查询性能优化
MySQL查询优化器的局限性
UNION的限制
有时,MySQL无法将限制条件从外层"下推"到内层,这使得原本能够限制部分返回结果的条件无法应用到内层查询的优化上。如果希望UNION的各个子句能够根据LIMIT只取部分结果集,或者希望能够先排好序再合并结果集的话,就需要在UNION的各个子句中分别使用这些子句。例如,想将两个子查询结果联合起来,然后再取前20条记录,那么MySQL会将两个表都存放到同一个临时表中,然后再取出前20行记录:
sql
(SELECT first_name,last_name FROM sakila.actor ORDER BY last_name)
UNION ALL
(SELECT first_name,last_name FROM sakila.customer ORDER BY last_name)
LIMIT 20这条查询将会把actor中的200条记录和customer表中的599条记录存放在一个临时表中,然后再从临时表中取出前20条。可以通过在UNION的两个子查询中分别加上一个LIMIT 20来减少临时表中的数据:
sql
(SELECT first_name,last_name FROM sakila.actor ORDER BY last_name LIMIT 20)
UNION ALL
(SELECT first_name,last_name FROM sakila.customer ORDER BY last_name LIMIT 20)
LIMIT 20现在中间的临时表只会包含40条记录了,除了性能考虑之外,在这里还需要注意一点:从临时表中取出数据的顺序并不是一定的,所以如果想获得正确的顺序,还需要加上一个全局的ORDER BY 和LIMIT操作
索引合并优化
前面已经讨论过,在5.0和更新的版本中,当WHERE子句中包含多个复杂条件的时候,MySQL能够访问单个表的多个索引以合并和交叉过滤的方式来定位需要查找的行
等值传递
某些时候,等值传递会带来一些意想不到的额外消耗。例如,有一个非常大的IN()列表,而MySQL优化器发现存在WHERE、ON或者USING的子句,将这个人列表值和另一个表的某些列相关联。那么优化器会将IN()列表都复制应用到关联的各个表中。通常,因为各个表新增了过滤条件,优化器可更高效地从存储引擎过滤记录,但是如果这个列表非常大,则会导致优化和执行都会变慢。
并行执行
MySQL无法利用多核特性来并行执行查询。很多其他的关系型数据库能够提供这个特性,但是MySQL做不到。这里特别指出是想说不要花时间取尝试寻找并行执行查询的方法。MySQL在处理OLTP场景下的短查询效果很好,但对于复杂大查询则能力有效。最直接一点就是,对于一个SQL语句,MySQL最多只能使用一个CPU核来处理,在这种场景下无法发挥主机CPU多核的能力。MySQL没有停滞不前,一直在发展,新推出的MySQL8.0.14版本第一次引入了并行查询特性,使得check table和select count(*)类型的语句性能成倍提升。虽然目前使用场景还比较优先,但后续的发展值得期待。
- 1.使用方式
通过配置参数innodb_parallel_read_threads来设置并发线程数,就能开始并行扫描功能,默认这个值为4.有个简单的实验,通过sysbench导入2亿条数据,分别配置innodb_parallel_read_threads为1,2,4,8,16,32,64,测试并行执行的效果。测试语句为SELECT COUNT(*) FROM sbtest1;

如图所示。横轴是配置并发线程数,纵轴是语句执行时间。从测试结果来看,整个并行表现还是不错的,扫描2亿条记录,从单线程的18s,下降到32线程的1s。后面并发开再多,由于数量优先,多线程的管理消耗超过了并发带来的性能提升,不能再继续缩短SQL执行时间
- 2.MySQL并行执行
实际上MySQL的并行执行还处于非常初级阶段,如下图所示,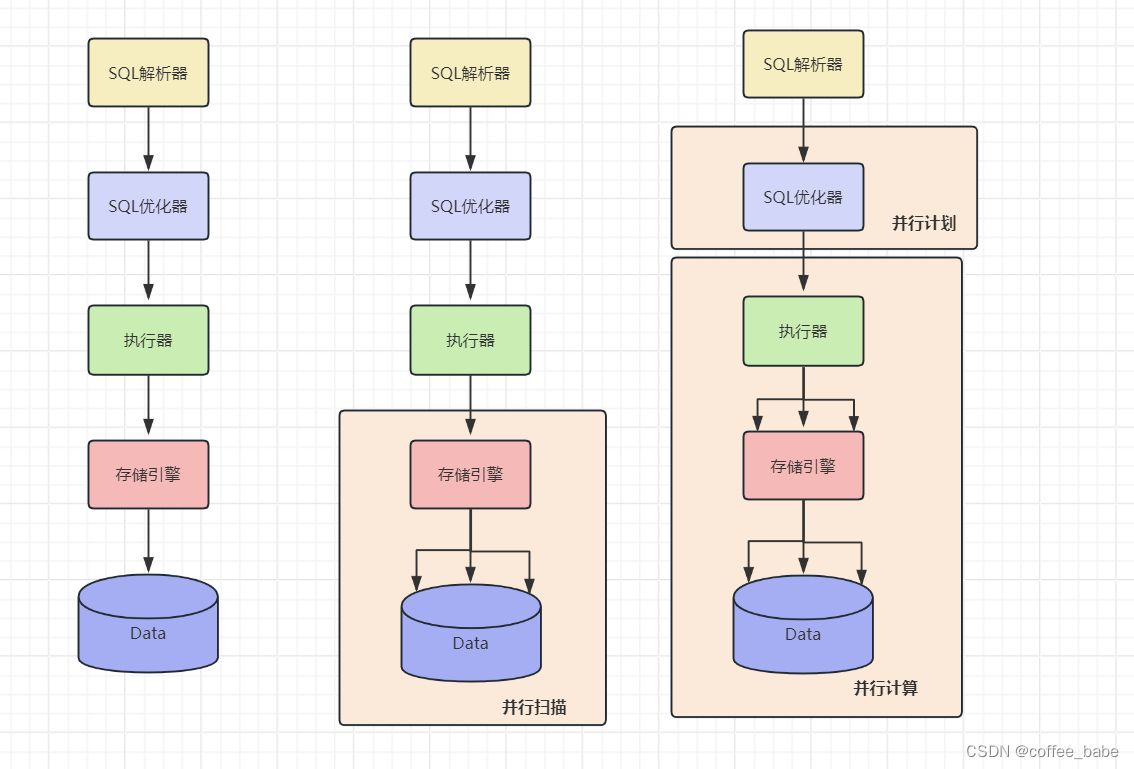
左边是之前MySQL串行处理单个SQL形态;中间的是目前MySQL版本提供的并行能力,InnoDB引擎并行扫描的形态;最右边的是未来MySQL要发展的形态,优化器根据系统负载和SQL生成并行计划,并将分区计划下发给执行器并行执行。并行执行不仅仅是并行扫描,以及并行排序等。目前版本MySQL的上层优化器以及执行器并没有配套的修改。InnoDB的并行扫描主要应用在了分区,并行扫描,预读,以及与执行器交互的适配器类(详细分析请见https://www.cnblogs.com/cchust/p/12347166.html)
哈希关联
MySQL并不支持哈希关联------MySQL的所有关联都是嵌套循环关联。不过,可以通过建立一个哈希索引来曲线地实现哈希关联。如果使用的是Memeory存储引擎,则索引都是哈希索引,所以关联的时候也类似于哈希关联,另外,MariaDB已经实现了真正的哈希关联