09.正则解析爬取数据
1.目标网站
直达目标网站 https://movie.douban.com/chart
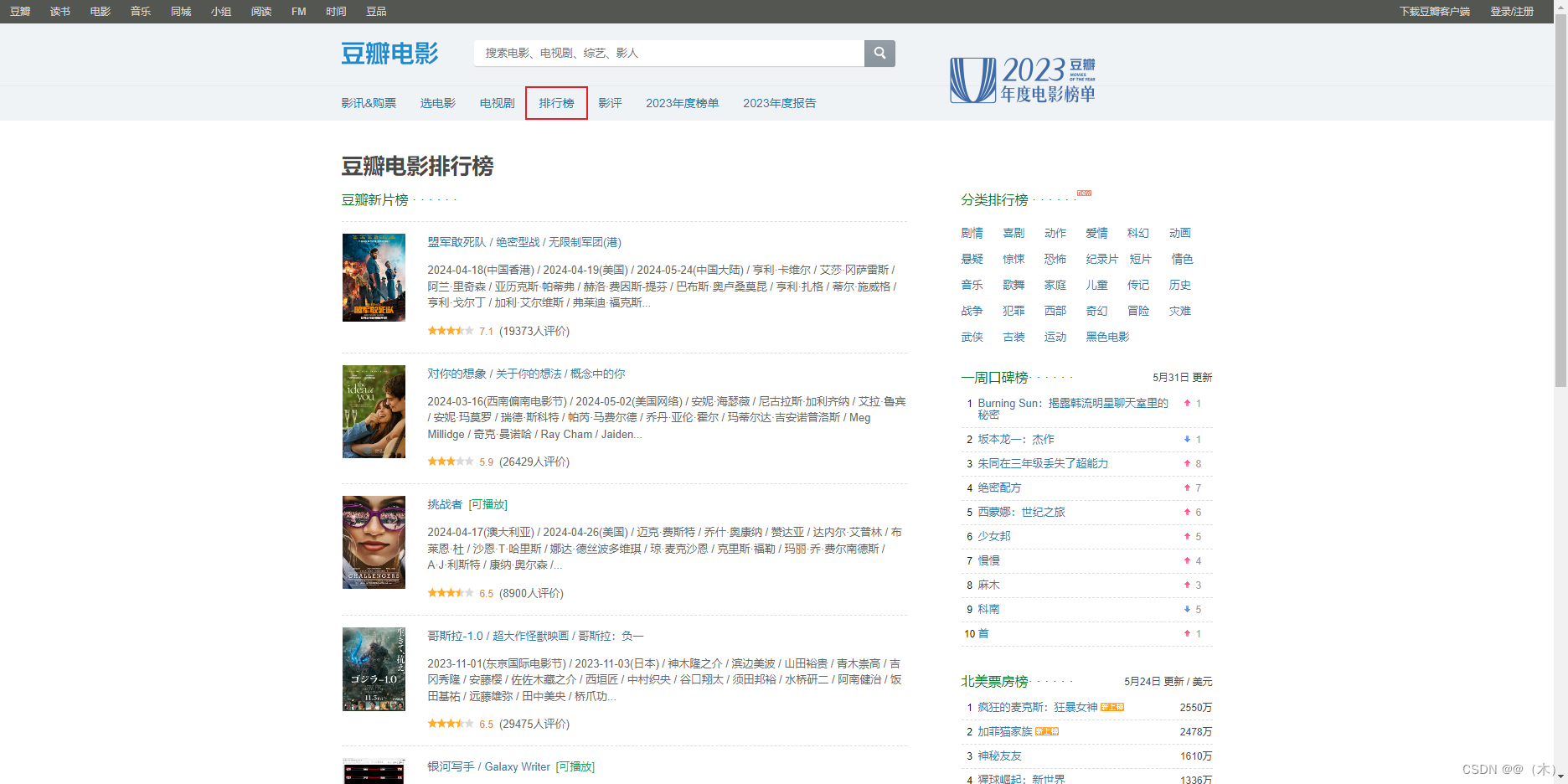
2.具体实现
我们来拿取一下上面网页的代码如下:
py
from urllib import request
url = 'https://movie.douban.com/chart'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.289 Safari/537.36'
}
req = request.Request(url=url, data=None, headers=headers)
response = request.urlopen(req)
print(response.read().decode('utf-8'))结果如下:
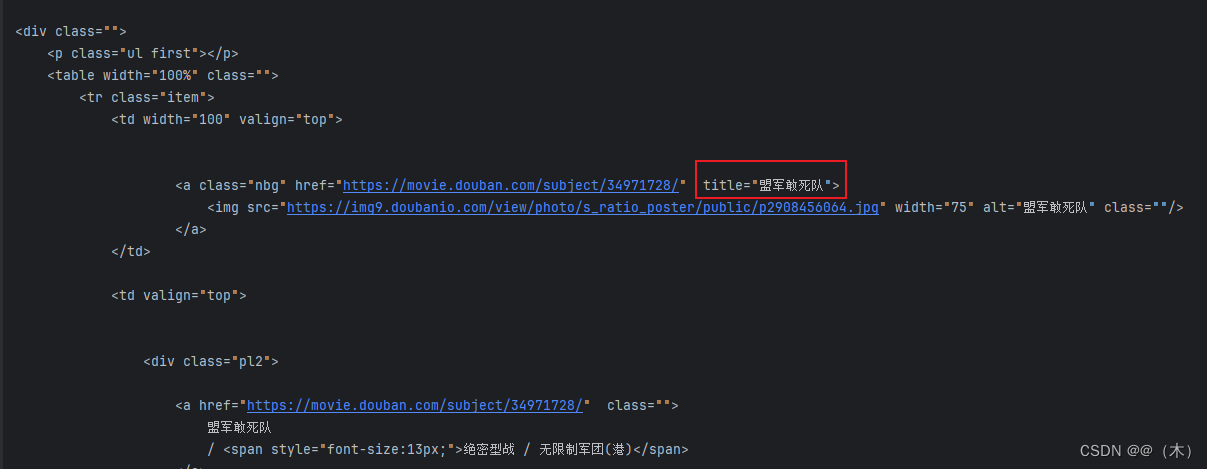
接下来就是对拿到的内容进行解析想要的数据:
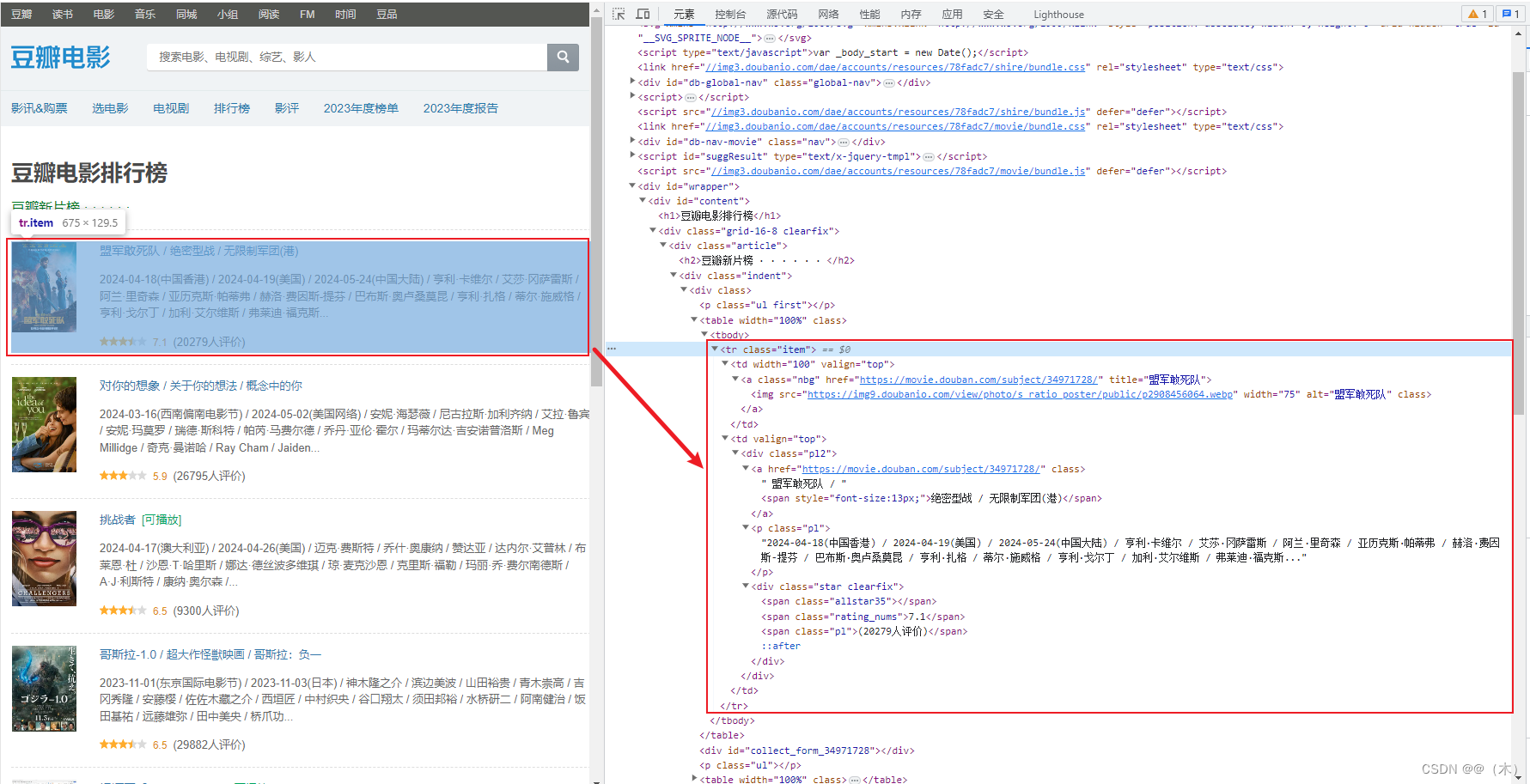
经过观察数据规律,可以发现如上图的html文档规律,按照以上规律去解析数据
3.正则表达式分析
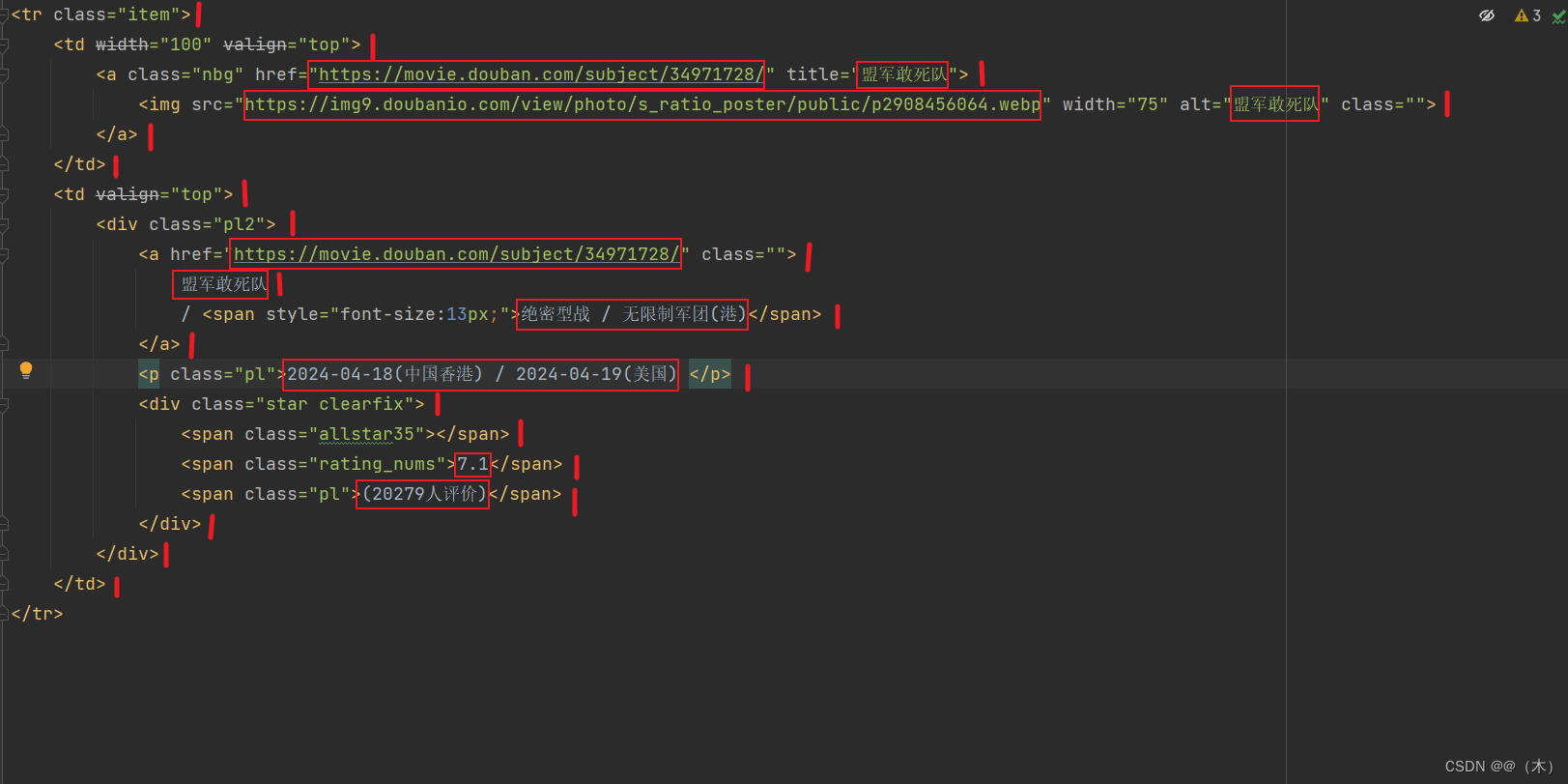
上图中
