Amazon云计算
习题
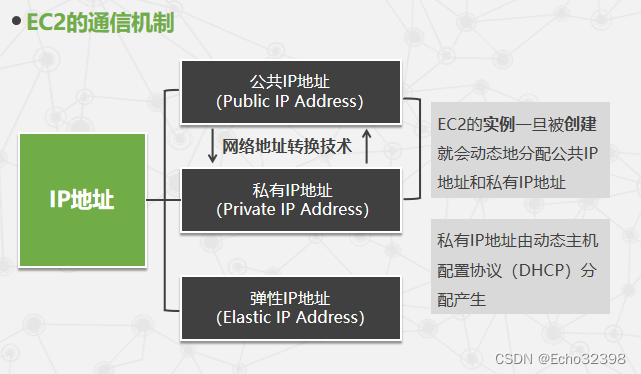
私有IP、公有IP和弹性IP的区别在哪里?
EC2的实例一旦被创建就会动态地分配公共IP地址和私有IP地址。私有IP地址由动态主机配置协议(DHCP)分配产生。
私有IP、公有IP和弹性IP的主要区别在于它们的使用场景、可达性和管理方式:
私有IP:
- 私有IP地址是在局域网(LAN)或云服务的内部网络中使用的IP地址,遵循RFC 1918规定的地址范围,例如10.0.0.0/8、172.16.0.0/12、192.168.0.0/16等。
- 它们主要用于内部通信,不能直接从互联网访问。
- 私有IP地址不需要向Internet Assigned Numbers Authority (IANA)注册,可重复使用于不同的内部网络。
公有IP:
- 公有IP地址是全球唯一的IP地址,由IANA及其地区互联网注册管理机构分配给ISP和大型组织。
- 这些地址可以直接在互联网上路由,使得拥有公有IP的设备可以从全球任何地方直接访问。
- 公有IP常用于托管网站、邮件服务器和其他需要从互联网直接访问的服务。
弹性IP(Elastic IP Address):
- 弹性IP是一种可动态分配给云服务器实例的公有IP地址,主要在云服务提供商(如AWS、阿里云等)中使用。
- 它的特点是可以轻松地重新分配给云平台中的不同资源,而无需改变底层基础设施的配置。
- 弹性IP通常与云服务器的高可用性设计结合使用,允许在服务器实例之间快速转移,同时保持服务的连续性。
- 用户可以根据需求调整弹性IP的带宽和配置,提供了更高的灵活性和控制力。
总结而言,私有IP限于内部网络通信,公有IP直接面向互联网,而弹性IP作为公有IP的一种特殊形式,增加了动态分配和管理的便利性,特别适用于云环境。
地理区域和可用区域有哪些区别?
地理区域是指按照实际的地理位置划分。
可用区域是指是否有独立的供电系统和冷却系统等,通常将每个数据中心看做一个可用区域。
地理区域(Region)和可用区域(Availability Zone, AZ)是云计算服务中用来描述数据中心布局和资源分配的两个重要概念,它们之间的区别主要包括:
地理位置和划分依据:
- 地理区域是从实际地理位置和网络延迟的角度进行划分的,代表了一大片物理上的数据中心集群,通常位于不同的国家或地区,以服务于特定地理市场或满足法规遵从要求。同一区域内的服务能够高效协同工作,数据传输延迟低。
- 可用区域则是在单一地理区域内进一步细分,每个可用区域都是一个或多个物理数据中心的集合,拥有独立的供电、网络和冷却系统,以减少共模故障的风险。即使在一个区域内发生自然灾害或重大故障,其他可用区域仍能继续提供服务。
目的和功能:
- 地理区域的主要目的是提供低延迟的服务给特定地区的用户,同时也考虑到数据主权和法律合规性问题。用户可以根据自己的业务覆盖范围和用户分布选择最合适的区域。
- 可用区域的设计旨在实现高可用性和容灾能力,通过在不同可用区域部署服务或数据副本,可以确保即使某个可用区域遇到问题,服务也能迅速切换到其他可用区域,从而维持业务连续性。
选择考虑因素:
- 选择地理区域时,企业会考虑用户所在地的接近度以减少网络延迟,以及遵守当地的数据保护法律。
- 选择可用区域时,则更侧重于提高服务的可靠性和容错能力,以及考虑各区域间的资源分配策略、成本和特定区域的服务特性。
综上所述,地理区域关注的是地理位置和服务覆盖,而可用区域强调的是在同一地理区域内的独立性和故障隔离,两者共同构成了云计算服务的分布式架构基础,支持高效、可靠的云服务部署。
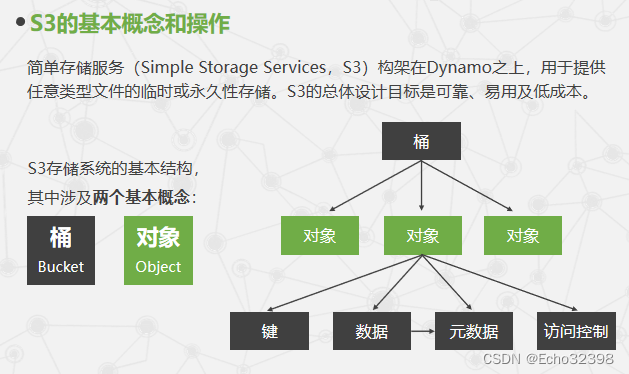
简单存储服务S3与传统的文件系统有哪些区别?
