频繁项集、闭项集和关联规则
频繁项集:出现的次数超过最小支持度计数阈值
闭频繁项集:一个集合他的超集(包含这个集合的集合)在数据库里面的数量和这个集合在这个数据库里面的数量不一样,这个集合就是闭项集
如果这个集合还是频繁的,那么他就是极大频繁项集
项集{a,b}出现在TID为1,2的事务中,其支持度计数为2。而它的直接超集{a,b,c}支持度计数也为2,所以{a,b}不是闭项集。
Apriori算法
手撕例题

STEP1.候选1项集→频繁1象集
拿到候选数据后,我们先筛选出候选频繁1象集,并算出它们的支持度【支持度=有购买该物品的人/总人数】 ,完成这一操作后,将它和题目中给出的最小支持度作比较,从而得到频繁1象集!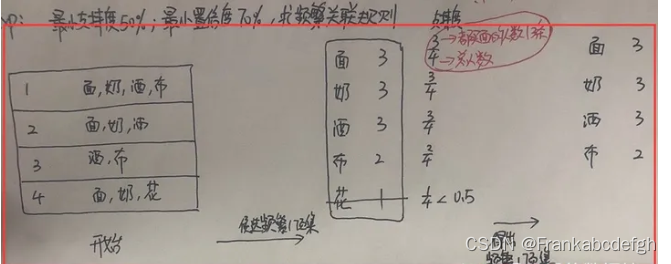
STEP2-3.重复上述步骤, 进行候选2项集→频繁2象集;候选3项集→频繁3象集的过程直到不能够再往下为止(例如,本题到频繁3象集,{面、奶、酒}为止)。 
STEP4.写出最终频繁N象集的非空真子集,如题中**{面、奶、酒}的非空真子集** 如下所示,并分别计算它们的置信度!(注意!这里不再是计算支持度了哈!别和上面搞混了!)
举个例子,我们要求{面}→{奶、酒}的置信度,翻译一下即,我们想知道买了面的人,有多大可能性也买了奶、酒,即同时买面、奶、酒的人数/买面的人数=2/3!
后续同理,我们可以得到所有关系的置信度,最后我们再拿题干中的最小置信度和算出来的置信度进行比较 !就能得出最终的强关联规则(同时满足最小支持度、置信度) 
fp树
先建立频繁1项集
递减排序
通过一行行事务进行建立树(如果有相同路径数字加1,没有创建新的子树)

挖掘出频繁项集

关联规则
同时满足支持度以及置信度
强规则不一定是有趣的
强规则有一定欺骗性(置信度存在问题)可能某商品是必须品
从关联分析到相关分析
提升度
lift(A,B)=P(AnB)/P(A)*P(B)
>1正相关,一个出现另一个就出现
<1负相关,一个出现另一个就不出现
=1独立