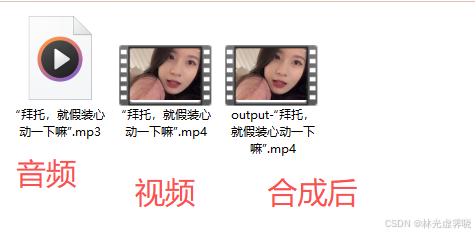
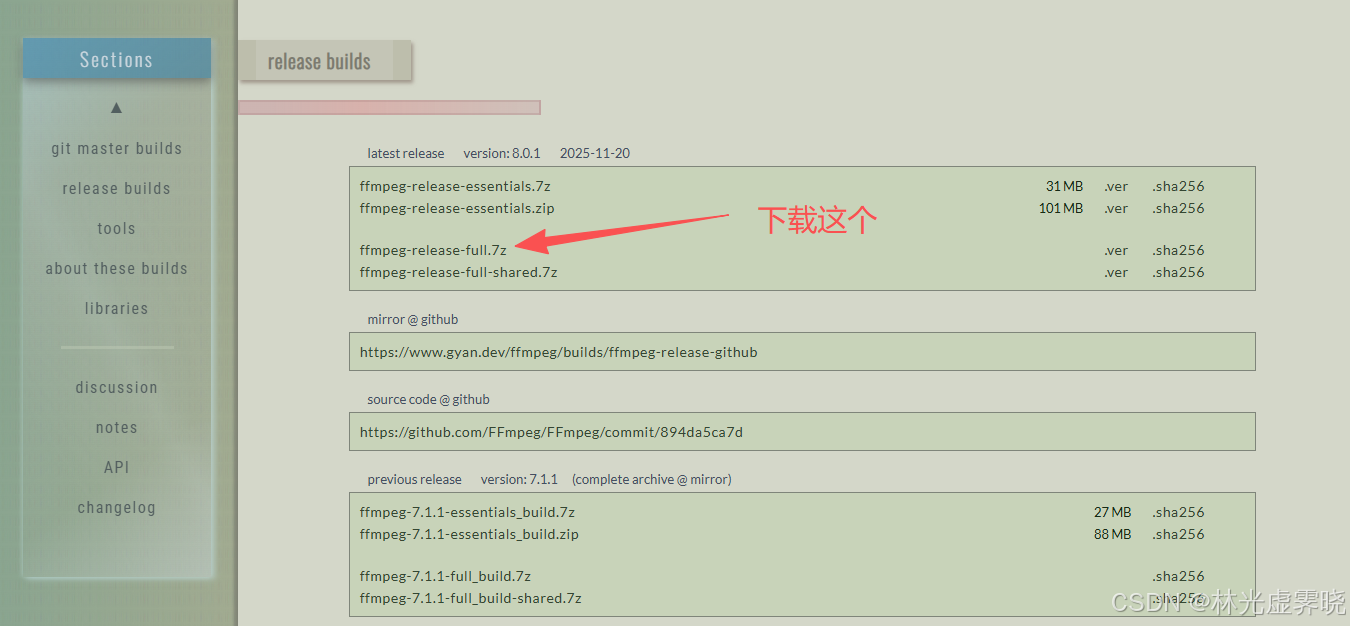
ffmpeg下载
代码实现
python
import pprint
import subprocess
import requests
from fake_useragent import UserAgent
import random
import re
import json
import os
from lxml import etree
ua = UserAgent()
headers = {
"User-Agent": ua.random,
"Referer": "https://www.bilibili.com/",
"Cookie": "buvid3=F8C19783-ACEA-59F9-B2AA-26DE8893EA9952876infoc; b_nut=1766841352; b_lsid=E37ACBD9_19B5FF38753; bsource=search_baidu; _uuid=199102BB2-10938-D12A-5B96-F10F59D96F2E554076infoc; home_feed_column=5; browser_resolution=1920-945; buvid_fp=61e3c5797af3dabc5837e04f907d9dc2; bmg_af_switch=1; bmg_src_def_domain=i2.hdslb.com; bili_ticket=eyJhbGciOiJIUzI1NiIsImtpZCI6InMwMyIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3NjcxMDA1NTMsImlhdCI6MTc2Njg0MTI5MywicGx0IjotMX0.kDsmSBtlR_REtna9rsGhPPhHrV8Pxy72B2h_BLrZwbM; bili_ticket_expires=1767100493; buvid4=8E67B41C-E535-B165-EB97-0EDD40DE2C6154154-025122721-PpSVmW9OodzKBxrGNjP3RWsvbFnkFXlE+0v7ibTZbIJ6B8znXQ04IOaU2ko2k395; CURRENT_FNVAL=4048; CURRENT_QUALITY=0; rpdid=0zbfAHJoqP|VlKIIjWh|1sD|3w1Vzu9Y; sid=5uy36kmc",
"Accept": "application/json, text/plain, */*",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive"
}
def get_play_url(url):
# 1 爬取视频页的网页源码
resp = requests.get(url=url, headers=headers)
# 2 提取视频和音频的播放地址
info = re.findall('window.__playinfo__=(.*?)</script>', resp.text)[0]
# 获取视频的播放地址
video_url = json.loads(info)['data']['dash']['video'][0]['baseUrl']
# video_url = 'https://upos-sz-mirror08c.bilivideo.com/upgcxcode/08/75/719057508/719057508-1-30032.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&nbs=1&uipk=5&platform=pc&mid=0&os=08cbv&oi=0x24098a2808e7b7b041754bc94fd27906&deadline=1766850571&trid=b3e1ff33737b4b2cb496b415f6ca381u&gen=playurlv3&og=hw&upsig=372638e0bb9b5aa0075b58bc52b87598&uparams=e,nbs,uipk,platform,mid,os,oi,deadline,trid,gen,og&bvc=vod&nettype=0&bw=428953&build=0&dl=0&f=u_0_0&qn_dyeid=cf4203b6ed795ca600e7072f694fe3eb&agrr=0&buvid=&orderid=0,3'
# 获取音频的播放地址
audio_url = json.loads(info)['data']['dash']['audio'][0]['baseUrl']
