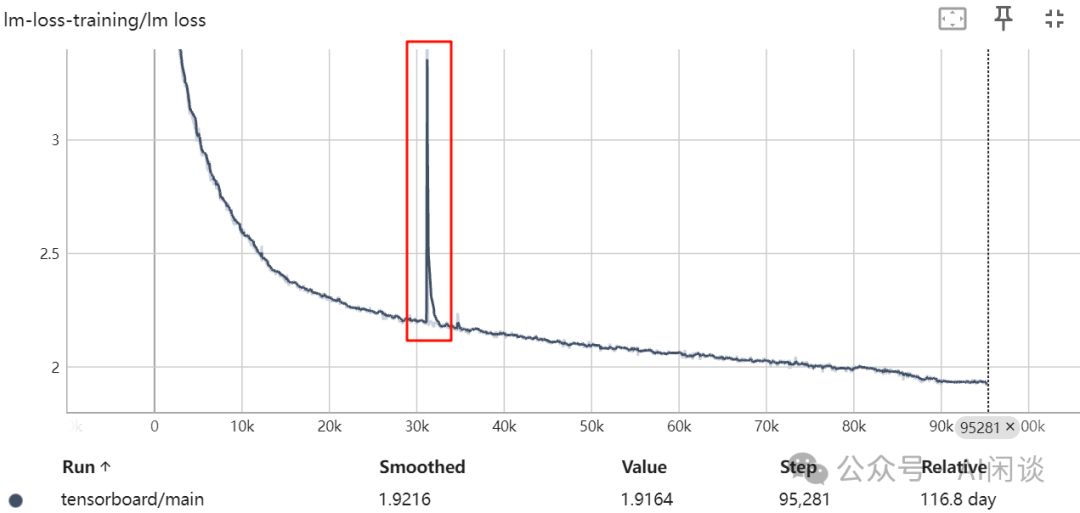
针对训练损失毛刺现象,2210.02414 GLM-130B与bigscience/train/tr8b-104B/chronicles.md已深入探讨与实验。二者均提供了专业见解与实证数据,对于理解和解决这一问题具有重要参考价值。详情请查阅原文,以获取更全面的分析与策略。
六、字节 MegaScale
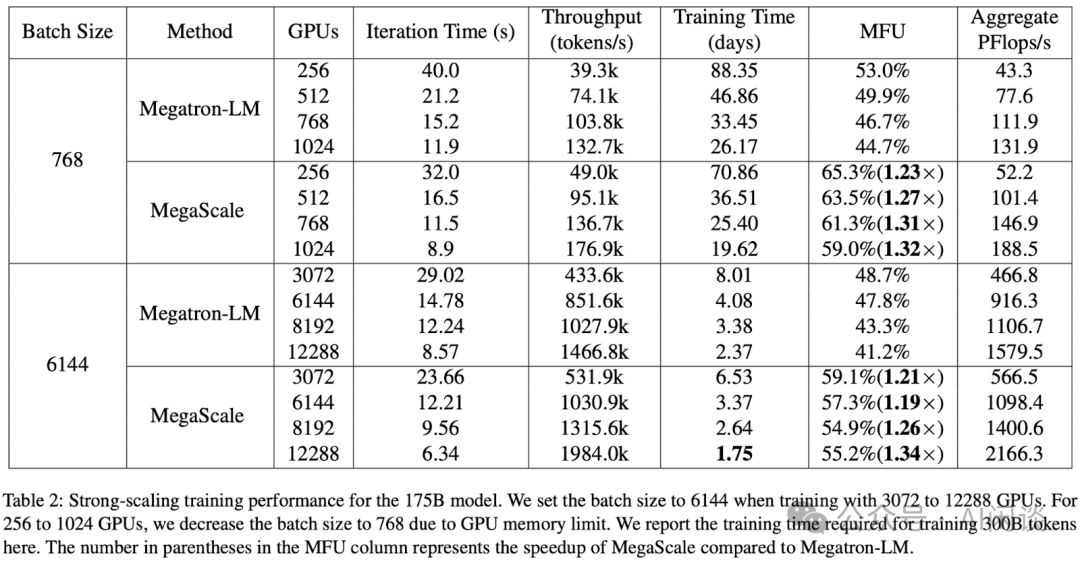
字节在今年 2 月份发表了 2402.15627 MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs,其中详细介绍了万卡 GPU 训练 LLM 的各种挑战和非常全面的优化手段。如下图 Table 2 所示,其最终在 3072 GPU 上实现了 59.1% 的 MFU,在 12288 GPU 上也实现了 55.2% 的 MFU,相比 Megatron-LM 明显提升。
6.1 优化手段
算法优化聚焦三大核心:首先,引入并行Transformer Block,实现Attention与MLP的高效并行处理;其次,应用滑动窗口Attention,显著减少计算负担;最后,采用LAMB优化器,不仅维持精度,还能将Batch Size扩大4倍,有效降低PP中的Bubble问题。这一创新使得MegaScale在PP Bubble上减少了高达87.5%的损耗,为大规模计算提供了更为高效、稳定的解决方案。
通信优化涵盖分布式DP、PP的overlap,以及TP与SP间的高效重叠,三大关键方面助力实现通信效率的大幅提升。
