💬内容概要
1 集成学习概述及主要研究领域
2 简单集成技术
2.1 投票法
2.2 平均法
2.3 加权平均
3 高级集成技术
3.1 Bagging
3.2 Boosting
3.3 Bagging vs Boosting
4 基于Bagging和Boosting的机器学习算法
4.1 sklearn中的Bagging算法
4.2 sklearn中的Boosting算法

集成学习概述及主要研究领域
1.1 集成学习概述💥
"众人拾柴火焰高"、"三个臭皮匠顶个诸葛亮"等词语都在表明着群体智慧 的力量,所谓的"群体智慧"指的就是一群对某个主题具有平均知识的人集中在一起可以对某一些问题提供出更加可靠的答案。原因在于,汇总结果能够抵消噪音,得出的结论通常可以优于知识渊博的专家。同样的规则也适用于机器学习领域。
在机器学习中,群体智慧是通过集成学习实现的,所谓集成学习(ensemble learning),是指通过构建多个弱学习器,然后结合为一个强学习器来完成分类任务并获得比单个弱分类器更好的效果。严格来说,集成学习并不算是一种分类器,而是一种学习器结合的方法。
1.2 集成学习的三大关键领域💥
在过去十年中,人工智能相关产业蓬勃发展,计算机视觉、自然语言处理、语音识别等领域不断推陈出新、硕果累累,但热闹是深度学习的,机器学习好似什么也没有。2012年之后,传统机器学习占据的搜索、推荐、翻译、各类预测领域都被深度学习替代或入侵,在招聘岗位中,69%的岗位明确要求深度学习技能,传统机器学习算法在这一场轰轰烈烈的人工智能热潮当中似乎有些被冷落了。
在人工智能大热的背后,集成学习就如同裂缝中的一道阳光,凭借其先进的思想、优异的性能杀出了一条血路,成为当代机器学习领域中最受学术界和产业界青睐的领域。
从今天的眼光来看,集成学习是:
- 当代工业应用中,唯一能与深度学习算法分庭抗礼的算法
- 数据竞赛高分榜统治者,KDDcup、Kaggle、天池、DC冠军队御用算法
- 在搜索、推荐、广告等众多领域,事实上的工业标准和基准模型
- 任何机器学习/深度学习工作者都必须掌握其原理、熟读其思想的领域
在集成学习的发展历程中,集成的思想以及方法启发了众多深度学习和机器学习方面的工作,在学术界和工业界都取得了巨大的成功。今天,集成学习可以被分为三个主要研究领域:
-
弱分类器集成
弱分类器集成主要专注于对传统机器学习算法的集成,这个领域覆盖了大部分我们熟悉的集成算法和集成手段,如装袋法bagging,提升法boosting。这个领域试图设计强大的集成算法、来将多个弱学习器提升成为强学习器。
-
模型融合
模型融合在最初的时候被称为"分类器结合",这个领域主要关注强评估器,试图设计出强大的规则来融合强分类器的结果、以获取更好的融合结果。这个领域的手段主要包括了投票法Voting、堆叠法Stacking、混合法Blending等,且被融合的模型需要是强分类器。模型融合技巧是机器学习/深度学习竞赛中最为可靠的提分手段之一,常言道:当你做了一切尝试都无效,试试模型融合。
-
混合专家模型 (mixture of experts)
混合专家模型常常出现在深度学习(神经网络)的领域。在其他集成领域当中,不同的学习器是针对同一任务、甚至在同一数据上进行训练,但在混合专家模型中,我们将一个复杂的任务拆解成几个相对简单且更小的子任务,然后针对不同的子任务训练个体学习器(专家),然后再结合这些个体学习器的结果得出最终的输出。
2 简单集成技术
在正式学习集成算法之前,我们先来了解一下简单的集成技术。
2.1 投票法💢
投票法主要用于分类问题中,主要流程是:使用N个弱分类器对每个样本进行预测,每个弱分类器得到的预测结果都被视为"投票",对于同一个样本来说,会得到N个投票,N个投票中最多的那个类别即为这个样本最终的预测结果。也就是说,投票法的主要规则就是少数服从多数。
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn.linear_model import LogisticRegression as LR