# audio_url = 'https://upos-sz-estghw.bilivideo.com/upgcxcode/08/75/719057508/719057508-1-30216.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&platform=pc&trid=222c1eb52fb745c5bd6069a5930008du&oi=0x24098a2808e7b7b041754bc94fd27906&deadline=1766850802&uipk=5&gen=playurlv3&os=estghw&mid=0&nbs=1&og=hw&upsig=7d093ee5b56ec63263af9e3c814e538c&uparams=e,platform,trid,oi,deadline,uipk,gen,os,mid,nbs,og&bvc=vod&nettype=0&bw=67689&f=u_0_0&qn_dyeid=16133e653e0485130061eb45694fe4d2&agrr=0&buvid=&build=0&dl=0&orderid=0,3'
# 获取标题
html = etree.HTML(resp.text)
filename = html.xpath("//h1/text()")[0]
return filename, video_url, audio_url
# 3 下载并保存视频和音频
def download_files(filename, video_url, audio_url, path):
print('开始下载视频,音频.......')
video_content = requests.get(url=video_url, headers=headers).content
audio_content = requests.get(url=audio_url, headers=headers).content
if not os.path.exists(f'{path}/video'):
print('创建video文件夹')
os.makedirs(f'{path}/video')
with open(f'video/{filename}.mp4', 'ab') as f:
f.write(video_content)
print('视频已下载完毕...')
with open(f'video/{filename}.mp3', 'ab') as f:
f.write(audio_content)
print('音频已下载完毕...')
# 4 使用ffmpeg合并视频和音频
# ffmpeg
def combine_files(filename, path):
ffmpeg = r"D:\software\ffmpeg-8.0.1-full_build\bin\ffmpeg.exe"
input_video = rf"{path}\video\{filename}.mp4"
input_audio = rf"{path}\video\{filename}.mp3"
output_video = rf"{path}\video\output-{filename}.mp4"
cmd = [
ffmpeg,
'-i', input_video,
'-i', input_audio,
'-c:v', 'copy',
'-c:a', 'aac',
output_video
]
result = subprocess.run(cmd, capture_output=True, text=True, encoding='utf-8', errors='ignore')
print("stdout:", result.stdout)
print("stderr:", result.stderr)
if result.returncode == 0:
print('已完成合并........')
else:
print('合并失败,请检查错误信息')
if __name__ == '__main__':
url = "https://www.bilibili.com/video/BV1AA4y1D7h2?vd_source=5fb207316e3b77a15884783d3c143acf"
path = r"E:\spider_code\video_bilibili"
filename, video_url, audio_url = get_play_url(url)
# download_files(filename, video_url, audio_url, path)
combine_files(filename, path)结果展示: