1.1 介绍
AlexNet是深度学习历史上一个非常重要的卷积神经网络(Convolutional Neural Network, CNN)模型,由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton在2012年设计并提出。它因在ImageNet大规模视觉识别挑战赛中的卓越表现而闻名,这场胜利标志着深度学习技术在图像识别任务上的重大突破,并引发了随后几年深度学习领域的迅速发展。
AlexNet我认为作为计算机视觉的基石,从事计算机视觉的人都应该读读这篇论文:《ImageNet Classification with Deep Convolutional Neural Networks》,下面我们就来看一下。
1.2 深度卷积神经网络
AlexNet是一个具有开创性的深度卷积神经网络(CNN),它在2012年由Alex Krizhevsky等人提出,并在ImageNet大规模视觉识别挑战赛中取得了革命性的成果。
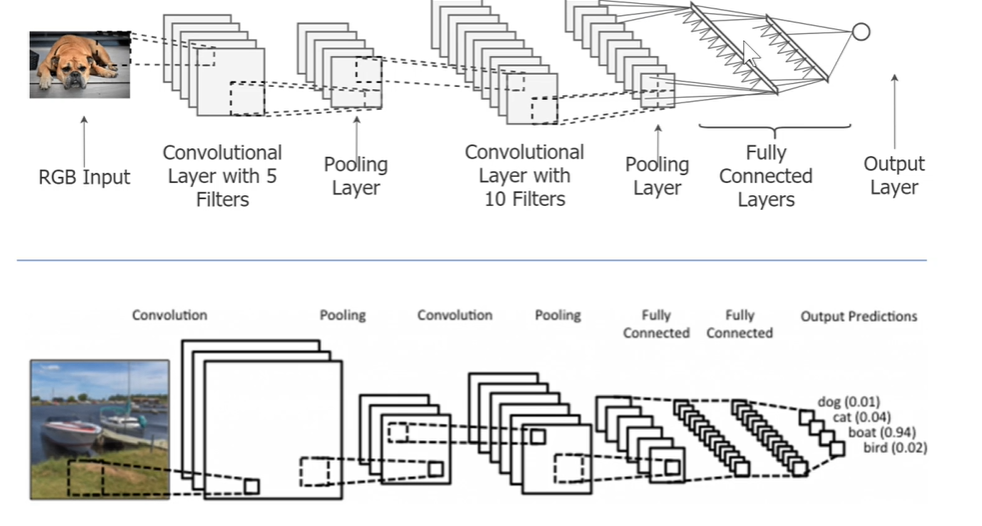
网络架构概览
AlexNet包含以下结构组件:
-
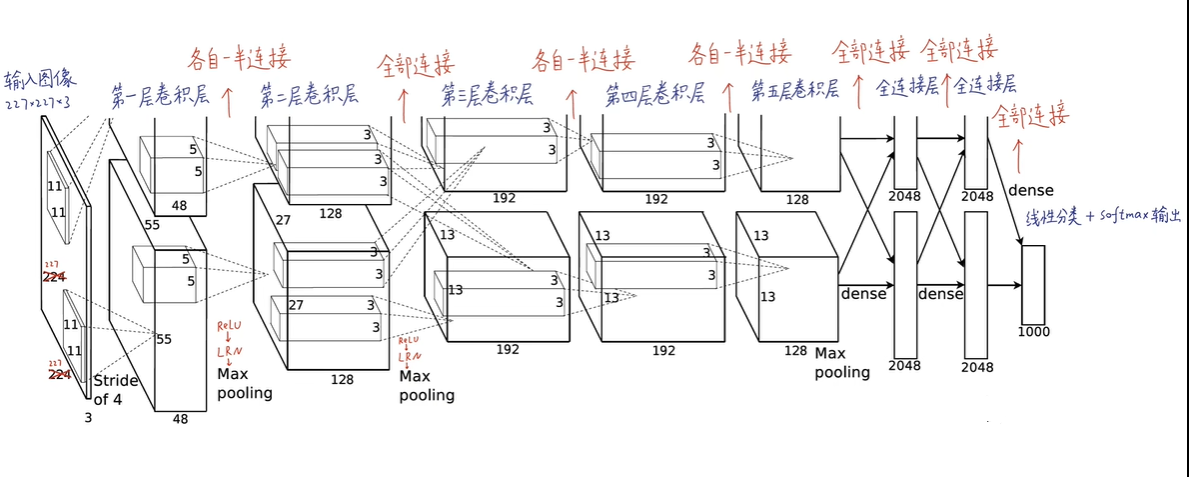
输入层:接收尺寸为224×224×3的RGB图像作为输入,尽管原始论文中提到的是224×224,但实践中因为边界处理(如填充padding)的考虑,输入尺寸为227×227。
-
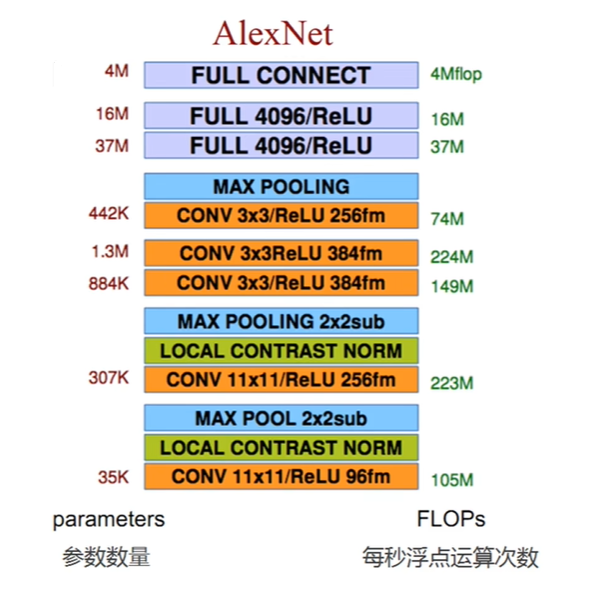
卷积层:共有5个卷积层(conv1至conv5),每个卷积层后面通常跟着ReLU激活函数,用于引入非线性。
- conv1: 使用11×11的卷积核,步长(stride)为4,有96个滤波器(或称为输出通道)。
- conv2: 使用5×5的卷积核,步长为1,有256个滤波器。
- conv3, conv4, conv5: 这些层使用更小的卷积核尺寸(如3×3),逐步增加深度,分别有384、384、256个滤波器。
-
最大池化层(Max Pooling):在某些卷积层之后紧跟着最大池化操作,用于降低空间维度,同时保持最重要的特征。池化窗口大小一般为3×3,步长为2。
-