data = load_breast_cancer()
X = data.data
y = data.target
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=0)
model1 = KNN()
model2 = DTC()
model3 = LR()
model1.fit(Xtrain,Ytrain)
model2.fit(Xtrain,Ytrain)
model3.fit(Xtrain,Ytrain)
pred1 = model1.predict(Xtest)
pred2 = model2.predict(Xtest)
pred3 = model3.predict(Xtest)
final_pred = []
for i in range(Xtest.shape[0]):
final_pred.append(stats.mode([pred1[i],pred2[i],pred3[i]])[0][0])
from sklearn.metrics import accuracy_score
accuracy_score(Ytest,final_pred)
# 0.9707602339181286
print(model1.score(Xtest,Ytest))
print(model2.score(Xtest,Ytest))
print(model3.score(Xtest,Ytest))
# 0.9473684210526315
# 0.9298245614035088
# 0.95321637426900592.2 平均法💢
平均法主要用于回归类问题,主要流程是:使用N个弱分类器对每个样本进行预测,每个样本的最终预测值就是N个弱分类器输出的预测结果的平均值。
python
from sklearn.datasets import load_diabetes
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import LinearRegression
data = load_diabetes()
X = data.data
y = data.target
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=0)
reg1 = KNeighborsRegressor()
reg2 = DecisionTreeRegressor(max_depth=2)
reg3 = LinearRegression()
reg1.fit(Xtrain,Ytrain)
reg2.fit(Xtrain,Ytrain)
reg3.fit(Xtrain,Ytrain)
# 对测试集中前20个样本进行预测
Xt = Xtest[:20]
p1 = reg1.predict(Xt)
p2 = reg2.predict(Xt)
p3 = reg3.predict(Xt)
# 使用平均法得到最终预测结果
p_final = (p1+p2+p3)/3
# 绘制前20个样本的可视化结果
plt.figure(figsize=(8,5))
plt.plot(p1, "gd", label="KNeighborsRegressor")
plt.plot(p2, "b^", label="DecisionTreeRegressor")
plt.plot(p3, "ys", label="LinearRegression")
plt.plot(p_final, "r*", ms=10, label="average")
plt.plot(Ytest[:20],"ko",label="Label")
plt.xticks(range(20))
plt.ylabel("predicted")
plt.xlabel("training samples")
plt.legend(loc=1, bbox_to_anchor=(1.4,1.0))
plt.grid(axis='x')
plt.title("Regressor predictions and their average")