简单存储服务(Simple Storage Services,S3)构架在Dynamo之上,用于提供任意类型文件的临时或永久性存储。S3的总体设计目标是可靠、易用及低成本。
简单存储服务(S3,Simple Storage Service)与传统的文件系统之间存在多方面的差异,主要体现在架构、数据模型、扩展性、数据访问方式以及管理特性等方面:
架构:
S3构建在分布式存储系统之上,如Dynamo,它具有高度分布式、容错的特性,能够跨越多个数据中心(可用区)存储数据,提高数据的持久性和可用性。
传统文件系统通常是本地化的,直接连接到单个或有限数量的服务器上,缺乏分布式存储的灵活性和容错能力。
数据模型:
S3采用对象存储模型,数据组织为"桶(Bucket)"和"对象(Object)",每个对象包含数据本身以及元数据,没有目录层级的概念,适合大规模、非结构化数据的存储。
传统文件系统基于层次化的目录树结构,通过路径来定位文件,支持文件和目录的嵌套。
元数据管理:
S3允许丰富的元数据(包括系统默认和用户自定义元数据)与对象一起存储,便于数据分类、管理和搜索。
传统文件系统虽然也支持元数据,但通常较为有限且不灵活,主要集中在文件属性上。
扩展性和性能:
S3设计为高度可扩展的,能够自动水平扩展以应对数据增长和访问量的增加,无需用户干预。
传统文件系统扩展性较差,增加存储容量或提升性能通常需要手动添加硬件或调整配置。
访问方式和接口:
S3通过RESTful API和SDKs提供访问,支持互联网标准,便于应用程序集成和跨平台访问。
传统文件系统通常通过操作系统API(如POSIX)访问,更适合本地或局域网内的文件操作。
负载均衡和可靠性:
S3通过分布式设计实现负载均衡,确保数据访问的高效和均衡,且内置冗余机制保证数据不丢失。
传统文件系统依赖于硬件RAID等技术来实现一定程度的可靠性,但不如S3在大规模部署下的自动容错和恢复能力强。
成本和运维:
S3作为一种云服务,用户按使用量付费,无需前期硬件投资,且维护由服务提供商负责。
传统文件系统往往需要用户自行购买、维护硬件和软件,成本较高且运维负担重。
综上所述,S3以其分布式特性、高度可扩展性、灵活的元数据管理和易于集成的API,为大规模数据存储和管理提供了优于传统文件系统的解决方案。
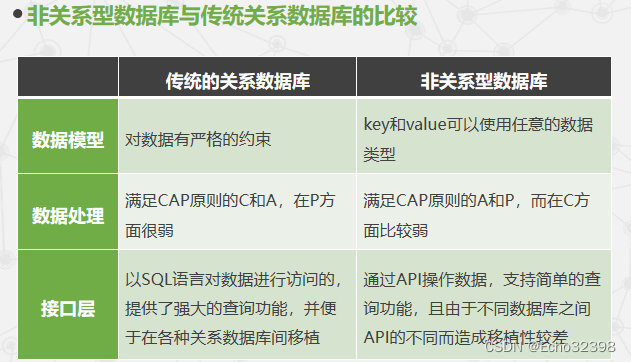
非关系型数据库是如何解决可扩展性问题的?