全连接层(Fully Connected Layers):共有3个全连接层(fc6、fc7、fc8),用于将学到的特征转换为分类预测。
- fc6 和fc7后通常有ReLU激活函数和Dropout层,以减少过拟合。
- fc8输出层前使用Softmax函数,将输出转换为各分类的概率分布。
-
Dropout:在全连接层中使用Dropout技术随机"丢弃"一部分神经元,以提高模型的泛化能力。
-
ReLU激活函数:网络中使用ReLU代替传统的sigmoid或tanh函数,因为ReLU能够加速训练并缓解梯度消失问题。
1.3 AlexNet的结构特点
-
深度架构:AlexNet是一个相对深的网络,包含8层变换层------5层卷积层和3层全连接层,外加一个softmax输出层。在2012年,这种深度在神经网络中是相当罕见的,有助于模型学习更复杂的图像特征。
-
ReLU激活函数:它是最早在大型神经网络中成功使用ReLU(Rectified Linear Unit)激活函数的模型之一。ReLU因其计算效率高且能有效缓解梯度消失问题而被广泛采纳。
-
Dropout正则化:AlexNet在全连接层引入了Dropout技术,这是一种正则化方法,通过随机"关闭"网络中的一部分神经元来防止过拟合,增强了模型的泛化能力。
-
数据增强:通过在训练过程中对图像进行随机裁剪、翻转等变换,增加了训练数据的多样性,从而提高了模型的鲁棒性和泛化性能。
-
GPU并行计算:利用了GPU的并行计算能力来加速神经网络的训练过程,这是当时的一项重要技术创新,使得大规模神经网络的训练成为可能。
-
局部响应归一化(LRN):虽然在现代网络中不太常见,但AlexNet在其某些卷积层之后使用了LRN,旨在增强局部特征的区分度并促进泛化。
-
大训练数据集:AlexNet在ImageNet数据集上进行训练,该数据集包含数百万张带标签的图像,规模远超之前的研究,这对于学习丰富的视觉表示至关重要。

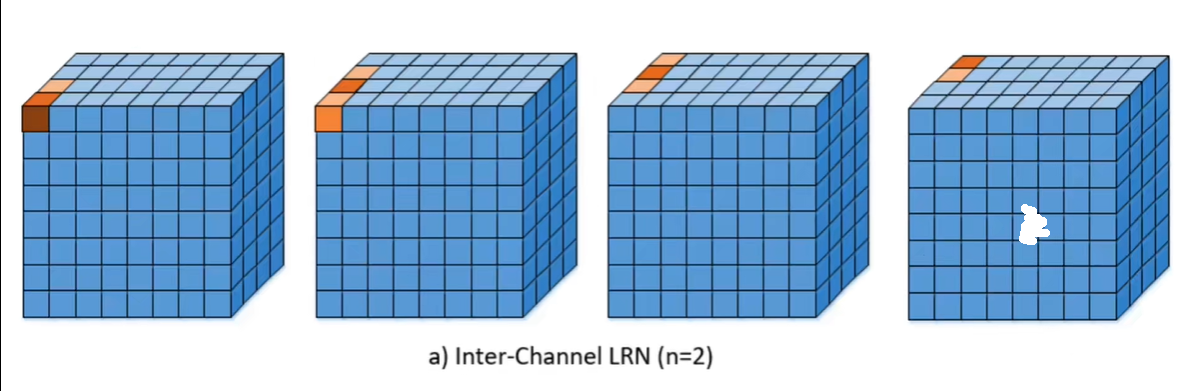
1.4 局部响应归一化LRN
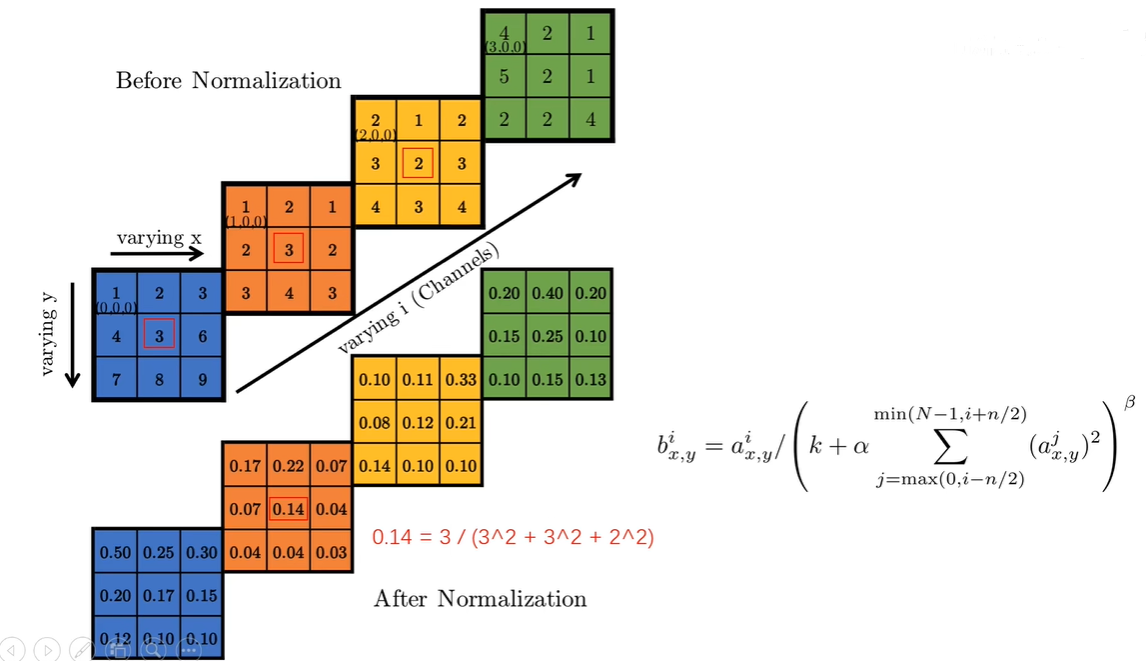