plt.show()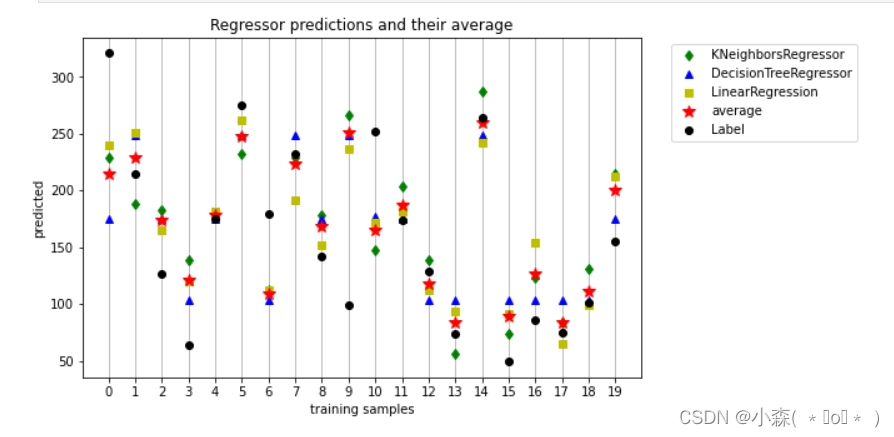
python
print(reg1.score(Xt,Ytest[:20]))
print(reg2.score(Xt,Ytest[:20]))
print(reg3.score(Xt,Ytest[:20]))
# 0.38569680255687555
# 0.4245152879688403
# 0.5350833277174876
from sklearn.metrics import r2_score
r2_score(Ytest[:20],p_final)
# 0.49560957430882092.3 加权平均法💢
这个是平均法的改进版,指的是给不同模型加上不同的权重,这个可以定义每个模型对于预测结果的重要性。一般来说,弱分类器效果好的我们会给更高的权重。需要注意的是,所有弱分类器的权重之和等于1。
python
print(reg1.score(Xt,Ytest[:20]))
print(reg2.score(Xt,Ytest[:20]))
print(reg3.score(Xt,Ytest[:20]))
# 结果
0.38569680255687555
0.4245152879688403
0.5350833277174876
# 使用加权平均法得到最终预测结果
p_Wfinal = p1*0.2+p2*0.2+p3*0.6
r2_score(Ytest[:20],p_Wfinal)
# 0.52085860195732343 高级集成技术
3.1 Bagging💯
Bagging(又称为装袋法),是所有集成方法中最为简单也最为常用的操作之一。Bagging这个名字其实是Bootstrap Aggregating的缩写,顾名思义,Bagging的两个关键点就是引导和聚合。Bagging方法主要是通过结合几个模型的结果来降低方差、避免过拟合,并提高准确率和稳定性。
Bagging方法的执行步骤主要分为两部分:
- 通过随机采样 (Bootstrap)的方法产生不同的训练数据集 ,然后分别基于这些训练集建立多个弱学习器。
- 通过投票法或者平均法对多个弱学习器的结果进行聚合(Aggregating),得到一个相对更优的预测模型(强学习器)。

这个过程中,需要注意的是:
- 每个采样集都是从原始数据集中有放回的随机抽样 出来的,这个方法也叫做自主采样法(Bootstap sampling)。也就是说对于m个样本的原始数据集,每次随机选取一个样本放入采样集,然后把这个样本重新放回原数据集中,然后再进行下一个样本的随机抽样,直到一个采样集中的数量达到m,这样一个采样集就构建好了,然后我们可以重复这个过程,生成n个这样的采样集。也就是说,每个采样集中的样本可能是重复的,也可能原数据集中的某些样本根本就没抽到,并且每个采样集中的样本分布可能都不一样。
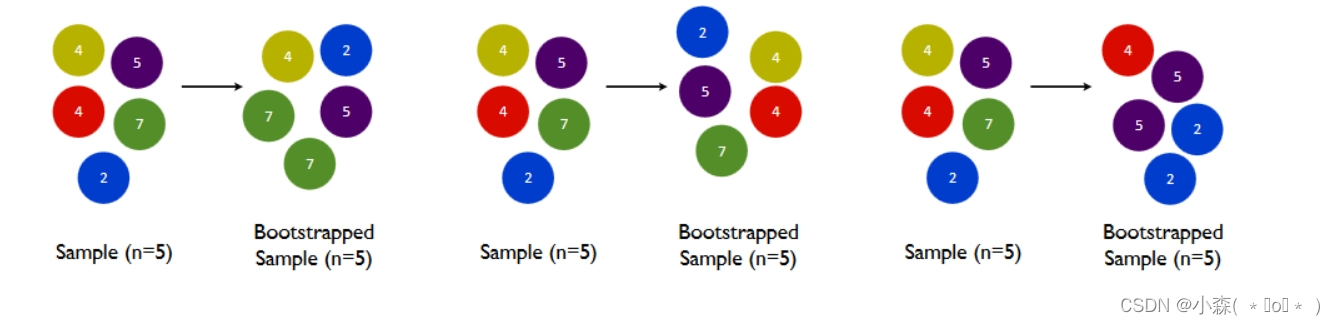
- 在Bagging集成当中,我们并行建立多个弱评估器(通常是决策树,也可以是其他非线性算法),并综合多个弱评估器的结果进行输出。当集成算法目标是回归任务时,集成算法的输出结果是弱评估器输出的结果的平均值,当集成算法的目标是分类任务时,集成算法的输出结果是弱评估器输出的结果使用投票法(少数服从多数)。
假设现在一个bagging集成算法当中有7个弱评估器,对任意一个样本而言,输出的结果如下:
python
import numpy as np
#分类的情况:输出7个弱评估器上的分类结果(0,1,2)
r_clf = np.array([0,2,1,1,2,1,0])
np.bincount(r_clf)
np.argmax(np.bincount(r_clf))
result_clf = np.argmax(np.bincount(r_clf))
result_clf #集成算法在现在的样本上应该输出的类别
#如果评估器的数量是偶数,而少数和多数刚好一致怎么办?
