相信很多的小伙伴,有些是大数据测试岗位,有些是ETL开发,都面临着如何要造数据的情况。
1,造数背景
【大数据测试岗位】,比较出名的就是宁波银行,如果你在宁波银行做大数据开发,对着需求开发完代码之后,可能需要把代码提交给测试人员,那么测试人员会根据这个业务需求,他们会自己造一批数据,然后看看你的sql脚本,是不是有一些明显的sql错误,以及开发规范的问题。当然,还有最重要的一点是,他们会拿着你的脚本取跑数,看看的出来的数据是不是符合业务的逻辑与需求。
如果是【ETL开发岗位】,那么在你连通了HIVE和其他的数据库(比如说,Oracle,mysql,kingbases等等),接着你把代码也开发好了,那么怎么判断你的数据是不是ETL到目标数据库里面了呢?当然是自己先在源数据库里造一批数据,然后走调度跑脚本,如果不报错的情况下,我们再到目标数据库里查看一下,我们之前造的数据是不是ETL过去了。
如果是【大数据开发岗位】,那基本不咋造数据,因为在测试环境,就是有测试数据,还有生产上来的脱敏数据。这些都是可以拿来借鉴参考开发的。
2,造数阶段
那么如何造数呢??直接上 HUE 摸鱼儿展示一下
一张图拿捏:
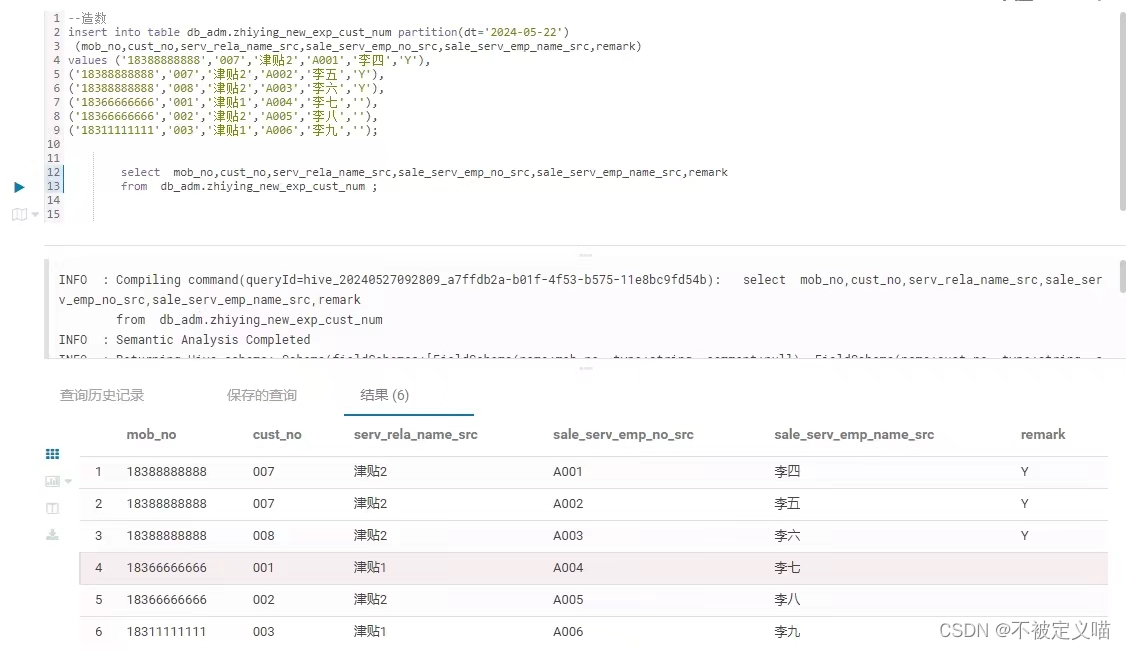
3,造数代码
sql
--如果是分区表(直接建立分区,同时往该分区插入数据)
insert into table xxxx partiton ( dt = '2024-05-27' )
(字段1,字段2,字段3......)
values (值1,值2,值3.......)
, (值4,值5,值6.......)
--如果不是分区表
insert into table xxxx
(字段1,字段2,字段3......)
values (值1,值2,值3.......)
, (值4,值5,值6.......)4,造数逻辑
当然,造数代码不难,但是数据可不是瞎造的,其中还是有一定的讲究。
1,首先,你得先了解整个需求文档,它的数据的最细粒度是什么??
比如说一个客户对应多个资金账号,那么你就按照最细粒度来造数。
可以造3条数据,一个客户对应3个不同的资金账号。
2,其次,根据需求文档的某些特殊字段进行穷举。
比如说,客户类型字段,总共分为3个,个人客户,机构客户,产品客户。
这个时候,你可以发散出3条数据,穷举出来。
3,也可以根据数据的低概率可能性造数。
比如,非主键字段,可以故意设置一些null值。
比如,要算一个完成率,你可以设置分母为0的情况。
比如,一般一个员工,只能归属于一个营业部,但是你清楚这个业务,你可以把某个客户,分别放在2个不同的营业部下面。
4,最后,我想说,测试人员得要对业务需求文档要有一定的理解。
清楚哪些是开发重点,哪些是争议点,在重点之处下文章,才能取得好的效果。
只有这样子,跑出来的数据才是全面的。你无需造数太多,但一定要麻雀虽小五脏俱全。才能叫校验出开发代码人员的代码有没有漏洞,能不能良好的实现业务需求。
==========================================================
好了,这个知识点就分享到这里。
之后看看给大家分享一下测试数据的岗位的小伙伴是怎么测试你的脚本的,有空也会分享一下ETL开发的流程。
欢迎大家点赞收藏关注,不一定很难,但都是经验之谈。