|标记的地方用\s*替换口标记的地方用(.*?)替换\s*来让数据在一行,而不影响正则表达式的使用。\s*的作用是匹配零个或多个空格字符(包括空格、制表符、换行符等)。它常用于正则表达式中,用于匹配任意数量的空格字符。.*?表示非贪心算法,表示要精确的配对。作用是匹配任意数量的任意字符,但是会尽可能少地匹配,直到下一个匹配字符出现
替换后得到了下面的内容:
bash
'<tr class="item">\s*'
'<td width="100" valign="top">\s*'
'<a class="nbg" href="(.*?)" title="(.*?)">\s*'
'<img src="(.*?)" width="75" alt="(.*?)" class=""/>\s*'
'</a>\s*'
'</td>\s*'
'<td valign="top">\s*'
'<div class="pl2">\s*'
'<a href="(.*?)" class="">\s*'
'(.*?)\s*'
'(.*?) <span style="(.*?)">(.*?)</span>\s*'
'</a>\s*(.*?)\s*'
'<p class="pl">(.*?)</p>\s*'
'<div class="star clearfix">\s*'
'<span class="(.*?)"></span>\s*'
'<span class="rating_nums">(.*?)</span>\s*'
'<span class="pl">(.*?)</span>\s*'
'</div>\s*'
'</div>\s*'
'</td>\s*'
'</tr>'4.完整代码并存入表格
bash