通过采用FlashAttention-2及LayerNorm与GeLU的算子融合技术,显著提升了算子优化效果。
数据处理优化关键于异步加载与共享机制。异步数据加载能在 GPU 同步梯度时处理下一轮数据,有效隐藏处理成本。同时,由于 TP 组在同一机器内共享数据,我们实现 DataLoader 的跨机器共享,并将数据存储在共享内存中,让每个 GPU Worker 直接从共享内存加载,极大提升数据处理效率。
字节对集合通信初始化进行了显著优化,解决了 GPU 规模扩大时,使用 torch.distributed 进行 NCCL 初始化的高昂开销问题。在 2048 Ampere GPU 上,初始化时间从原先的 1047 秒锐减至 361 秒,效率大幅提升。同时,全局 barrier 的优化也实现了复杂度从 O(n²) 到 O(n) 的跨越,进一步提升了系统性能。这些优化确保了在大规模 GPU 环境中,计算任务能更高效地执行。
6.2 监控&容错
面对万卡级别的训练挑战,软硬件故障频发。为确保训练稳定,作者创新构建自动故障检测与秒级恢复机制,实现高效容错,大幅减少人工介入,保障训练流程的高效与安全。
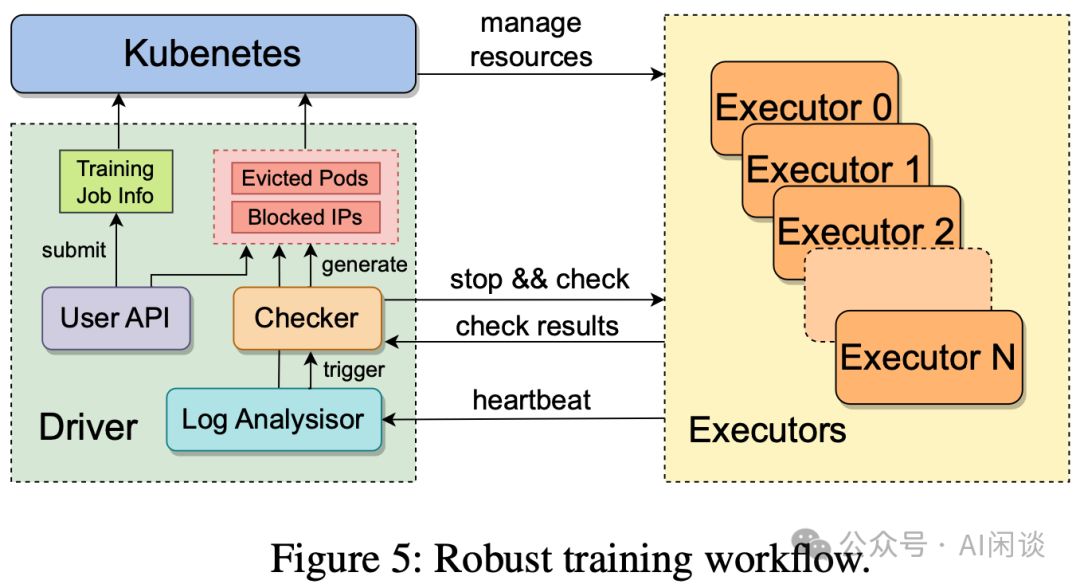
如图Figure 5所示,作者构建了一套高效稳定的训练流程。用户提交任务后,系统自动在各GPU上创建训练Executor,并伴随训练守护进程,定期向Driver发送包含多种信息的心跳信号,以实现实时异常检测与告警。若Driver在指定时间内未接收到心跳,将自动启动故障恢复流程,确保系统稳定运行。
- 暂停所有训练的 Executor,并执行一系列的自检诊断。
