查询性能优化
MySQL查询优化器的局限性
松散索引扫描
由于历史原因,MySQL并不支持松散索引扫描,也就无法按照不连续的方式扫描一个索引。通常,MySQL的索引扫描需要先定义一个起点和终点,即使需要的数据只是这段索引中很少数的几个,MySQL仍需要扫描这段儿索引中的每一个条目。下面我们通过一个示例说明这点。假设我们有如下索引(a,b),有下面的查询:
sql
mysql>SELECT ... FROM tbl WHERE b BETWEEN 2 AND 3;因为索引的前导字段是列a,但是在查询中只指定了字段b,MySQL无法使用这个索引,从而只能通过全表扫描找到匹配的行,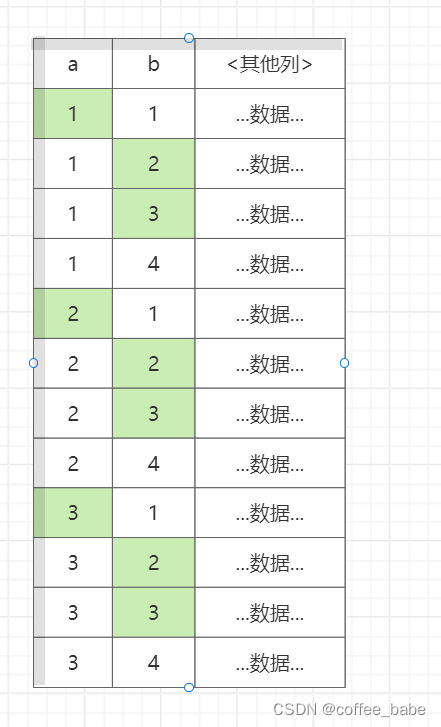
如图所示。了解索引的物理结构的话,不难发现还可以有一个更快的办法执行上面的查询。索引的物理结构(不是存储引擎的API)使得可以先扫描a列的第一个值对应的b列的范围,然后再跳到a列不同第二个不同值扫描对应的b列的范围。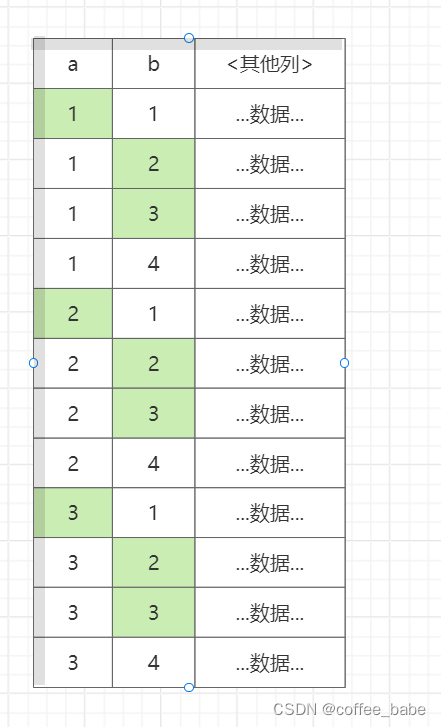
如图所示展示了如果由MySQL来实现这个过程会怎样。注意到,这时就无须再使用WHERE子句过滤,因为松散索引扫描已经跳过了所有不需要的记录。上面是一个简单的例子,除了松散索引扫描,新增一个合适的索引当然也可以优化上述查询。但对于某些场景,增加索引是没用的,例如,对于第一个索引列是范围条件,第二个索引列是等值条件的查询,靠增加索引就无法解决问题。
MySQL5.0之后的版本,在某些特殊的场景下是可以使用松散索引扫描的,例如,在一个分组查询中需要找到分组的最大值和最小值:
sql
mysql> EXPLAIN SELECT actor_id, MAX(film_id)
-> FROM sakila.film_actor
-> GROUP BY actor_id\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film_actor
partitions: NULL
type: range
possible_keys: PRIMARY,idx_fk_film_id
key: PRIMARY
key_len: 2
ref: NULL
rows: 201
filtered: 100.00
Extra: Using index for group-by在EXPLAIN中的Extra字段显示"Using index for group-by",表示这里将使用松散索引扫描,不过如果MySQL能写上"loose index probe",相信会更好理解。在MySQL很好地支持松散索引扫描之前,一个简单的绕过问题的办法就是给前面的列加上可能的常数值。在MySQL5.6之后的版本,关于松散索引扫描的一些限制将会通过"索引下推(index condition pushdown)"的方式解决
最大值和最小值优化
对于MIN()和MAX()查询,MySQL的优化做得并不好。这里有一个例子:
sql
mysql> SELECT MIN(actor_id) FROM sakila.actor WHERE first_name='PENELOPE';因为在first_name字段上并没有索引,因此MySQL将会进行一次全表扫描。如果MySQL能够进行主键扫描,那么理论上,当MySQL读到的第一个满足条件的记录的时候,就是我们需要找到的最小值了,因为主键是严格按照actor_id字段的大小顺序排列的。但是MySQL这时只会做全表扫描,我们可以通过查看SHOW STATUS的全表扫描计数器来验证这一点。一个曲线的优化办法是移除MIN(),然后使用LIMIT来讲查询重写如下:
sql
mysql> SELECT actor_id FROM sakila.actor USE INDEX(PRIMARY)
-> WHERE first_name = 'PENELOPE' LIMIT 1;
+----------+
| actor_id |
+----------+
| 1 |
+----------+
1 row in set (0.00 sec)这个策略可以让MySQL扫描尽可能少的记录数。如果你是一个完美主义者,可能会说这个SQL已经无法表达她的本意了。一般我们通过SQL告诉服务器我们需要什么数据,由服务器来决定如何最优地获取数据,不过在这个案例中,我们其实是告诉MySQL如何去获取我们需要的数据,通过SQL并不能一眼就看出我们其实是想要一个最小值。确实如此,有时候为了获得更高的性能,我们不得不放弃一些原则
在同一个表上查询和更新
MySQL不允许对同一个张表同时进行查询和更新。这其实并不是优化器的限制,如果清楚MySQL是如何执行查询,就可以避免这种情况。下面是一个无法运行的SQL,虽然这是一个符合标准的SQL语句。这个SQL语句尝试将两个表中相似行的数量记录到字段cnt中:
sql
mysql> UPDATE tbl AS outer_tbl
-> SET cnt = (
-> SELECT COUNT(*) FROM tbl AS inner_tbl
-> WHERE inner_tbl.type = outer_tbl.type
-> );
ERROR 1093(HY000):You can't specify target table 'outer_tbl' for update in FROM clause可以通过使用生成表的形式来绕过上面的限制,因为MySQL只会把这个表当作一个临时表来处理。实际上,这执行了两个查询:一个是子查询中的SELECT语句,另一个是多表关联UPDATE,只是关联的表是一个临时表。子查询会在UPDATE语句打开表之前就完成。所以下面的查询将会正常执行:
sql
mysql> UPDATE tbl
-> INNER JOIN (
-> SELECT type, count(*) AS cnt
-> FROM tbl
-> GROUP BY type
-> ) AS der USING(type)
-> SET tbl.cnt = der.cnt;