import re
import csv
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
url = f'https://movie.douban.com/chart'
f = open('C:\\Users\\DY\\Desktop\\data.csv', 'w+', encoding='gbk', newline='')
csv_f = csv.writer(f)
csv_f.writerow(['1', '2', '3', '4', '5','6', '7', '8', '9', '10','11','12','13'])
html = requests.get(url, headers=headers)
data = re.findall(
'<tr class="item">\s*'
'<td width="100" valign="top">\s*'
'<a class="nbg" href="(.*?)" title="(.*?)">\s*'
'<img src="(.*?)" width="75" alt="(.*?)" class=""/>\s*'
'</a>\s*'
'</td>\s*'
'<td valign="top">\s*'
'<div class="pl2">\s*'
'<a href="(.*?)" class="">\s*'
'(.*?)\s*'
'(.*?) <span style="(.*?)">(.*?)</span>\s*'
'</a>\s*(.*?)\s*'
'<p class="pl">(.*?)</p>\s*'
'<div class="star clearfix">\s*'
'<span class="(.*?)"></span>\s*'
'<span class="rating_nums">(.*?)</span>\s*'
'<span class="pl">(.*?)</span>\s*'
'</div>\s*'
'</div>\s*'
'</td>\s*'
'</tr>',
html.text)
for i in data:
csv_f.writerow(i)
print(i)
f.close()
py
f = open('C:\\Users\\DY\\Desktop\\data.csv', 'w+', encoding='gbk', newline='')
csv_f = csv.writer(f)
csv_f.writerow(['1', '2', '3', '4', '5','6', '7', '8', '9', '10','11','12','13'])作用是打开一个名为 data.csv 的文件(如果不存在则创建),并使用 gbk 编码方式进行读写操作,同时设置换行符为
'\n'。然后创建一个 csv.writer 对象 csv_f,用于将数据写入到文件中。接下来,使用 csv_f.writerow()
方法将包含列名的一行写入到文件中,该行包含了13个列的名称。这样,文件 data.csv
就具有了一个表格的结构,可以用于存储和处理数据。