OpenAI正在研究如何破解GPT-4的思维,并公开了超级对齐团队的工作,Ilya Sutskever也在作者名单中。
GPT-4o是否具备记忆能力?DeepMind和开源社区解开LLM记忆的谜团 !_
GPT-4o深夜发布!Plus免费可用!![]() https://www.zhihu.com/pin/1773645611381747712
https://www.zhihu.com/pin/1773645611381747712
没体验过OpenAI最新版GPT-4o?快戳最详细升级教程,几分钟搞定:
升级ChatGPT-4o Turbo步骤![]() https://www.zhihu.com/pin/1768399982598909952
https://www.zhihu.com/pin/1768399982598909952
该研究提出了一种改进大规模训练稀疏自编码器的方法,并成功将GPT-4的内部表征解构为1600万个可理解的特征。
这使得复杂语言模型的内部工作变得更加透明。
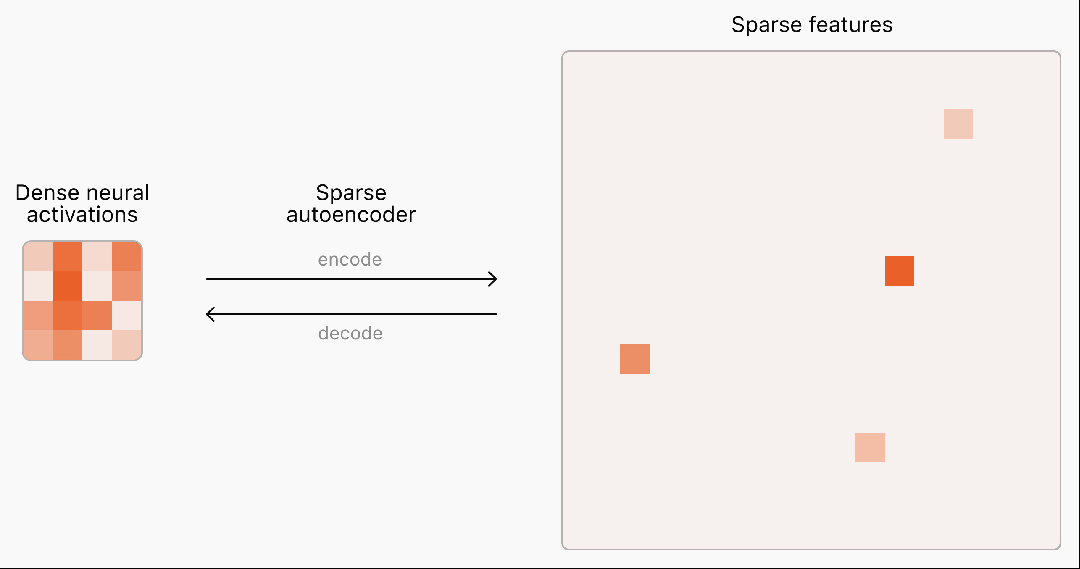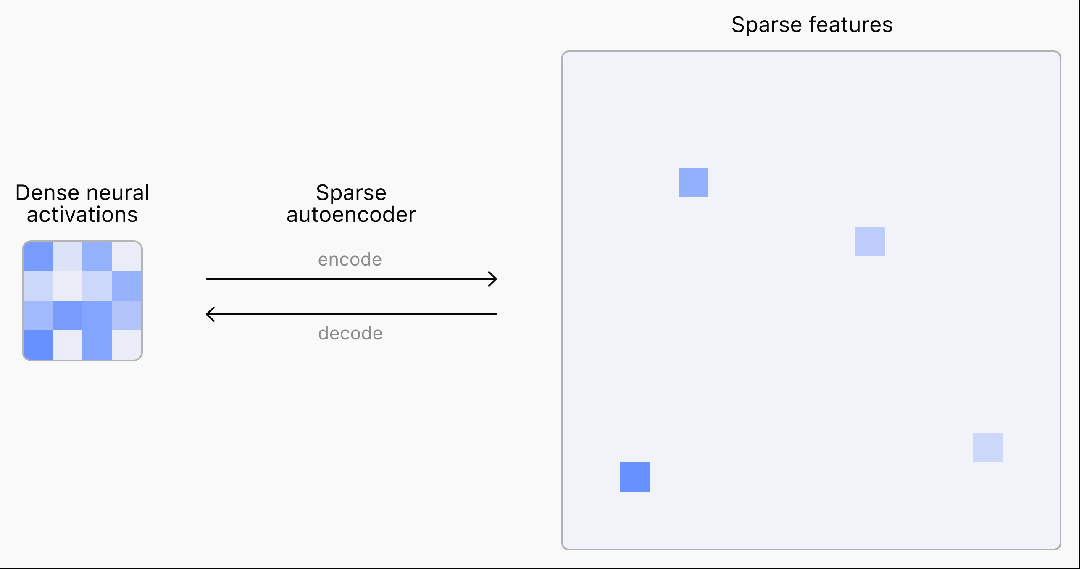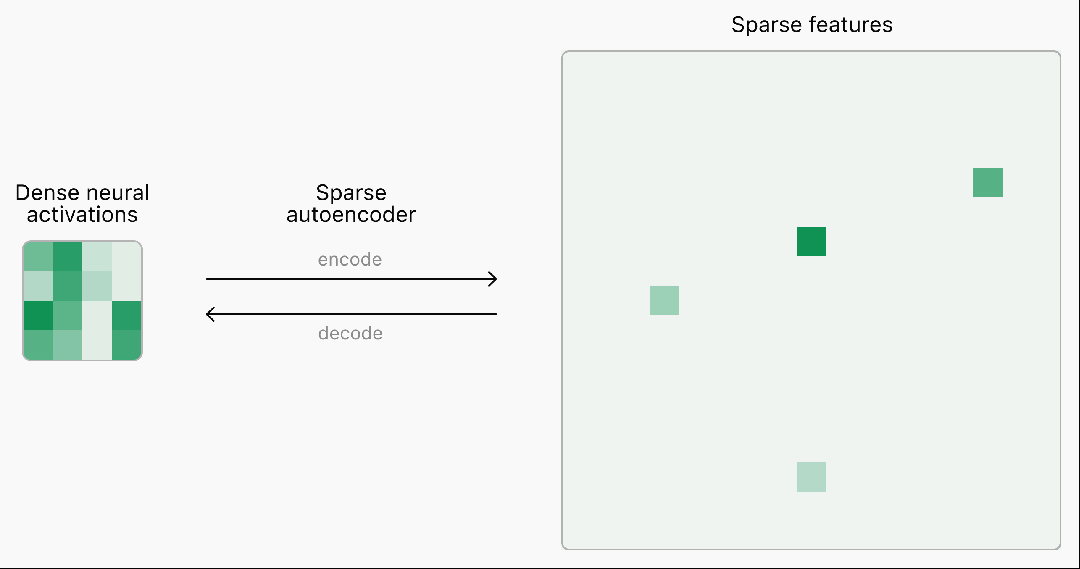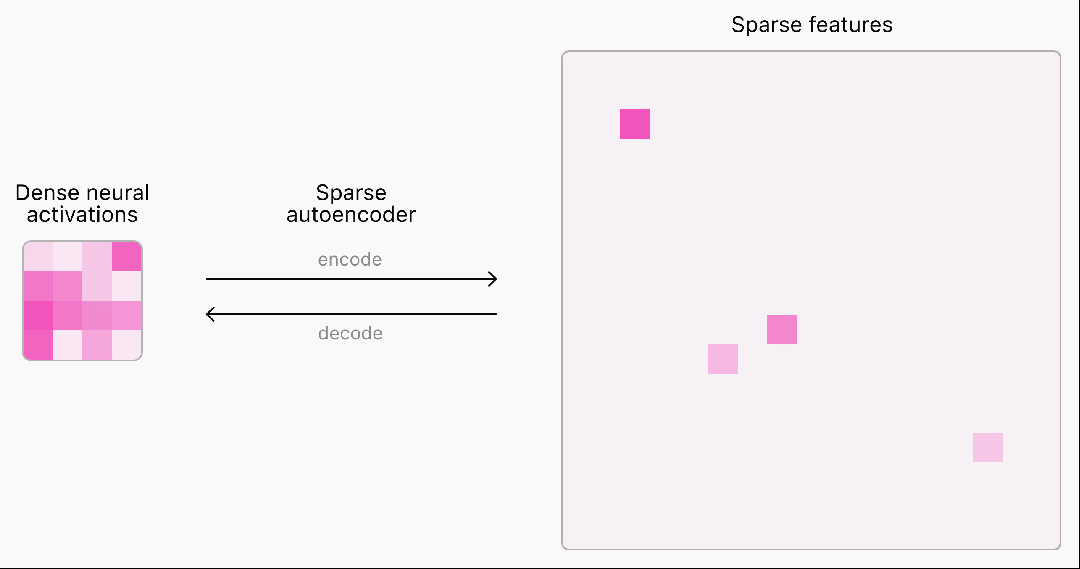
目前,语言模型神经网络的内部工作原理仍是一个"黑盒",无法完全理解。
为了理解和解释神经网络,首先需要找到对神经计算有用的基本构件。
然而,神经网络中的激活通常表现出不可预测和复杂的模式,每次输入几乎总会引发密集的激活。
而现实世界中其实很稀疏,在任何给定的情境中,人脑只有一小部分相关神经元会被激活。