局部响应归一化(Local Response Normalization, LRN)是AlexNet中引入的一种技术,它模拟了生物神经系统中的一种现象,即侧抑制(Lateral Inhibition),目的是为了增强神经网络的泛化能力和提高学习效果。LRN通过调整相邻特征映射(feature map)单元之间的相互作用,使得对输入具有强烈响应的特征得到加强,而较弱的响应被抑制,从而增强了模型的鲁棒性和表达能力。
LRN通常在一个卷积层的输出之后应用,对每个通道独立进行。具体来说,对于每个通道的每个位置上的输出值,LRN按照以下公式进行归一化:
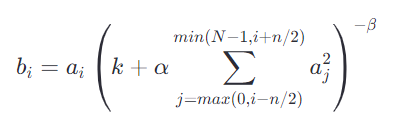

LRN的作用
- 增强泛化能力:通过模仿生物神经系统的侧抑制现象,LRN鼓励网络学习更具有区分性的特征,从而提高模型的泛化能力。
- 减轻过拟合:通过减少对某些特征的过度依赖,LRN有助于模型在训练数据上的平滑过渡,减少过拟合的风险。
- 突出重要特征:LRN通过降低周围弱响应神经元的激活值,使得强响应的特征更加显著,有助于模型学习关键特征。
LRN在现代网络中的地位
尽管LRN在AlexNet中发挥了重要作用,但在后续的深度学习模型中,像批量归一化(Batch Normalization, BN)和层归一化(Layer Normalization)等技术逐渐取代了LRN,因为它们在训练深层网络时提供了更好的稳定性和加速效果。不过,LRN作为深度学习发展史上的一项重要技术,其理念仍然对理解神经网络的设计原则有着重要的参考价值。

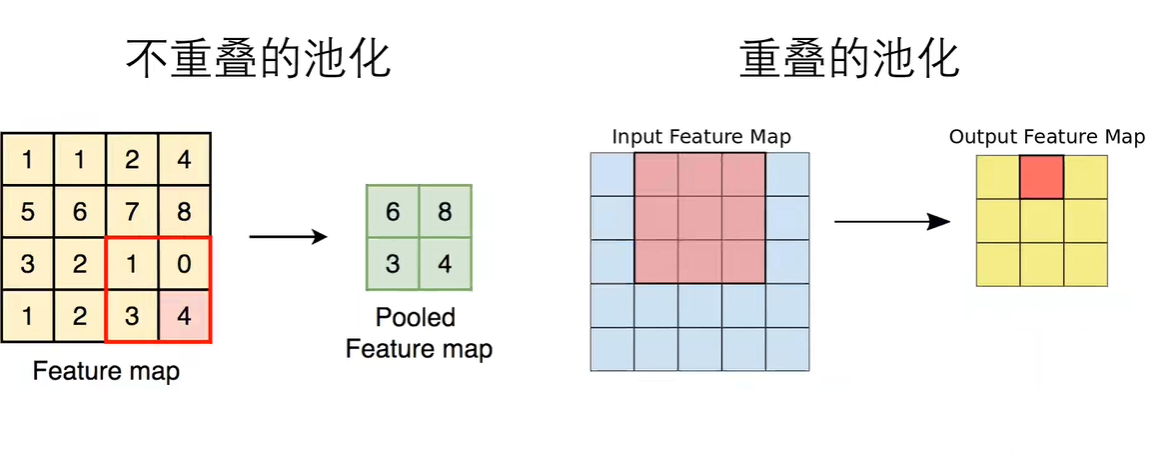
1.5 重叠池化
AlexNet中的重叠池化(Overlapping Pooling)是一种特殊的池化技术,与传统的非重叠池化相比,它通过减小池化操作的步长(stride)使得池化窗口在输入特征图上滑动时产生重叠区域,从而捕捉到更多的空间信息,增加了特征图的丰富性。
操作细节
-
池化窗口大小:在AlexNet中,池化层使用了3×33×3大小的窗口(kernel size),这比早期的一些网络中常用的2×22×2窗口更大。
-
步长(Stride):池化窗口在特征图上滑动时的步长设置为2,这意味着每次移动会跳过一个像素。由于池化窗口大小为3×33×3,因此在水平和垂直方向上都会有一像素的重叠。