非关系型数据库(NoSQL)通过多种设计原则和架构特性解决了可扩展性问题,这些包括但不限于:
- 分布式架构:NoSQL数据库天生为分布式系统设计,能够在多台服务器之间分散数据存储和处理任务。这种横向扩展(scale out)的方式,意味着可以通过添加更多的服务器节点来应对数据量的增长和访问量的提升,而不是依赖于单个服务器的升级(纵向扩展,scale up)。
- 无模式(Schema-less)或灵活模式:NoSQL数据库通常不要求严格的数据模式,这使得它们能够更容易地吸收新的数据类型和结构变化,无需预先定义复杂的表结构或进行昂贵的模式迁移。
- 数据分片(Sharding):数据被切分成小块(分片)并分布在不同的节点上,每个节点处理一部分数据。这种策略可以平衡负载,提高查询效率,并简化数据的扩展过程。
- 复制:NoSQL数据库支持数据复制,即在多个节点上保存数据的副本,不仅提高了数据的可用性,也使得读取操作可以分散到不同的副本上,进一步增强了系统的扩展性和性能。
- 一致性模型的灵活性:不同于关系型数据库大多采用强一致性模型,NoSQL数据库提供了从最终一致性到强一致性等多种一致性模型的选择,使得系统可以在扩展性和一致性之间做出权衡。
- 高度优化的数据结构:许多NoSQL数据库针对特定类型的数据访问模式进行了优化,如键值存储(Key-Value)、文档存储、列族存储或图数据库,这使得它们在处理大规模、特定类型数据时更为高效。
- 自动化管理工具:现代NoSQL数据库通常配备有自动化扩展和管理工具,能够根据预设规则或实时负载自动调整资源分配,减少人工干预,简化扩展过程。
综上所述,非关系型数据库通过其内在的分布式特性、灵活的数据模型、数据分片和复制机制,以及对扩展性的深度集成设计,有效解决了数据存储和处理的可扩展性挑战,尤其适合处理大规模、高并发的Web应用和大数据场景。
其他知识点
基础存储架构Dynamo
弹性计算云EC2
简单存储服务S3
非关系型数据库服务SimpleDB和DynamoDB
关系数据库服务RDS
简单队列服务SQS



Windows Azure
习题
微软云计算平台包含几部分?每部分的作用是什么?
微软的云计算服务平台Windows Azure属于PaaS模式,一般面向的是软件开发商。当前版本的Windows Azure平台包括4个组成部分。
Windows Azure 作为微软云计算操作系统,提供了一个在微软数据中心服务器上运行应用程序和存储数据的Windows环境
SQL Azure 它是云中的关系数据库,为云中基于SQL Server的关系型数据提供服务
Windows Azure AppFabric 为在云中或本地系统中的应用提供基于云的基础架构服务
Windows Azure Marketplace 为购买云计算环境下的数据和应用提供在线服务
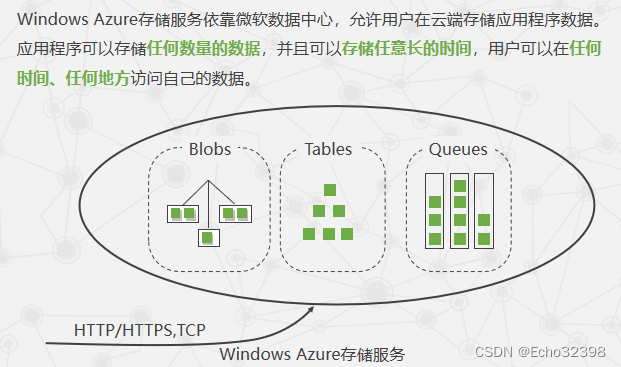
Windows Azure存储服务提供了几种类型的存储方式?阐述每种存储方式主要的存储对象。
提供了三种类型的存储方式。
Table 提供更加结构化的数据存储
Blob 存储二进制数据,可以存储大型的无结构数据,容量巨大,能够满足海量数据存储需求
Queue 用来支持在Windows Azure应用程序组件之间进行通信
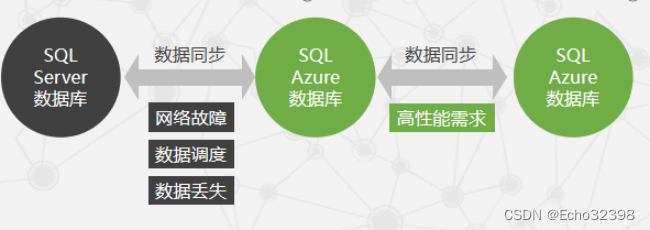
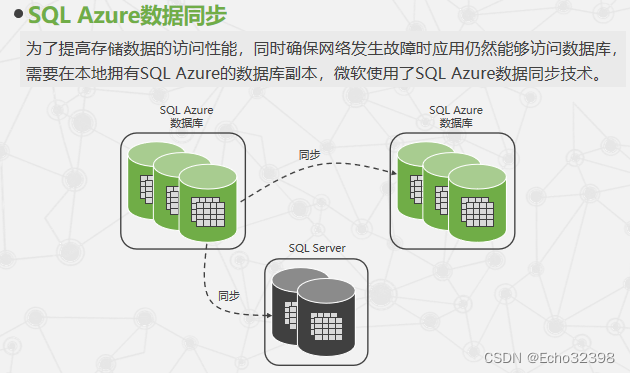
SQL Azure数据同步技术主要有几种?分别如何实现?