r_clf = np.array([1,1,1,0,0,0,2,2])
result_clf = np.argmax(np.bincount(r_clf))
result_clf
#回归的情况:输出7个弱评估器上的回归结果
r_reg = np.array([-2.082, -0.601, -1.686, -1.001, -2.037, 0.1284, 0.8500])
result_reg = r_reg.mean()
result_reg
# -0.91837142857142853.2 Boosting adaboost、gbdt,xgboost💯
boosting又称为提升法,它是一个迭代的过程,用来自适应地改变训练样本的分布,使得弱分类器聚焦到那些很难分类的样本上。它的做法是给每一个训练样本赋予一个权重,在每一轮训练结束时自动地调整权重。
boosting方法的流程,如下图所示:

首先给每个样本一个初始权重D1(通常初始权重为1),使用带着初始权重D1的样本集对模型进行训练得到第一个弱学习器,然后第一个弱学习器对所有的样本进行预测,有些样本会预测正确,有些样本则会预测错误,此时得到一个误差率e1,预测正确的样本就减少这些样本的权重,预测错误的样本就增加这些样本的权重,也就是让模型更加关注预测错误的那些样本,那么之后所有的样本权重就会发生改变,此时样本权重变为D2,继续使用带着权重D2的样本集对模型进行训练得到弱学习器2,然后弱学习器2对所有的样本进行预测......直到训练出N个弱学习器。然后对这N个弱学习器进行加权平均得到一个强学习器。
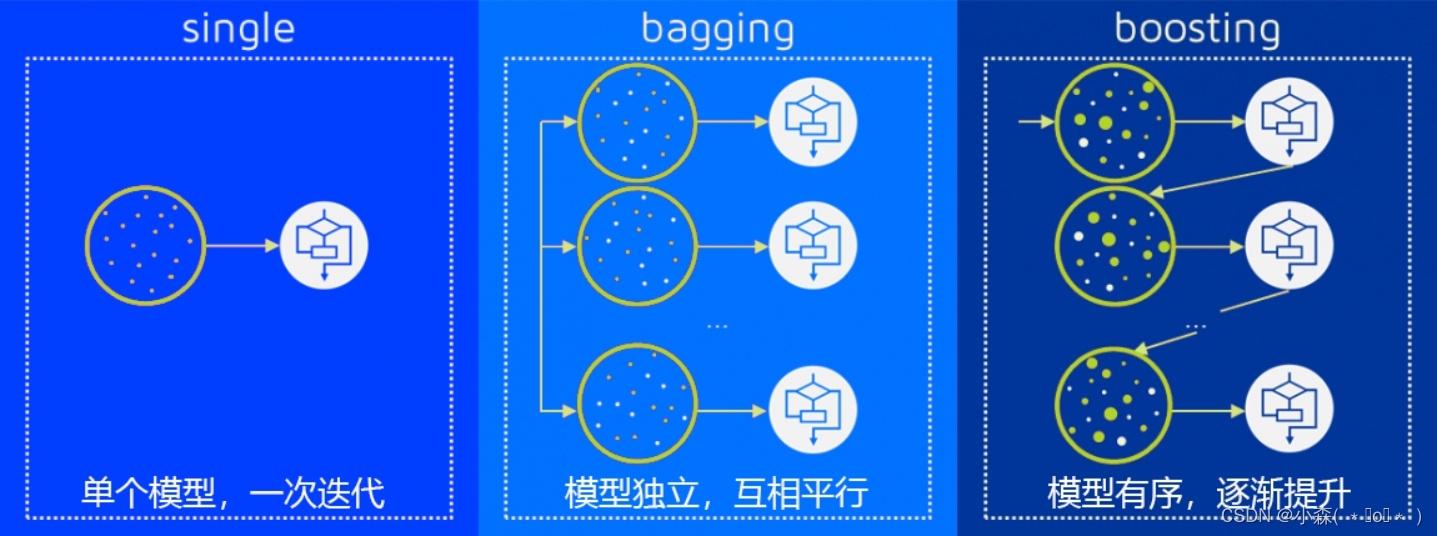
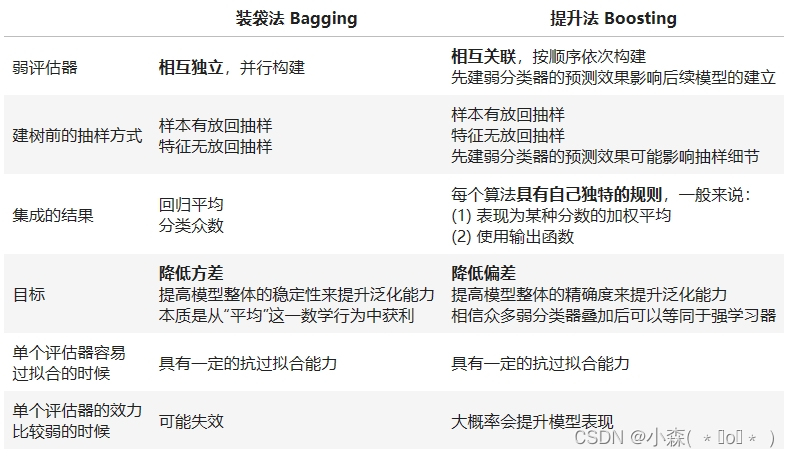
3.3 Bagging vs Boosting 💯
在Bagging算法中,我们一次性建立多个平行独立的弱评估器 ,并让所有评估器并行运算。在Boosting集成算法当中,我们逐一建立多个弱评估器(基本是决策树),并且下一个弱评估器的建立方式依赖于上一个弱评估器的评估结果,最终综合多个弱评估器的结果进行输出,因此Boosting算法中的弱评估器之间不仅不是相互独立的、反而是强相关的,同时Boosting算法也不依赖于弱分类器之间的独立性来提升结果,这是Boosting与Bagging的一大差别。如果说Bagging不同算法之间的核心区别在于靠以不同方式实现"独立性"(随机性),那Boosting的不同算法之间的核心区别就在于上一个弱评估器的评估结果具体如何影响下一个弱评估器的建立过程。
