一、启动和关闭节点
1、在NameNode节点上
(1)启动hdfs
start-dfs.sh (2)关闭hdfs
stop-dfs.sh 2、在ResourceManager节点上
(1)启动yarn
start-yarn.sh(2)关闭yarn
stop-yarn.sh(3)开启任务历史服务(开启后会存储已提交的任务,有效期为七天)
mapred --daemon start historyserver(4)关闭任务历史服务
mapred --daemon stop historyserver开启的服务都要在关闭虚拟机前关闭!
二、访问Web服务
1、访问NameNode的Web服务
(1)查看hdfs-site.xml配置文件
cd /opt/softs/hadoop3.1.3/etc/hadoop/
cat hdfs-site.xml获取到Web网址
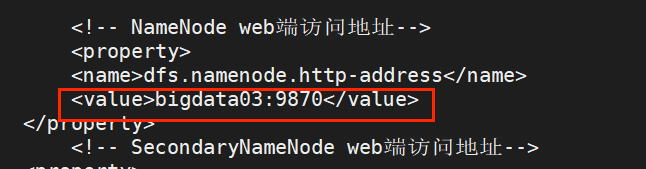
(2)查看/etc/hosts
cat /etc/hosts
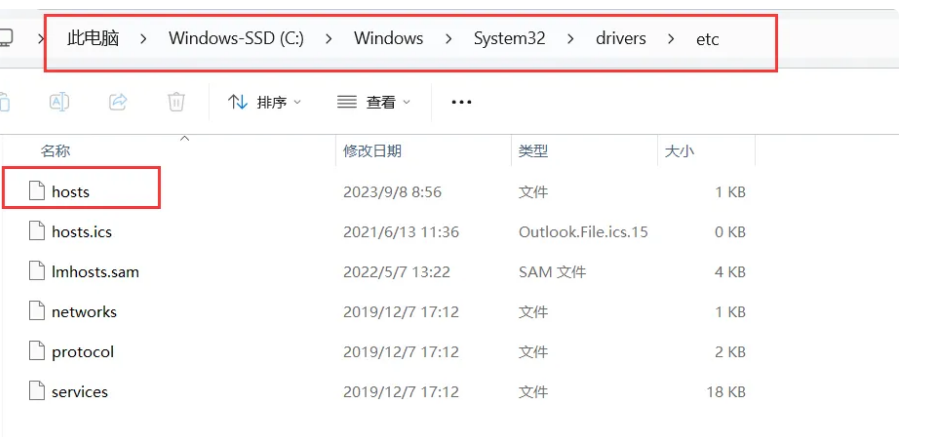
(3)将映射配置复制粘贴到C:\Windows\System32\drivers\etc下的hosts
① 查找位置
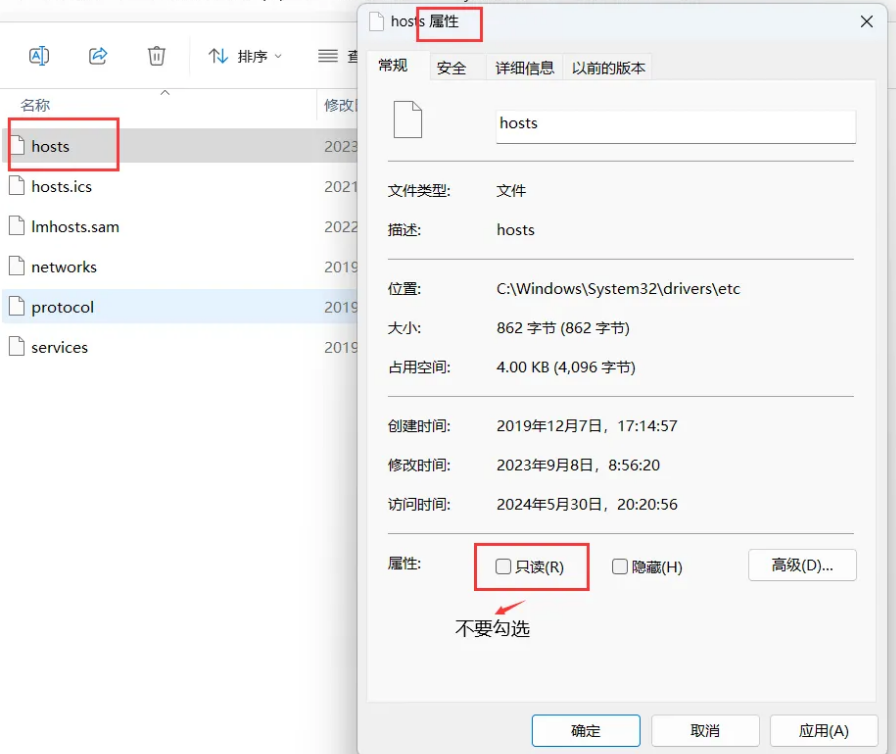
② 修改文件权限

③ 在文件末尾加入对应映射关系

(4)在Windows的浏览器中访问http://bigdata03:9870
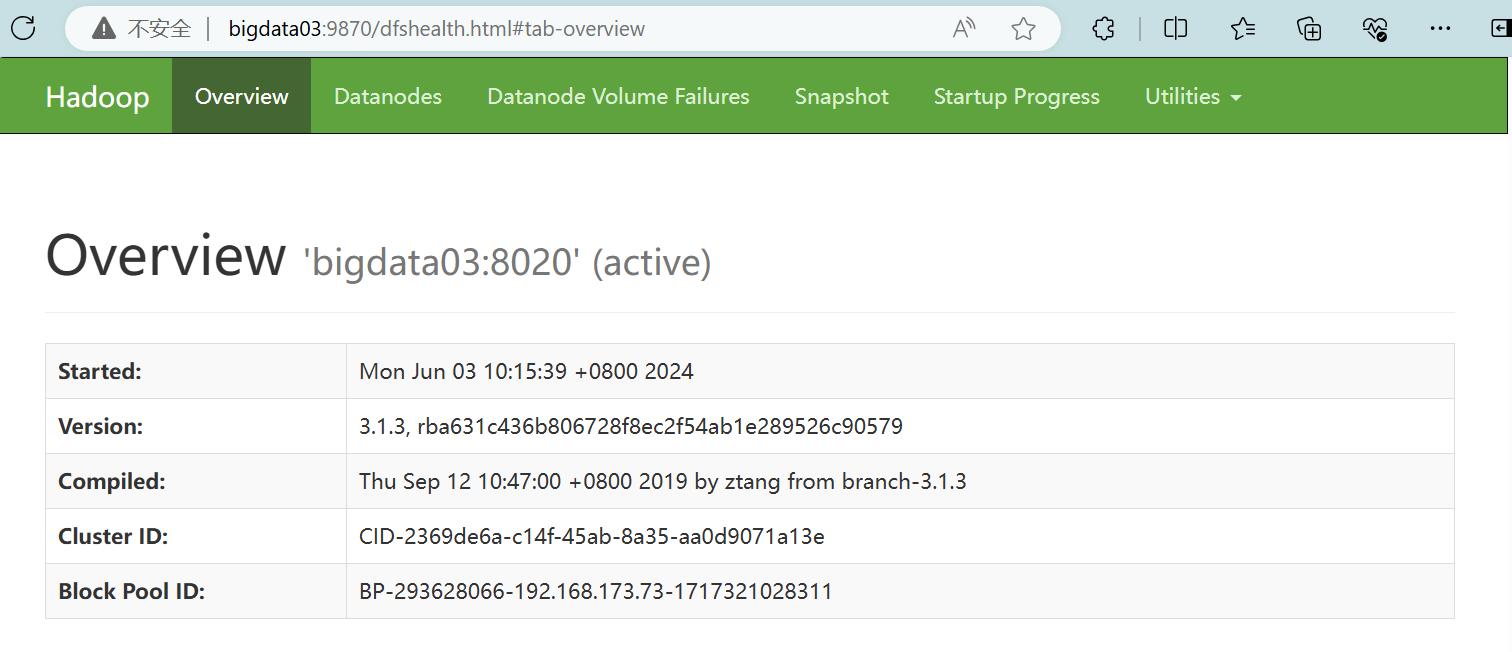
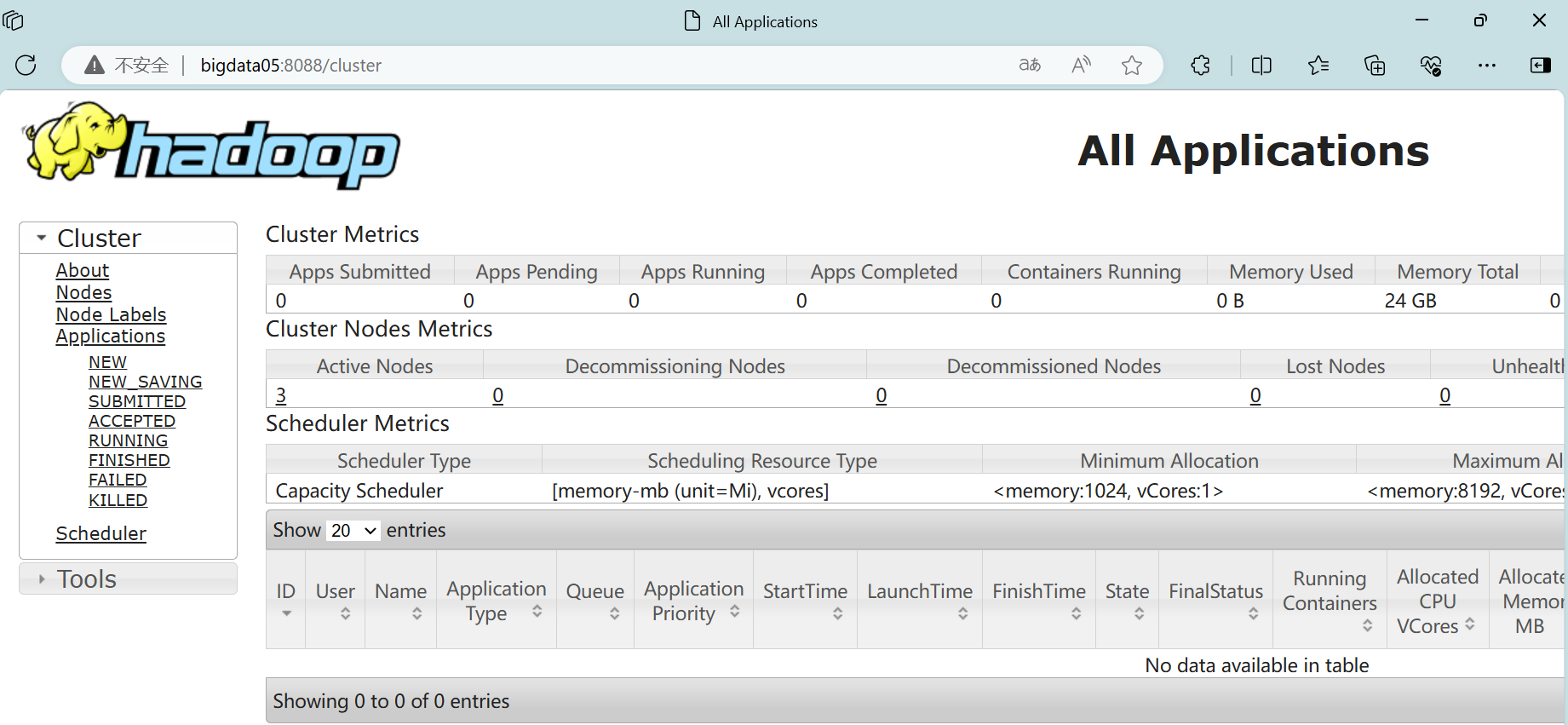
2、访问yarn的Web服务
前面已经配置过了映射关系,可在Windows里直接访问http://bigdata05:8080
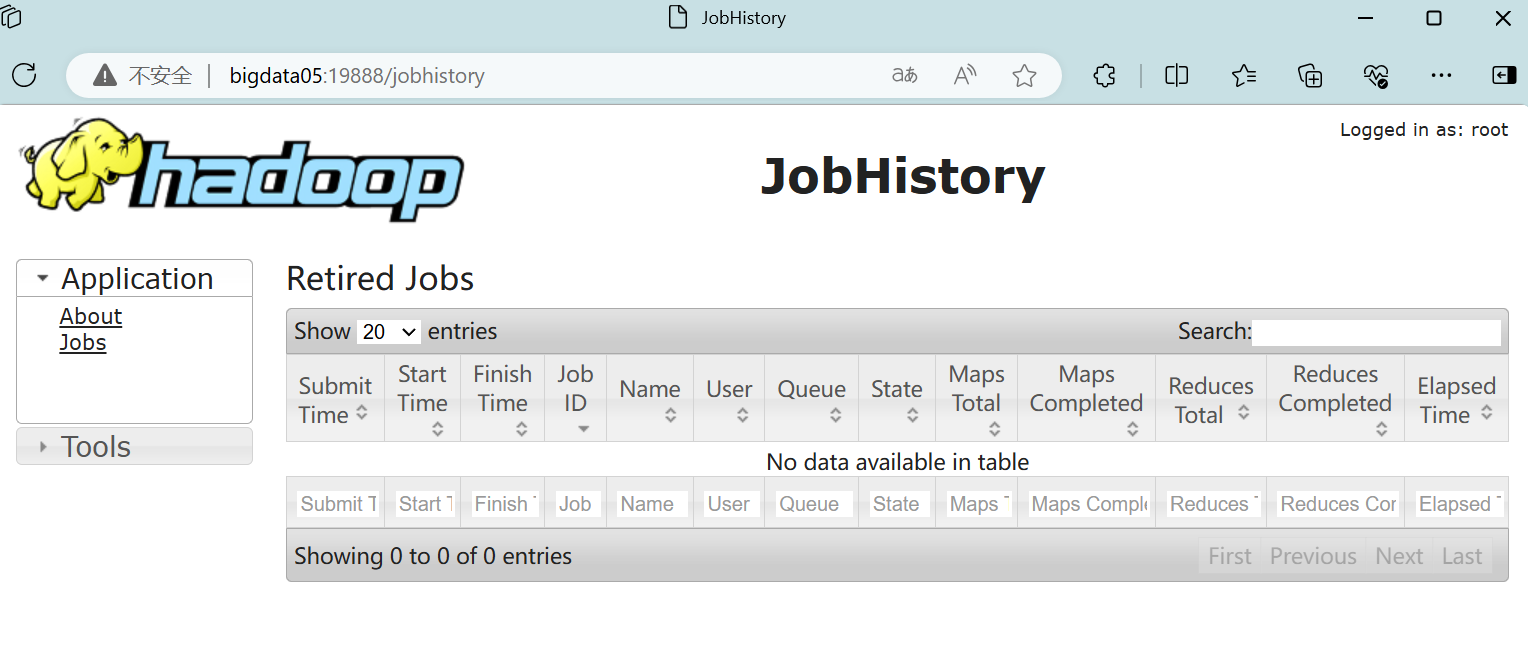
3、访问任务历史服务的Web服务
在ResourceManager节点上查看web网址
cd /opt/softs/hadoop3.1.3/etc/hadoop
cat yarn-site.xml 在Windows中访问网址:http://bigdata05:19888/jobhistory
在Windows中访问网址:http://bigdata05:19888/jobhistory