参考自李宏毅课程-人类语言处理
一、NLP任务总览
1 Introduction
NLP(Natural Language Processing)关注以下两个部分,文本生成文本,文本生成类别:
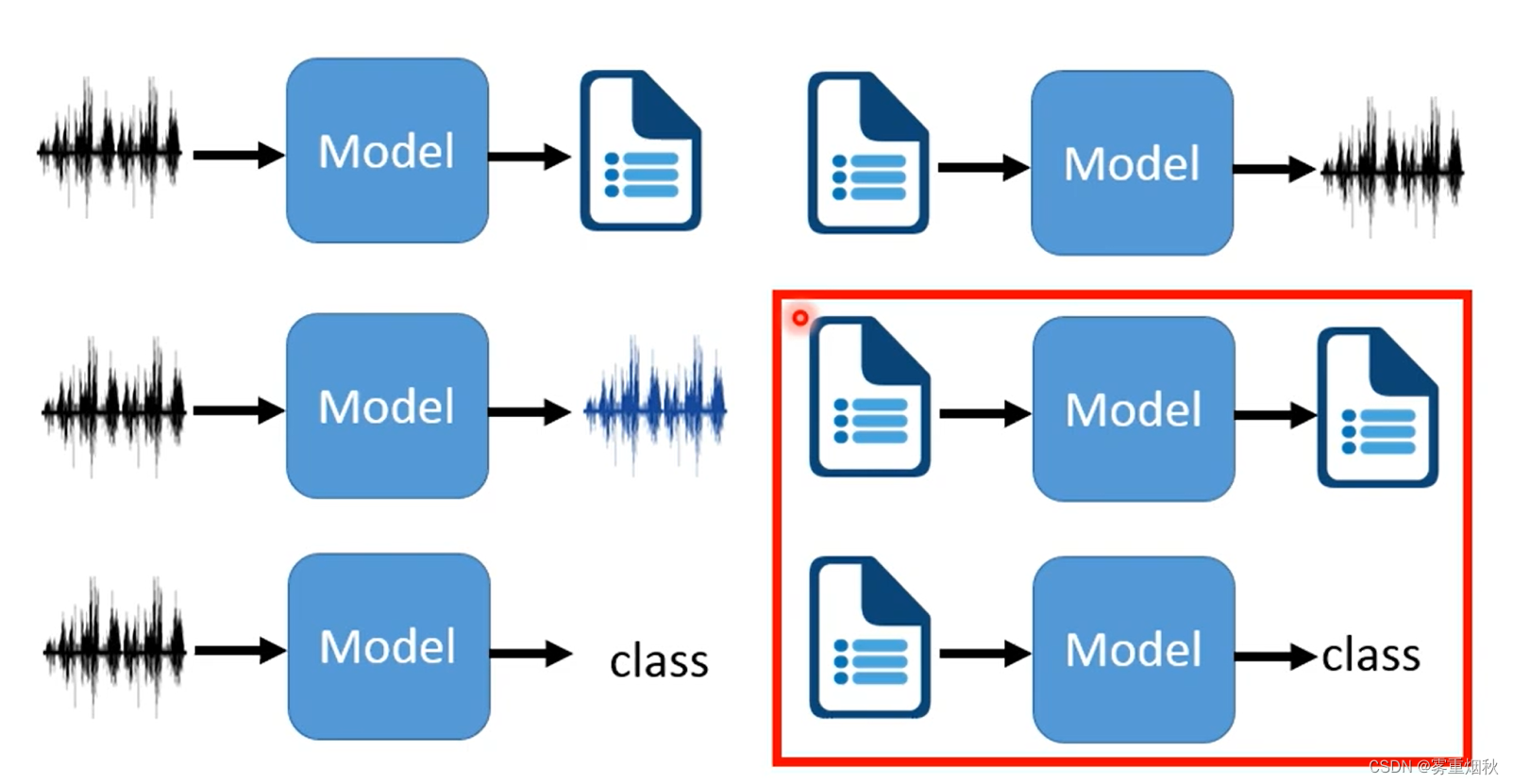
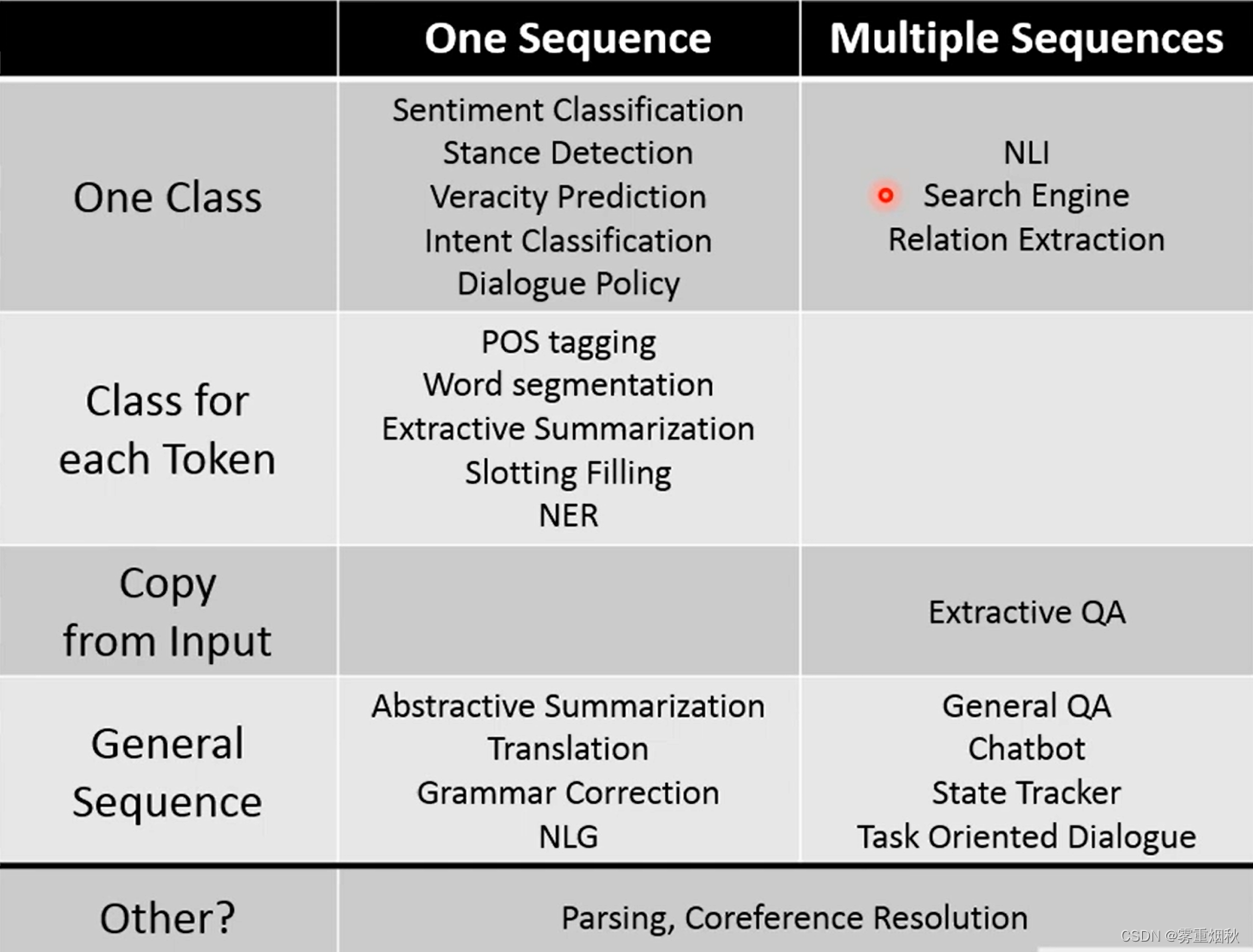
根据输入序列和输出序列的对应关系,又可以细分为以下类别:
2 Part-of-Speech(POS) Tagging
POS Tagging就是给句子中的每个word做词性的判断,是动词,还是形容词,还是名词。输入是文本序列,输出是序列中每个token对应的词性类别,对POS Tagging的前处理可能并不是必要的,因为厉害的模型训练的时候可能自己就学到了,比如Bert。

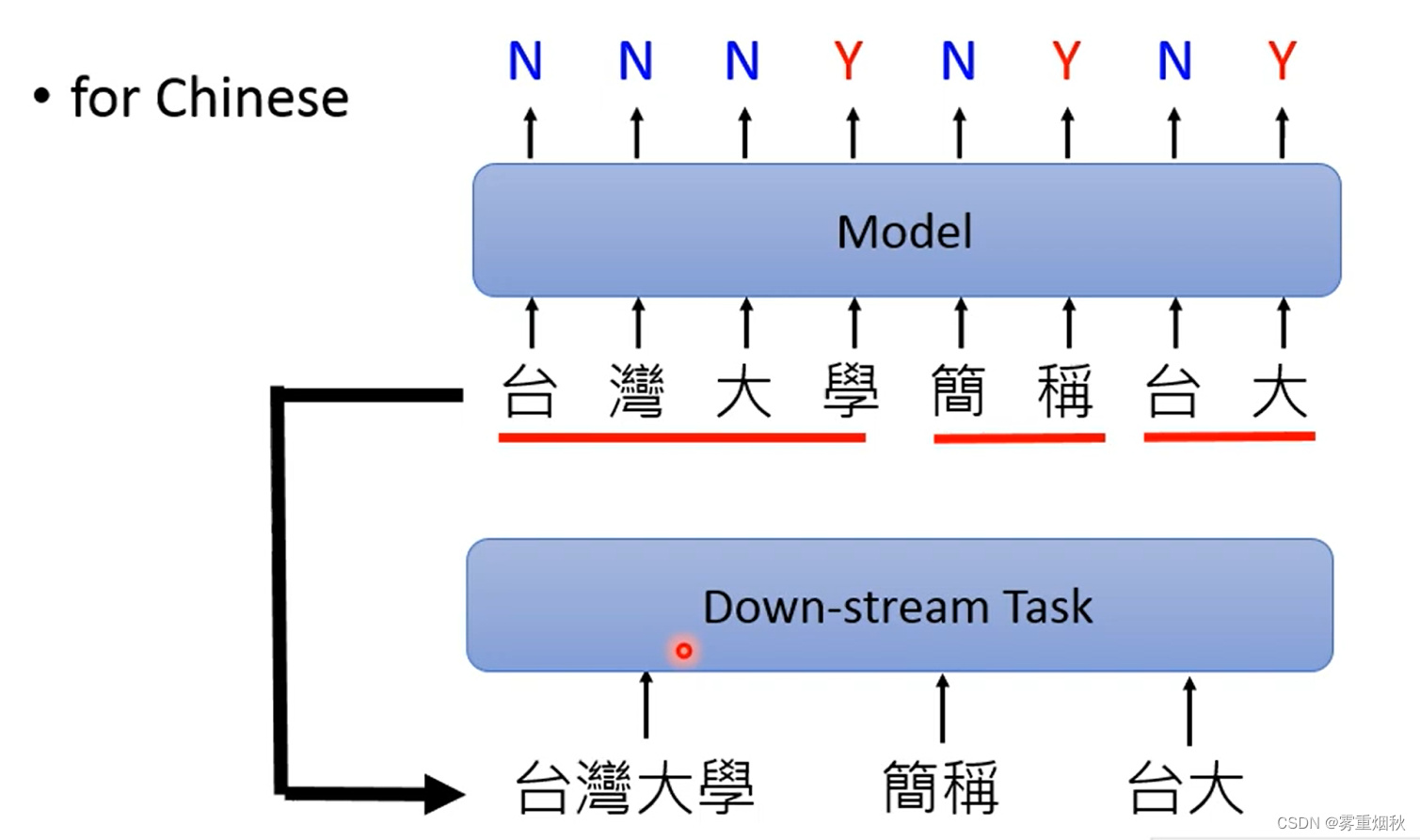
Word Segmentation
Word Segmentation(分词),是前处理的一个内容,输入是文本序列,输出是每个文字对应的类别(是否是词的结尾),这个在现在也不是必须的,厉害的模型可以自己学到。
4 Parsing
Parsing又分为Constituency Parsing和Dependency Parsing,也是前处理。输入的是文本,输出的是树状结构,这种不像"输入文本,输出文本"或"输入文本,输出类别"这两大类,之后会单独讨论。

5 Corference Resolution
Corference Resolution称为指代消解,其目的是找出一个段落中属于同一个东西的短语或词汇。这个也不在那两大类中。

6 Summarization
Summarization(摘要)是输入一篇文章,输出这篇文章的摘要,有两种做法:Extractive summarization和Abstractive summarization。前者是从原文中抄几句话合成摘要,后者是要概括全文的主要内容(鼓励抄一些原文内容)


相当于,Extractive summarization是输入文本序列,输出每个token类别(这里的token是句子),是否放到摘要,Abstractive summarization是输入文本序列,输出摘要序列。
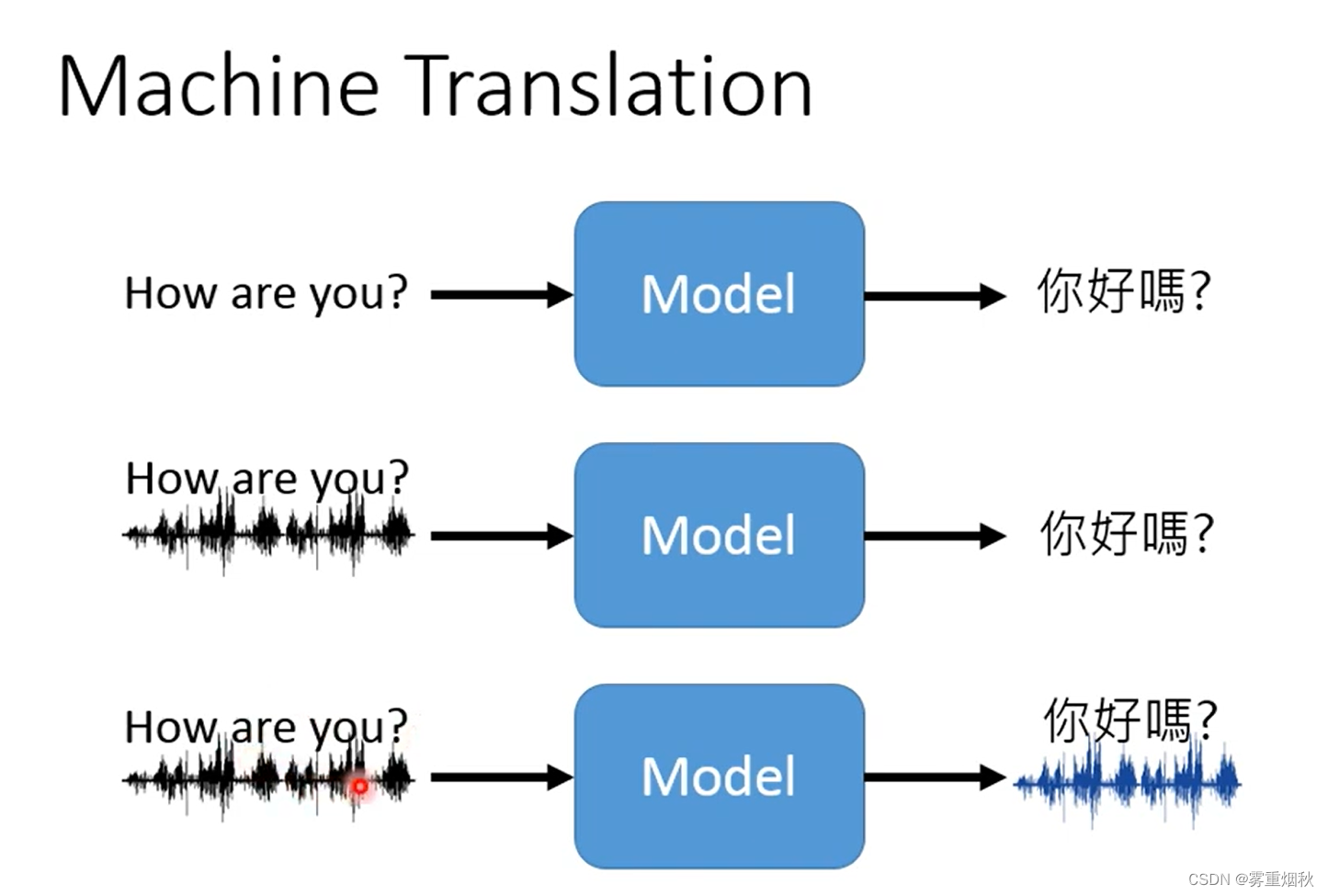
7 Machine Translation
Machine Translation(机器翻译)是一个典型的seq2seq模型,无监督的机器翻译是一个主要的研究方向,因为对于某些语言连文字都没有,很难收集到成对的翻译资料。
8 Grammar Error Correction
Grammar Error Correction也是一个seq2seq的模型,输入一个错误语法的句子,输出一个正确语法的句子,也可以简化任务为分类模型,给每个单词分类,分为"正确","替换","追加",这样就好像能改句子语法。

9 Sentiment classification
情感分类是典型的序列分类任务,评价一段话是好评还是差评,输入的是一段文本序列,输出一个类别。

10 Stance Detection
Stance Detection就是立场检测,检测两个句子的立场是否相同,立场可以分为四种,分别是"Support","Denying","Querying","Commenting",简称为(SDQC)。输入是多个文本序列,输出是一个类别,这个技术常被用于Veracity Prediction(真实性检测)。


11 Natural Language Inference(NLI)
NLI就是自然语言推理,给一个前提,再给一个假设,模型判断在这个前提下,输入的假设是否成立,也就是给模型输入一个前提和一个假设,然后做一个分类,判断是"矛盾","蕴含"还是"中立"。

12 Search Engine
搜索引擎之前是基于关键词的匹配,现在是用深度学习模型,从宏观上讲,就是输入搜索的句子和文章,输出句子和文章的相似度,然后按相似度排序。

13 Question Answering(QA)
QA在没有用深度学习之前,比较有名的是IBM的Watson,它们都是基于一些传统的机器学习模型,先对输入的问题进行前处理,把问题分到一个很小的类别当中,然后根据类别和问题从数据库中找备选答案,然后对答案进行相关性的评分,最后把这些备选答案合并和排序,得到最终答案,过程十分复杂。

有了深度学习以后,就是输入问题和知识库,输出一个答案。

14 Dialogue
对话可以分为聊天型和任务导向型。NLU是Nutural Language Understanding,NLU的子任务有意图识别(Intent Classification)、槽位填充(Slot Filling),NLG是Nutural Language Generation。



15 Knowledge Extraction
Knowledge Extraction就是去构建知识图谱(Knowledge Graph),比如有一大堆资料,先从这对资料中抽取一些entities,然后再根据资料给关联的entities之间画上relation,这部分说的很简化,实际上并不是如此简单。

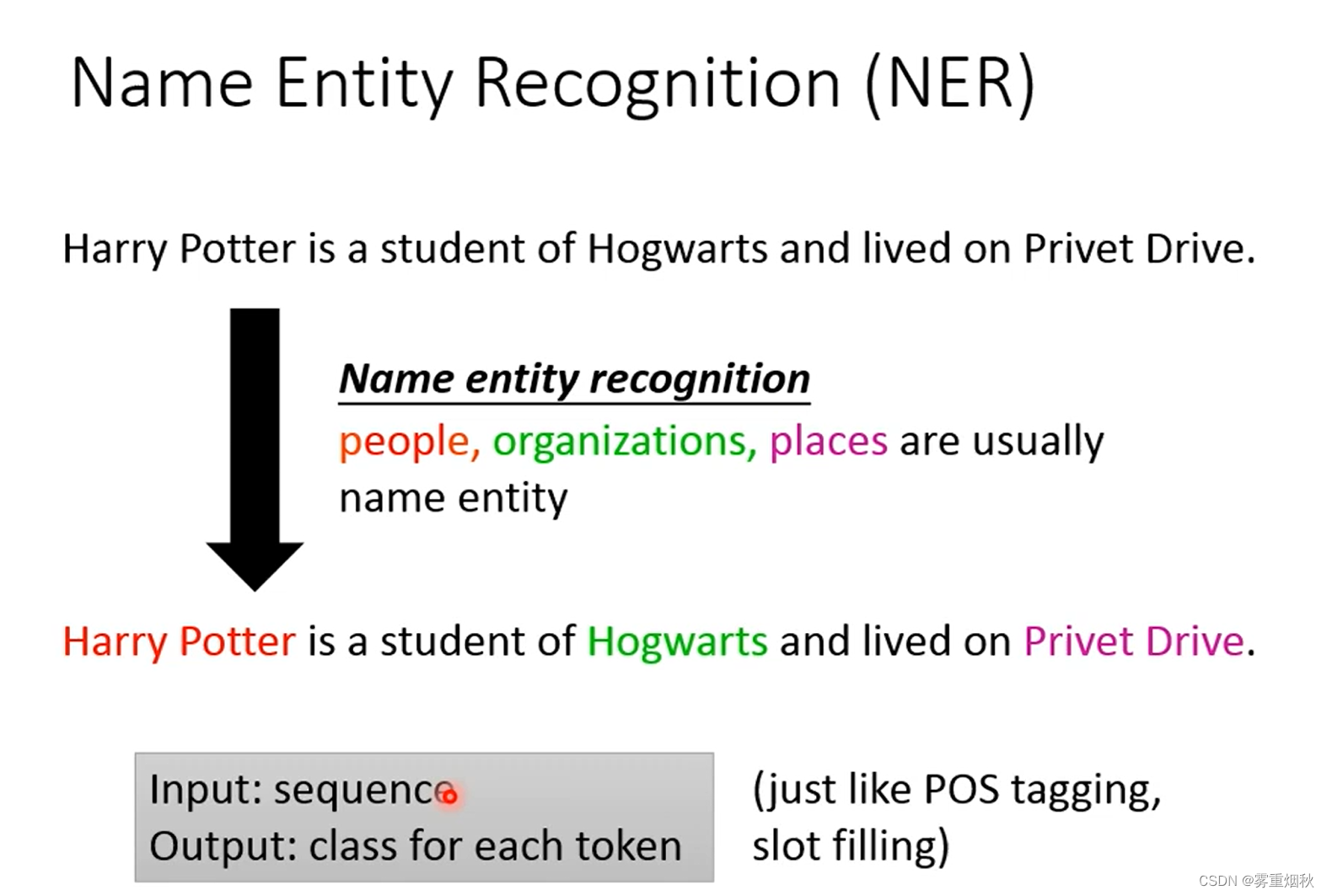
15.1 Name Entity Recognition(NER)
NER和POS Tagging和Slot Filling做的事差不多,给一段文本,然后给每个token打标签,比如Harry Potter就是People,Hogwarts就是organizations等等。这里的entity的种类是可以根据我们关心的内容去改变的。
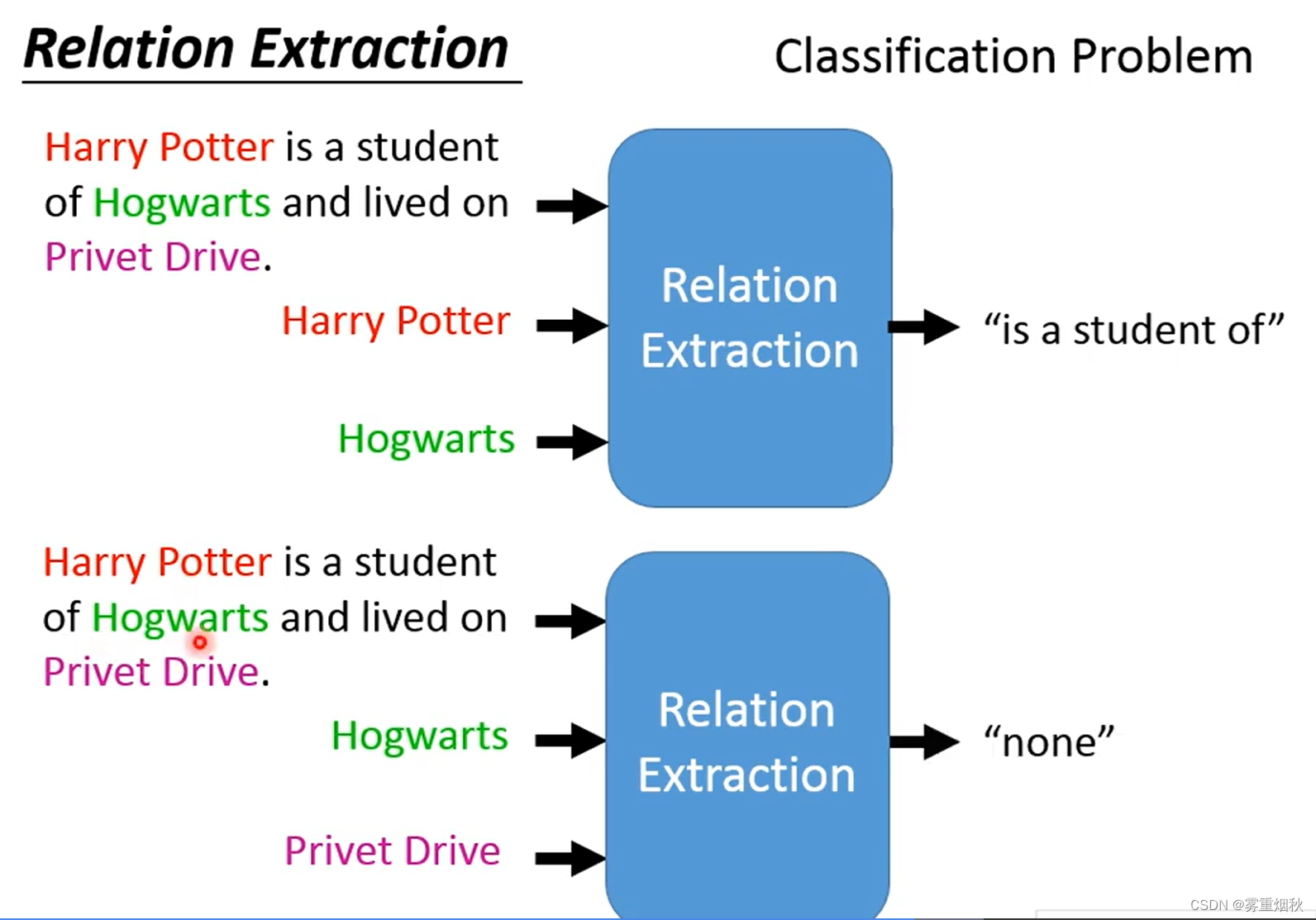
15.2 Relation Extraction
Relation Extraction是一个分类的问题,事先定义好有哪些relations,然后输入两个entities和与这两个entities相关的句子,得到最终的relation,类别中有一个"none"类,表示没有关系。
16 Benchmarks
机器到底理解人类的语言到什么样的程度,有一些基准,比如Glue,Super Glue和Decanlp。