与Bagging算法中统一的回归求平均、分类少数服从多数的输出不同,Boosting算法在结果输出方面表现得十分多样。早期的Boosting算法的输出一般是最后一个弱评估器的输出,当代Boosting算法的输出都会考虑整个集成模型中全部的弱评估器。一般来说,每个Boosting算法会其以独特的规则自定义集成输出的具体形式 ,但对大部分算法而言,集成算法的输出结果往往是关于弱评估器的某种结果的加权平均,其中权重的求解是boosting领域中非常关键的步骤。
4 基于Bagging和Boosting的机器学习算法
4.1 sklearn中的bagging算法💫
在sklearn当中,我们可以接触到两个Bagging集成算法,一个是随机森林(RandomForest),另一个是极端随机树(ExtraTrees),他们都是以决策树为弱评估器的有监督算法,可以被用于分类、回归、排序等各种任务。同时,我们还可以使用bagging的思路对其他算法进行集成,比如使用装袋法分类的类BaggingClassifier对支持向量机或逻辑回归进行集成。
4.2 sklearn中的Boosting算法💫
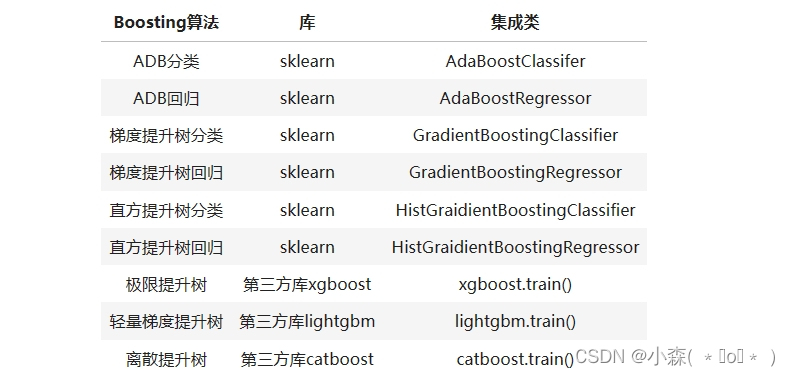
在sklearn当中,我们可以接触到数个Boosting集成算法,包括Boosting入门算法AdaBoost ,性能最稳定、奠定了整个Boosting效果基础的梯度提升树GBDT (Gradient Boosting Decision Tree),以及近几年才逐渐被验证有效的直方提升树(Hist Gradient Boosting Tree)。
在过去5年之间,除了sklearn,研究者们还创造了大量基于GBDT进行改造的提升类算法,这些算法大多需要从第三方库进行调用,例如极限提升树XGBoost (Extreme Gradient Boosting Tree),轻量梯度提升树LightGBM (Light Gradiant Boosting Machine),以及离散提升树CatBoost(Categorial Boosting Tree)。