- 一旦发现异常机器,立即剔除并替换为等量健康机器。同时,提供用户接口,支持手动识别并剔除异常机器,确保集群高效稳定。
- 机器恢复后,将自动从最新Checkpoint恢复训练。作者已优化Checkpoint的保存与恢复流程,确保训练进度几乎不受影响,高效便捷。
通过上述的守护进程,可以收集详细的信息用于数据分析。其心跳信号包括 IP 地址,Pod 名字,硬件信息等,还包含当前的训练进度信息。除此之外,训练进程的 stdout/stderr 日志也会被收集,以便进行实时的聚合、过滤和分析。如果识别到 warning 或 error 等关键字,Driver 将实时的上报这些诊断信息。最后,RAMA 的流量指标也会包含在内,以便更好的识别网络利用率和通信效率。为了增强对训练稳定性和性能的监控,字节开发了一个精确到毫秒级的监控系统,以便进行更全面的评估。
自检诊断流程精准高效,作者巧妙平衡诊断时长与准确性,采用轻量级测试,全面覆盖软硬件故障,确保训练过程无忧。
- 机内测试:
- 回环测试:全面测量机器内RAMA网卡至内存、GPU等端点的回环带宽,实施full-mesh测试,覆盖所有链路组合,精准识别PCIe配置中的潜在链路问题,确保系统性能稳定可靠。
- RNIC-to-RNIC测试精准评估机内RNIC间连通性与带宽性能,确保速度规格达标,及时发现潜在路由问题,保障网络高效稳定。
- NCCL测试精准高效,包括机内All-to-All测试与TOR交换机间All Reduce测试,旨在迅速识别并解决潜在硬件故障与性能瓶颈。
Checkpoint保存与恢复优化,采用两阶段高效方案。第一阶段,GPU训练进程迅速将显存状态写入主机内存,借助高速PCIe带宽,仅耗时数秒,确保训练无间断。第二阶段,后台进程异步将状态同步至HDFS分布式文件系统。此方案确保训练连续性与数据安全性,极大提升效率。
在训练过程中,作者还发现 MFU 会随着训练的迭代逐步下降,但是单独测试机器的性能又没有发现明显的差异。为了诊断这些问题,作者开发了一个性能剖析工具,其会记录每个训练 Executor 中关键代码片段的执行时间。与 torch profiler 和 Megatron-LM timer 不同,作者的工具基于 CUDA events,可以最大程度减少对 CUDA 同步的需求,从而避免性能下降。通过 profiler 工具,作者发现训练过程中有 0.5% 的机器性能较差,驱逐这些机器后 MFU 变得很稳定。
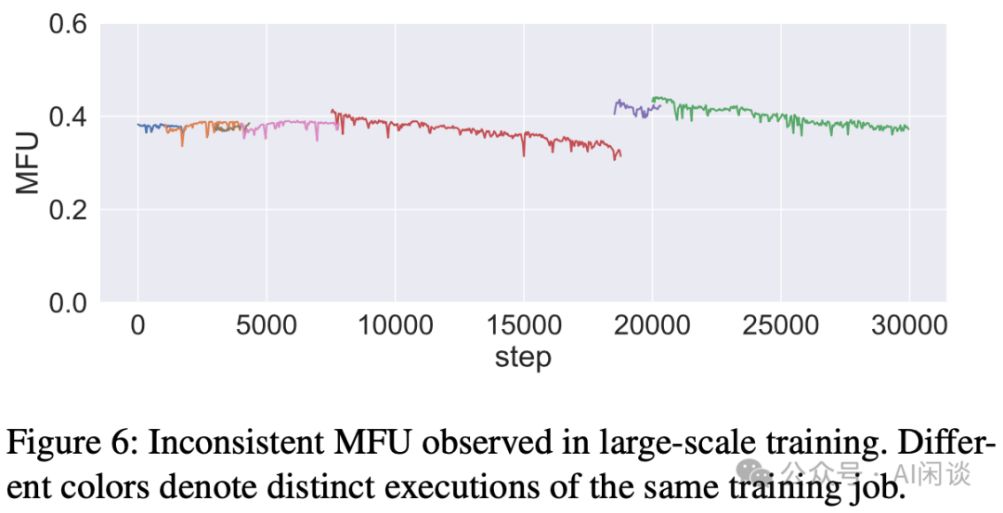
可视化工具能呈现DP、PP、TP等多种分布式视图,如图8所示,直观展示了PP数据依赖关系,助您轻松洞察数据流向与关联。

- 为了提升基于NCCL通信库的多机RDMA网络性能,在HPC测试中,建议增大超时阈值。NCCL_IB_TIMEOUT的可调范围为1-22,尽管NCCL 2.14版本后将默认值从14提升至18,但推荐设置为22以优化性能。需要注意的是,有推荐设置为23的情况,但需谨慎调整。火山引擎GPU云服务器助力您轻松应对高性能计算挑战。
- 核心问题在于网卡、AOC电缆与交换机间链路质量不佳。通过强化网卡信号、AOC电缆质量及交换机侧信号的质量管理,我们成功将抖动频率控制在可接受范围内。
除了 NCCL_IB_TIMEOUT 之外,也可以关注 NCCL_IB_RETRY_CNT 的配置,表示重试次数,默认配置为 7 即可。奇怪的是,NCCL 官方文档并没有介绍 NCCL_IB_RETRY_CNT 的范围,不过其对应的值为 3bit 数值,最大也就是 7,不确定超过 7 后会怎么处理,可以参考如下图所示的 issue NCCL only use RDMA_WRITE/READ why it still got opcode 0 error 12 err · Issue #902 · NVIDIA/nccl · GitHub:

七、DLRover
7.1 概述
阿里针对大规模LLM训练难题,推出DLRover------一款自动化分布式深度学习系统。DLRover具备容错、Flash Checkpoint及弹性能力,确保训练稳定高效。同时,计划开源其性能分析工具xpu_timer,进一步提升训练效率。立即体验DLRover,轻松应对大规模LLM训练挑战。
7.2 容错&自愈
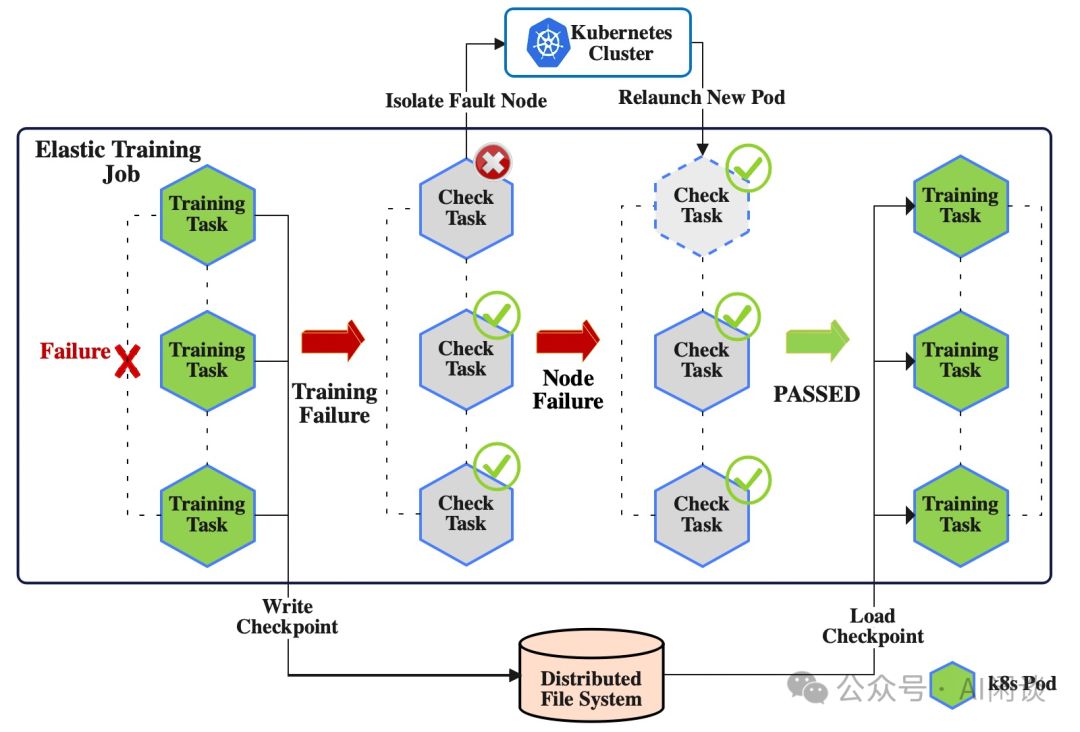
DLRover通过自动节点检查与训练进程重启,显著增强训练稳定性,实现故障自愈,有效降低人工运维成本,优化流程高效便捷。
- 任务失败后保存 Checkpoint 并启动故障检测。
- 检测到异常机器后会驱逐并找到新的机器替换。
- 重新检测正常后重启任务,加载最新的 Checkpoint 继续训练。
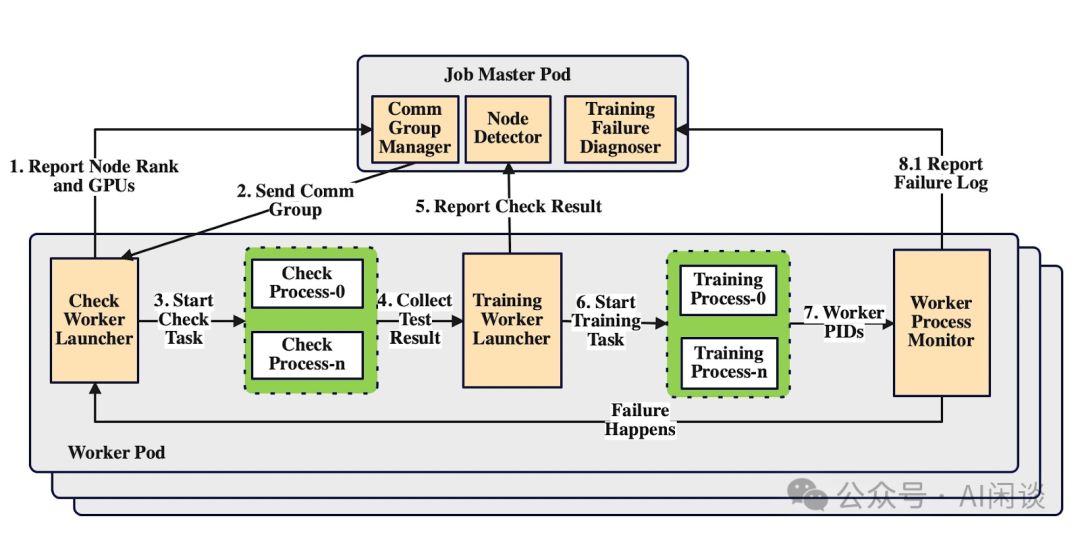
机器检测流程高效精简,每个GPU启动子进程执行轻量级任务,涵盖矩阵乘法与All Gather操作,确保高效数据处理。
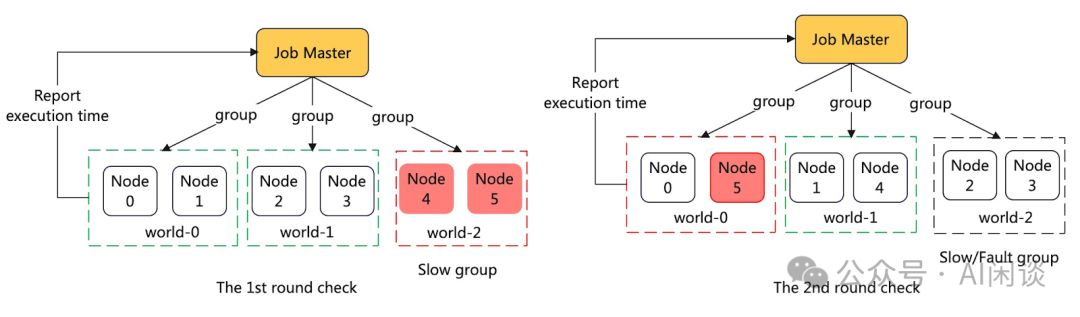
检测过程中,Job Master巧妙地将节点配对成多个Group,并在其内执行All Gather任务,实时报告结果。一旦Group中节点检测失败,即标记为潜在故障机。紧接着,启动第二轮精准测试,重新组合故障与正常机器,从而精准识别故障源,确保系统稳定运行。
7.3 Flash Checkpoint
DLRover发布的Flash Checkpoint实现大模型训练秒级容错,详述了其卓越能力:支持快速恢复训练中断,确保数据完整性与训练效率,为大规模模型训练提供强大保障。
- DLRover独具断点续存功能,故障时迅速将Checkpoint数据持久化存储,确保数据不丢失,大幅减少迭代时间损耗,提升效率。
- 内存热加载优化:非宕机问题下,重启训练进程即可从主机内存加载Checkpoint,无需访问存储系统,显著提升效率。
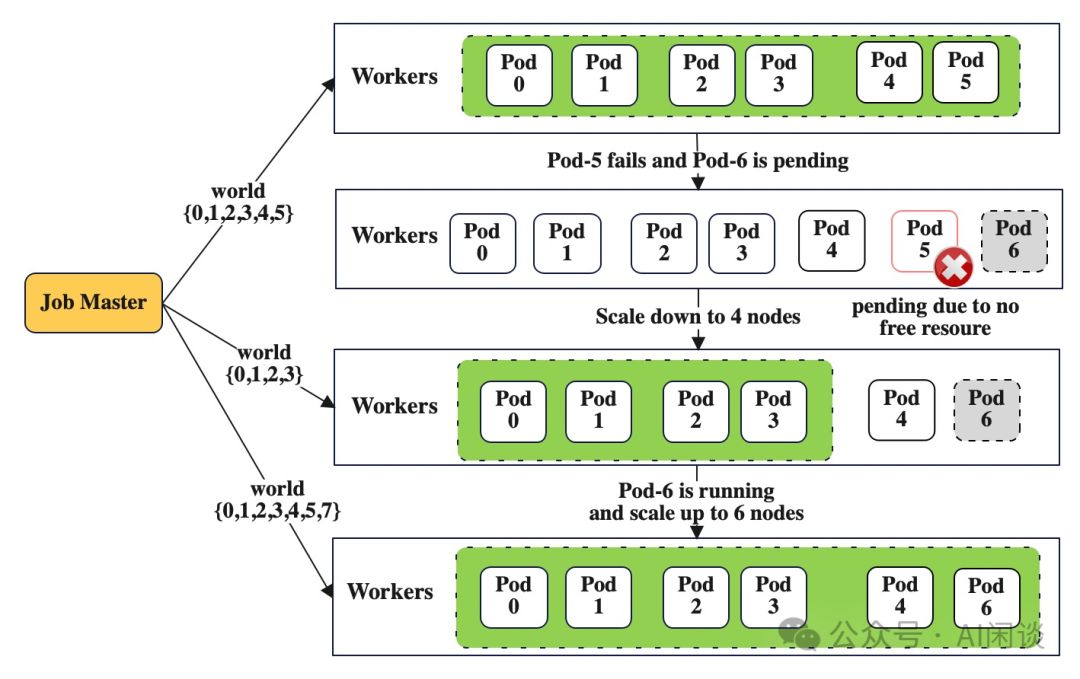
7.4 弹性
DLRover革新TorchElastic的ElasticAgent,大幅增强弹性。训练任务遇挫或资源紧缺时,能智能驱逐异常机器,精简资源继续训练;一旦资源充足,即迅速扩容,无缝衔接训练,确保高效稳定。
7.5 Profiling 工具
作者最新推出的Profiling工具------xpu_timer,为大模型训练提供全面故障排查方案。该工具截获Cublas/Cudart库,利用cudaEvent精准计时训练中的计算与通信。更配备Timeline分析、Hang检测及栈分析功能,确保训练无死角。尽管尚未正式开源,但已展现出卓越性能与潜力。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-