为了提高存储数据的访问性能,同时确保网络发生故障时应用仍然能够访问数据库,需要在本地拥有SQL Azure的数据库副本,微软使用了SQL Azure数据同步技术。
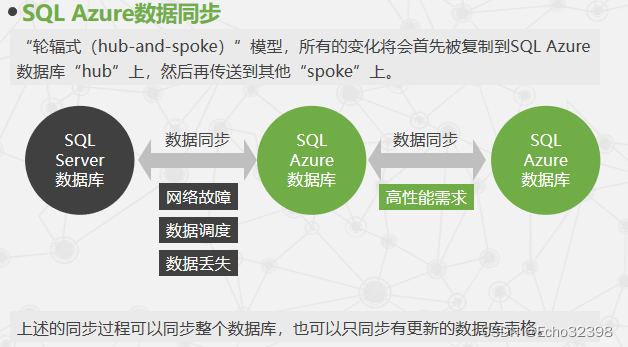
"轮辐式(hub-and-spoke)"模型,所有的变化将会首先被复制到SQL Azure数据库"hub"上,然后再传送到其他"spoke"上。
上述的同步过程可以同步整个数据库,也可以只同步有更新的数据库表格。
阐述SQL Azure和SQL Server的相同点和不同点。
1.物理管理和逻辑管理
SQL Azure能够自动复制所有存储的数据以提供高可用性
SQL Azure还可以管理负载均衡、故障转移等功能
用户不能管理SQL Azure的物理资源
SQL Azure不能使用SQL Server备份机制
2.服务提供
部署SQL Azure时,准备和配置所需要的硬件和软件均由SQL Azure服务程序来执行
用户在Windows Azure平台上创建了一个账户后便可以使用SQL Azure数据库
每个SQL Azure订阅都会绑定到微软数据中心的某个SQL Azure服务器上
3.Transact-SQL支持
SQL Azure中由微软进行物理资源的管理, SQL Server Transact-SQL语句都有一些参数并不适用于SQL Azure
4.特征和类型
SQL Azure不支持SQL Server的所有特征和数据类型
SQL Azure提供物理管理,会锁住任何试图操作物理资源的命令语句
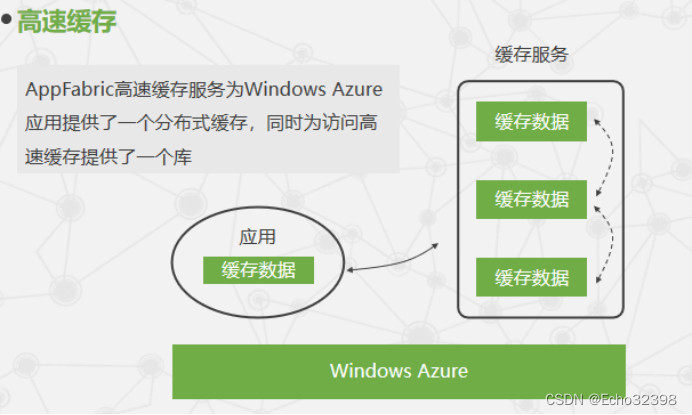
AppFabric高速缓存技术是如何实现的?
高速缓存服务保存每个应用角色实例近期访问数据条款副本的缓存。
如果应用需求的数据条款不在本地的高速缓存中,高速缓存库将会自动地连接高速缓存服务提供的共享高速缓存。
高速缓存可以通过一些Windows Azure实例进行传播,每个实例都保存了不同的缓存数据。

其他知识点
微软云计算平台
微软云操作系统Windows Azure
微软云关系数据库SQL Azure
Windows Azure AppFabric
Windows Azure Marketplace
Windows Azure服务平台








云计算数据中心
知识点
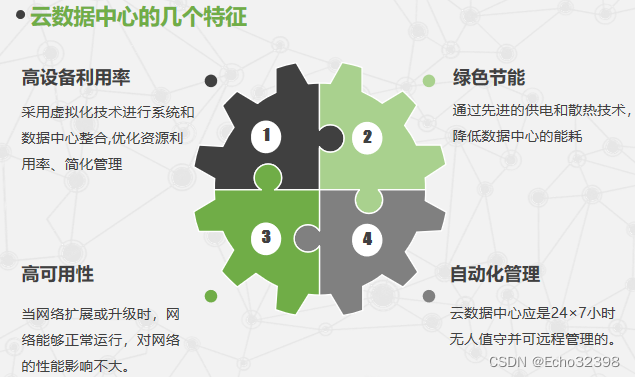
云数据中心的特征
云数据中心网络部署(重点)