-
最大池化操作:AlexNet全部使用最大池化而非平均池化,最大池化选择窗口内的最大值作为输出,这有助于保留最显著的特征,同时增加了模型的不变性,比如对图像的小幅形变不敏感。
意义与效果
-
特征丰富性:通过允许池化窗口重叠,特征图的相邻区域会有部分信息重叠,这增加了不同池化区域之间的上下文联系,使得模型能够捕获更精细的空间信息,提高了特征的多样性和表征能力。
-
减少过拟合:重叠池化通过增加模型的复杂度和对输入的多样表示,有助于减少过拟合的风险。模型能够学习到更多关于输入数据的泛化特征,而不是特定实例的细节。
-
提升精度:实验表明,重叠池化有助于提升网络的识别精度。在AlexNet的设计中,这种技术是其取得ImageNet竞赛优异成绩的关键因素之一。
-
计算成本与效率:虽然重叠池化增加了特征图的计算量,但由于池化操作本身的计算复杂度较低,相比于增加网络深度或宽度,这种增加的计算成本是可以接受的,尤其是在考虑其带来的性能提升时。
其实不管是LRN,还是重叠池化,后续的模型都不再采用了,说白了,AlexNet提出的很多方案不过是为后续模型的产生进行试水和探索。
1.6 数据增强
AlexNet在训练过程中采用了多种数据增强(Data Augmentation)技术来扩展训练数据集的规模和多样性,从而提高模型的泛化能力并减少过拟合。以下是AlexNet中应用的主要数据增强策略:
-
随机裁剪:原始图像被随机裁剪成224×224224×224的大小,这个过程从一个比224×224224×224稍大的图像(例如,256×256256×256)开始,每次裁剪的位置是随机的,这不仅增加了样本的数量,也使得模型学习到不同位置的特征,从而提升了对物体位置的鲁棒性。
-
水平翻转:图像以50%的概率进行水平翻转,这一操作帮助模型理解物体的左右对称性,使得模型在遇到镜像图像时也能正确识别。
-
颜色变化:通过调整图像的亮度、对比度、饱和度和色调等(利用PCA主成分分析),模拟不同光照条件下的图像,降低了模型对特定颜色配置的依赖,增强了对颜色变化的鲁棒性。这可以通过随机改变图像的RGB通道强度来实现。
-
其他可能的增强:虽然不是AlexNet直接采用的,但常见的数据增强技术还包括图像的缩放变换、旋转、剪切、加噪等,这些方法在其他网络或后续研究中被广泛应用,以进一步丰富数据集。
通过这些数据增强技术,AlexNet能够从相对有限的训练数据中创造出大量变化的样本,有效地扩大了训练集的覆盖范围,使模型在面对新数据时具有更好的泛化能力。这些技术对于深度学习尤其是视觉任务来说,已经成为标准的训练流程组成部分,极大地促进了模型性能的提升。

1.7 Dropout
AlexNet 在其设计中创新性地引入了 Dropout 作为一种正则化技术,以减少过拟合的风险并提高模型的泛化能力。下面详细介绍 AlexNet 中 Dropout 的工作原理和应用:
Dropout 的基本概念
Dropout 是一种随机丢弃神经元的技术,在训练神经网络的过程中,以一定的概率临时"关闭"网络中的某些神经元,具体来说,就是将这些神经元的输出置为0。这个概率通常被称为 Dropout 概率(p)。例如,如果设定 Dropout 概率为 0.5,那么在每一次训练迭代中,大约一半的神经元会被随机选中并暂时停止工作。
在 AlexNet 中的应用
在 AlexNet 中,Dropout 主要应用于全连接层(fully connected layers,即 fc6 和 fc7 层),以降低这些层过拟合的可能性。由于全连接层在模型中倾向于学习高度复杂的模式,它们更容易对训练数据产生过拟合。通过应用 Dropout,AlexNet 能够在这些层中强制模型学习到更加鲁棒和泛化的特征表示。
Dropout 的优点
- 减少过拟合:Dropout 通过减少神经元间的复杂共适应性,强制网络学习更加独立的特征表示,从而降低过拟合风险。
- 模型平均化:Dropout 可以被视为一种模型集成的方法,在每次训练迭代中,相当于训练了一个稍微不同的网络,最后所有这些网络的"综合效果"形成了最终模型,这类似于 bagging 方法中的模型平均,有助于提高泛化性能。
- 简化网络:Dropout 在一定程度上模拟了更简单模型的行为,因为每次迭代只有部分网络被激活,这有助于网络学习更简单的决策边界。
注意事项
尽管 Dropout 有诸多优点,但它也有潜在的副作用,比如可能会增加训练时间,因为模型需要更多的迭代次数来收敛。此外,Dropout 不适用于所有的网络层,特别是卷积层,因为卷积层通常负责学习低级和中级的图像特征,这些特征往往对位置较为敏感,直接丢弃可能会丢失重要的位置信息。

1.7 训练细节

1.8 模型性能评估
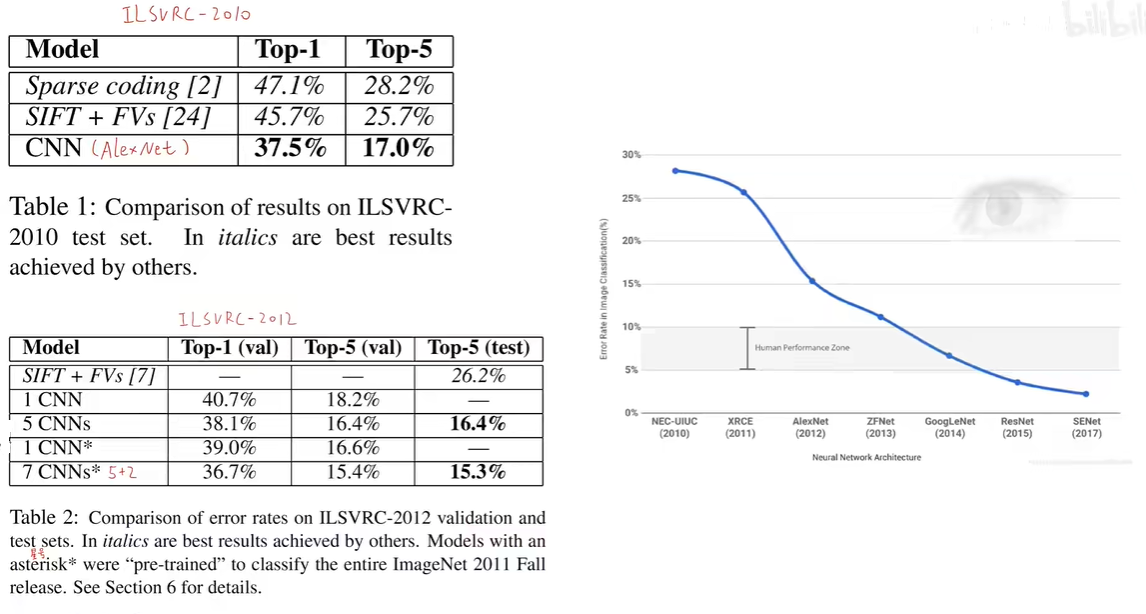
Alexnet做到了提取图像中的语义信息。

2.pytorch模型复现
python
# Author:SiZhen
# Create: 2024/6/2
# Description: pytorch实现Alexnet模型
import torch
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self,num_classes=1000,init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3,48,kernel_size=11,stride=4,padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(48,128,kernel_size=5,padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(128,192,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192,192,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192,128,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128*6*6,2048), #全连接层
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048,2048),
nn.ReLU(inplace=True),
nn.Linear(2048,num_classes),
)
def forward(self,x):
x = self.features(x)
x = torch.flatten(x,start_dim=1)
x = self.classifier(x)
return x