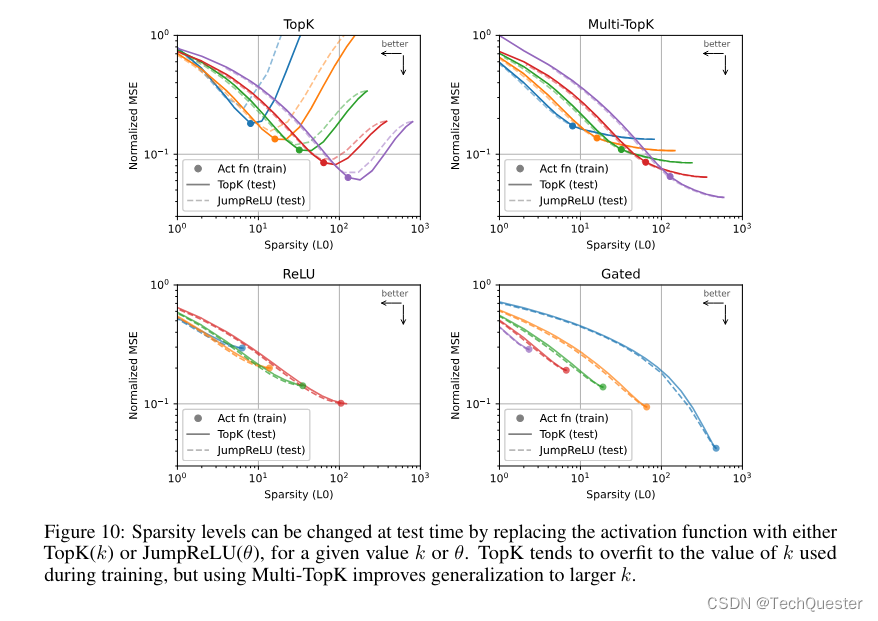
在OpenAI超级对齐团队的这项研究中,他们推出了一种基于TopK激活函数的新稀疏自编码器(SAE)训练技术栈,消除了特征缩小问题,能够直接设定L0(直接控制网络中非零激活的数量)。
该方法在均方误差(MSE)与L0评估指标上表现优异,即使在1600万规模的训练中,几乎不产生失活的潜在单元(latent)。
具体来说,他们使用GPT-2 small和GPT-4系列模型的残差流作为自编码器的输入,选取网络深层(接近输出层)的残差流,如GPT-4的5/6层、GPT-2 small的第8层。
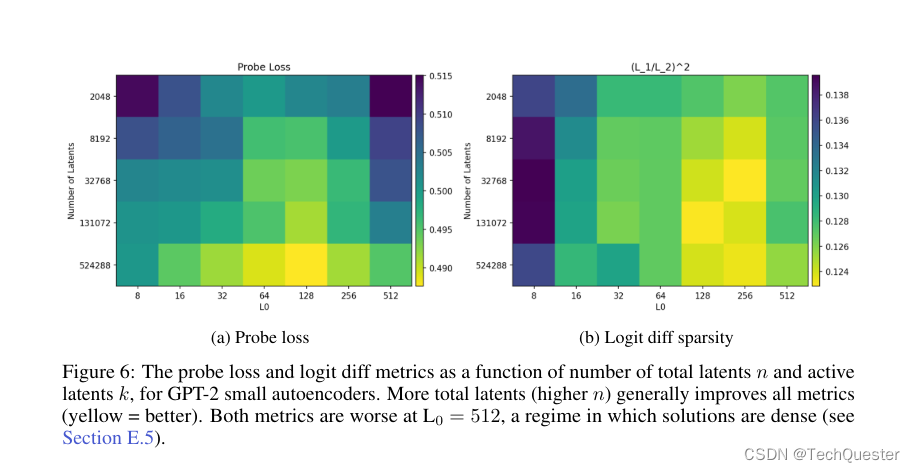
