前言
JVM.即Java虚拟机.用来解释执行Java字节码.
一、JVM中的内存区域划分
JVM其实也是一个进程,进程运行过程中,要从操作系统这里申请一些资源(内存就是其中的典型资源)
这些内存空间,就支撑了后续Java程序的执行.
JVM从系统中申请了一大块内存,这一大块内存给Java程序使用的时候,又会根据实际的使用用途来划分出不同的空间(区域划分)
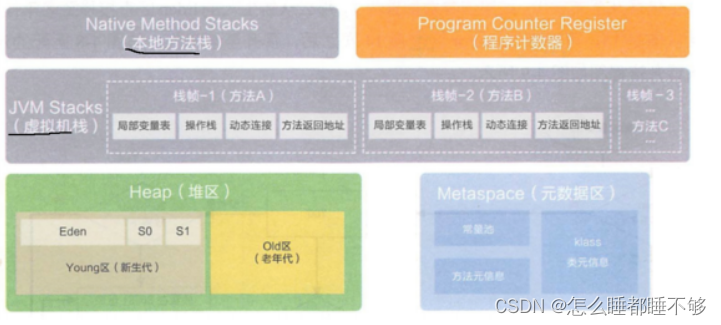
- 堆(只有一份)
代码中new出来的对象,就是在堆里的,对象中持有的非静态成员变量,也就是在堆里.
- 栈(可能有N份)
本地方法栈/虚拟机栈->记录了Java代码的调用关系,Java代码的局部变量
包含了方法调用关系和局部变量
- 程序计数器(可能有N份)
这个区域比较小的空间,专门用来存储吓一跳要执行的Java指令的地址.
- 元数据区(只有一份)(以前也叫方法区)
" 元数据 " 是计算机的一个常见术语(meta data)
往往指的是一些辅助性质的,描述性质的属性.
类的信息,方法的信息:
一个程序,有哪些类,每个类里有哪些方法,每个方法里面都包含了那些指令,都会记录在元数据区里.
硬盘上不仅仅要存文件的数据本体,还需要存储一些辅助信息:
文件的大小,文件的位置,文件的拥有者,文件的修改时间,文件的权限信息.....这些统称为" 元数据 "
比如这样一个代码:
class Test{
private int n;
private static int m;
}
main(){
Test t = new Test();
}这个代码中:
n是Test的成员变量,是在 堆 的.
t是一个局部变量(引用类型),在 栈.
static修饰的变量,称为 " 类属性 "
static修饰的方法,称为 " 类方法 "
非static修饰的变量,称为 " 实例属性 "
非static修饰的方法,称为 ' 实例方法 "
上述带有static 修饰的变量,就是在类对象(.class)中,也就是在元数据区中.
JVM把.class文件加载到内存之后,就会把这里的信息使用对象来表示,此时这样的对象就是类对象.
类对象里就包含了一系列的信息:
包括但不限于:类的名称,类继承自哪个类,实现了哪些接口.
都有哪些属性,都叫什么名字,都是什么类型,都有什么权限.
都有哪些方法,都叫什么名字,都是什么参数,都有什么权限.
java文件中涉及的信息都会在.class中有所体现.
区分一个变量在哪个内存区域中,最主要就是看变量的 " 形态 "(局部变量,成员变量,静态成员变量)
二、JVM的类加载机制
类加载,指的是java进程运行的时候,需要把.class 文件从硬盘,读取到内存,并进行一系列的校验解析的过程.
.class -> 类对象 硬盘 -> 内存
类的加载大体的过程可以分为5个步骤:
- 加载
把硬盘上的.class文件,找到,打开文件,读取到文件的内容,
- 验证
当前需要确保读到的文件的内容,是合法的. class文件(字节码文件)格式
- 准备
给类对象,申请内存空间.
此时申请到的内存空间,里面的默认值,都是全0的.
- 解析
主要是针对类中的字符串常量进行处理
硬盘中没有地址,引用类型的数据无法通过地址存储,就可以使用偏移量,等. class文件加载到内存中后,就有hello的地址了.
- 初始化
针对类对象完成后续的初始化.
还要执行静态代码块的逻辑,还可能会触发父类的加载.
双亲委派模型(加载环节)
描述了如何查找. class文件的策略
JVM中进行类加载的操作,是有一个专门的模块,称为 " 类加载器 "
JVM中的类加载器默认是有三个的
BootstrapClassLoader 负责查找标准库目录
ExtensionClassLoader 负责查找扩展库目录
ApplicationClassLoader 负责查找当前项目的代码目录以及第三方库的目录
上述这三个类加载器,存在 "父子关系",类似于二叉树,有一个指针parent指向自己的父类加载器.
双亲委派模型的工作流程:
1.从ApplicationClassLoader 作为入口,开始工作.
2..ApplicationClassLoader 不会立即搜索自己负责的目录,会把搜索的任务交给自己的父亲.
3.代码就进入到ExtensionClassLoader 范畴了.
ExtensionClassLoader 也不会立即搜索自己负责的目录,也要把搜索的任务交给自己的父亲.
4.代码就进入到BootstrapClassLoader 范畴了.
BootstrapClassLoader 也不会立即搜索自己负责的目录,也要把搜索的任务交给自己的父亲.
- BootstrapClassLoader 发现自己没有父亲,才会真正的开始搜索自己的目录,通过全限定类名,尝试在标准库目录中找到符合要求的.class文件
如果找到了,接下来直接进入打开文件/读文件等流程中.
如果没找到,回到孩子这一辈的类加载器中,继续尝试加载.
- ExtensionClassLoader 收到父亲交回给他的任务后,搜索自己负责的目录
如果找到了,接下来直接进入打开文件/读文件等流程中.
如果没找到,回到孩子这一辈的类加载器中,继续尝试加载.
- ApplicationClassLoader 收到父亲交回给他的任务后,搜索自己负责的目录.
如果找到了,接下来直接进入打开文件/读文件等流程中.
如果没找到,回到孩子这一辈的类加载器中,继续尝试加载.
由于ApplicationClassLoader没有孩子了,此时说明类加载过程失败了,就会抛出ClassNotFountException异常.
上述这一些列规则,只是JVM自带的类加载器,遵守的默认规则,如果自己写类加载器,也可以打破这种规则.
三、垃圾回收机制(GC)
引入了垃圾回收机制后,就不需要手动释放内存了.程序会判定内存是否还需要使用,不需要使用的就会被释放.
STW(stop the world)问题:触发垃圾回收机制的时候,很可能会使当前程序的其他的业务逻辑被暂停.
垃圾回收,是回收内存,JVM的内存有好几块,其中堆是GC的主要战场.
垃圾回收机制的具体展开:
1. 识别出垃圾.
判定一个对象之后是否还需要继续使用,如果一个对象没有任何引用,就会被视为垃圾.
如果有多个引用指向同一个对象,那些引用的生命周期又各不相同,此时情况就会比较复杂.
1.1 引用计数
给每个对象安排一个空间,记录有多少个引用指向当前对象,当垃圾回收机制发现这个计数为0,就可以回收这个空间了.
但是引用计数会有一个问题,如果A对象的一个引用指向了B对象,B对象的一个引用又指向了A对象,然后指向AB的引用各自置为null,就会导致这两块空间都无法被回收

2. 可达性分析(JVM所使用的)
本质上就是时间换取空间,再写代码的时候,会定义很多的变量,就可以从这些变量出发,尝试进行遍历.
所谓的遍历就是沿着这些变量中持有的引用类型的成员,在进行下一步的访问,无法被访问到的就会被视为垃圾.
2. 把标记为垃圾的对象内存空间进行释放
主要的释放方法有三种:
a. 标记-清除
把标记为垃圾的对象,直接释放掉.
但是会导致内存碎片问题,所以一般不使用这个方案
所谓内存碎片,就是一块完整的内存,其中有一些地方被标记为垃圾,被释放掉,但是时候申请内存的时候,如果总内存足够,但是因为有内存碎片,就会导致没有一块连续的内存的空间达到要申请的空间的大小,此时,去申请空间就会失败.
例如,要申请1M的空间,总的空闲空间比1M 大,但是空闲空间是1000个碎片,每个碎片是10K,此时空闲空间是10M,但是每个碎片都是小于1M的,就会申请失败.
b. 复制算法
复制算法,核心就是不直接释放内存,而是把不是垃圾的对象,复制到另一块内存.,然后把之间的空间全部释放.
这样确实可以解决碎片问题,但是会导致:
-
总的可用空间变少了.
-
如果每次要复制的对象比较多,此时复制的开销就会很大.
所以这种方法一般适用于少数对象存活.
c. 标记-整理
类似于顺序表,释放一个空间后,会把后面的元素向前搬运.
但是这种方法的搬运内存开销非常大.
分代回收
由于上述垃圾回收机制,都存在问题,所以JVM自己弄出了一个方案.
引入概念:对象的年龄
JVM中有专门的线程负责周期性扫描/释放
一个对象,如果被线程扫描了一次,可达了,年龄就+1(初始为0)
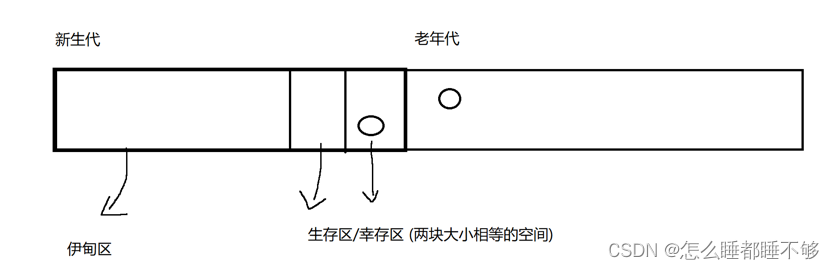
-
当代码中new出一个新对象的时候,这个对象就是被创建在伊甸区的
-
第一轮GC扫描完后,少数伊甸区中幸存的对象,就会通过复制算法,拷贝到生存区.
后续再进行扫面,如果这个对象再生存区中还存活者,就会继续被拷贝到另一半生存区中.
-
如果这个对象在生存区中经过GC多轮扫描依旧存在,就会被拷贝到老年区代.
-
老年代的对象,被GC扫描的频率就会大幅度降低了.
-
对象在老年代寿终正寝,此时JVM就会按照标记整理的方式,释放内存.