并使用之前工作中提出的基线ReLU自编码器架构,编码器通过ReLU激活获得稀疏latent z,解码器从z中重建残差流。
损失函数包括重建MSE损失和L1正则项,用于促进latent稀疏性。
此外,自编码器训练时容易出现大量latent永远不被激活(失活)的情况,导致计算资源浪费。
团队的解决方案包括两个关键技术:
-
将编码器权重初始化为解码器权重的转置,使latent在初始化时可激活。
-
添加辅助重建损失项,模拟用top-kaux个失活latent进行重建的损失。
通过这些方法,即使是1600万latent的大规模自编码器,失活率也只有7%。
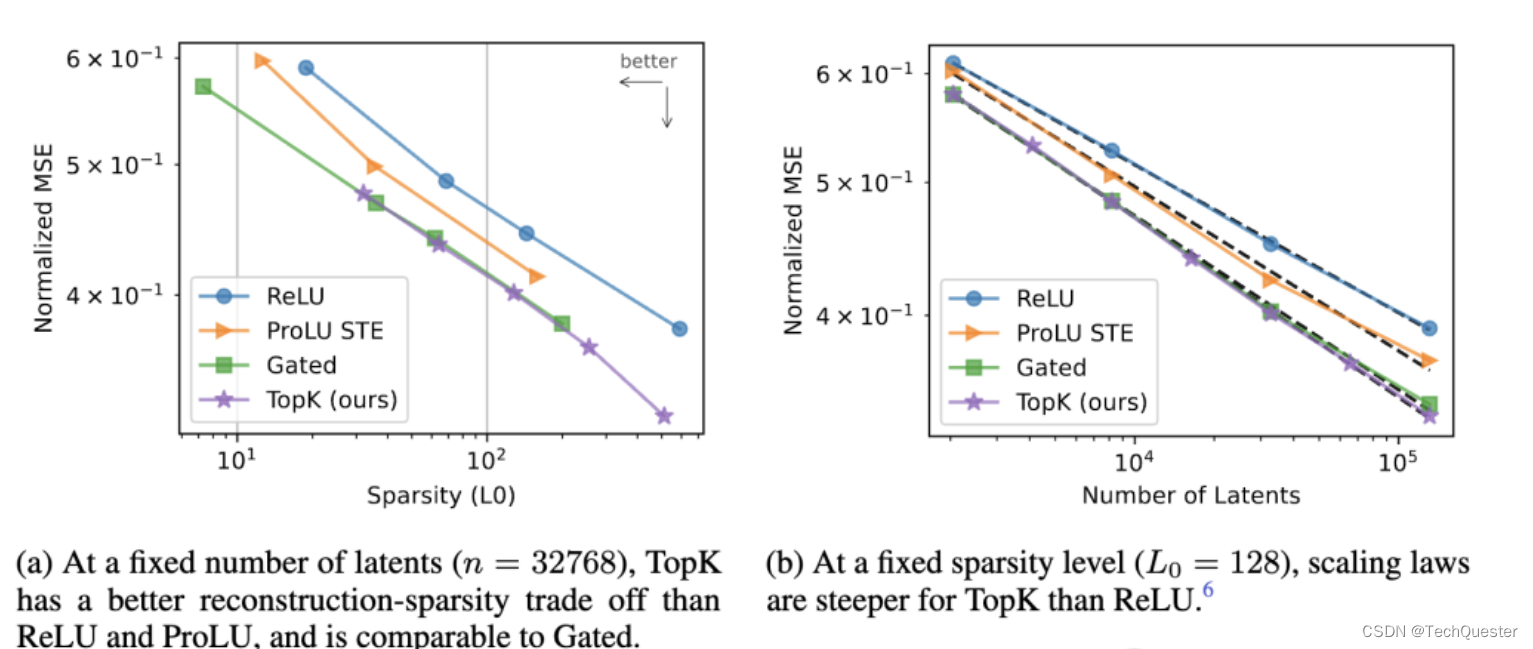
团队还提出了多重TopK损失函数的改进方案,提高了高稀疏情况下的泛化能力,并且探讨了两种不同的训练策略对latent数量的影响,这里就不过多展开了。
推荐阅读: