Meta Llama 3 残差结构
flyfish
在Transformer架构中,残差结构(Residual Connections)是一个关键组件,它在模型的性能和训练稳定性上起到了重要作用。残差结构最早由He et al.在ResNet中提出,并被广泛应用于各种深度学习模型中。
残差结构的定义
残差结构通过将输入直接与通过一个或多个变换后的输出相加来形成。具体来说,如果输入为 x,经过某种变换后的输出为 F(x),那么残差结构的输出可以表示为:
y = F ( x ) + x y = F(x) + x y=F(x)+x
在Transformer中,残差结构通常与层归一化(Layer Normalization)一起使用,形成以下模式:
y = LayerNorm ( x + SubLayer ( x ) ) y = \text{LayerNorm}(x + \text{SubLayer}(x)) y=LayerNorm(x+SubLayer(x))
其中,SubLayer可以是多头自注意力机制(Multi-Head Self-Attention)或前馈神经网络(Feed-Forward Neural Network)。
残差结构
缓解梯度消失问题:
在深层神经网络中,梯度消失问题是一个常见的挑战,导致模型在训练过程中难以有效地传播梯度信号。残差结构通过引入快捷连接(skip connections),允许梯度直接通过这些连接进行传播,从而缓解了梯度消失问题。
加速模型训练:
残差结构使得模型能够更快地收敛,因为它简化了对标识映射(identity mapping)的学习。如果没有残差结构,模型需要学会每一层都能正确地变换输入;而有了残差结构后,模型只需学习相对较小的变换。
提高模型性能:
残差结构通过直接添加输入,可以帮助模型更好地捕捉输入数据中的特征,从而提高模型的性能。在Transformer中,这一特性尤为重要,因为它允许每一层都能保留和传递重要的信息。
增强模型的表达能力:
残差结构使得模型能够表示更复杂的函数。通过允许模型直接添加输入和输出,残差结构提高了模型的表达能力,使得它能够处理更复杂的任务。
在Transformer模型中,残差结构主要应用在以下两个子层中:
多头自注意力机制(Multi-Head Self-Attention):
残差连接与层归一化一起,围绕在多头自注意力机制的外部。假设输入为 x,多头自注意力的输出为 MHSA(x),那么残差连接后的输出为:
y = LayerNorm ( x + MHSA ( x ) ) y = \text{LayerNorm}(x + \text{MHSA}(x)) y=LayerNorm(x+MHSA(x))
前馈神经网络(Feed-Forward Neural Network, FFN):
同样地,残差连接与层归一化一起,围绕在前馈神经网络的外部。假设输入为 x,前馈神经网络的输出为 FFN(x),那么残差连接后的输出为:
y = LayerNorm ( x + FFN ( x ) ) y = \text{LayerNorm}(x + \text{FFN}(x)) y=LayerNorm(x+FFN(x))
代码展示
py
import torch
import torch.nn as nn
import torch.nn.functional as F
class TransformerLayer(nn.Module):
def __init__(self, d_model, num_heads, dim_feedforward, dropout=0.1):
super(TransformerLayer, self).__init__()
self.self_attn = nn.MultiheadAttention(d_model, num_heads, dropout=dropout)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, src_mask=None, src_key_padding_mask=None):
# Self-attention sub-layer with residual connection
attn_output, _ = self.self_attn(x, x, x, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)
x = x + self.dropout1(attn_output)
x = self.norm1(x)
# Feed-forward sub-layer with residual connection
ff_output = self.linear2(self.dropout(F.relu(self.linear1(x))))
x = x + self.dropout2(ff_output)
x = self.norm2(x)
return x
# 定义模型参数
d_model = 512
num_heads = 8
dim_feedforward = 2048
dropout = 0.1
# 创建一个包含单个 TransformerLayer 的模型
transformer_layer = TransformerLayer(d_model, num_heads, dim_feedforward, dropout)
# 创建一个示例输入张量 (seq_length, batch_size, d_model)
seq_length = 10
batch_size = 32
input_tensor = torch.randn(seq_length, batch_size, d_model)
# 执行前向传播
output = transformer_layer(input_tensor)
print("Output shape:", output.shape)参数定义:
d_model:模型的维度,即输入和输出的维度。
num_heads:多头自注意力机制中的头数。
dim_feedforward:前馈神经网络的隐藏层维度。
dropout:Dropout 概率,用于正则化。
输入张量:
input_tensor 的形状为 (seq_length, batch_size, d_model),其中 seq_length 是序列长度,batch_size 是批次大小,d_model 是每个输入的维度。
前向传播:
将 input_tensor 传递给 TransformerLayer 模块,获得输出 output。
输出形状:
输出的形状与输入的形状相同,为 (seq_length, batch_size, d_model)。
运行结果
Output shape: torch.Size(10, 32, 512)
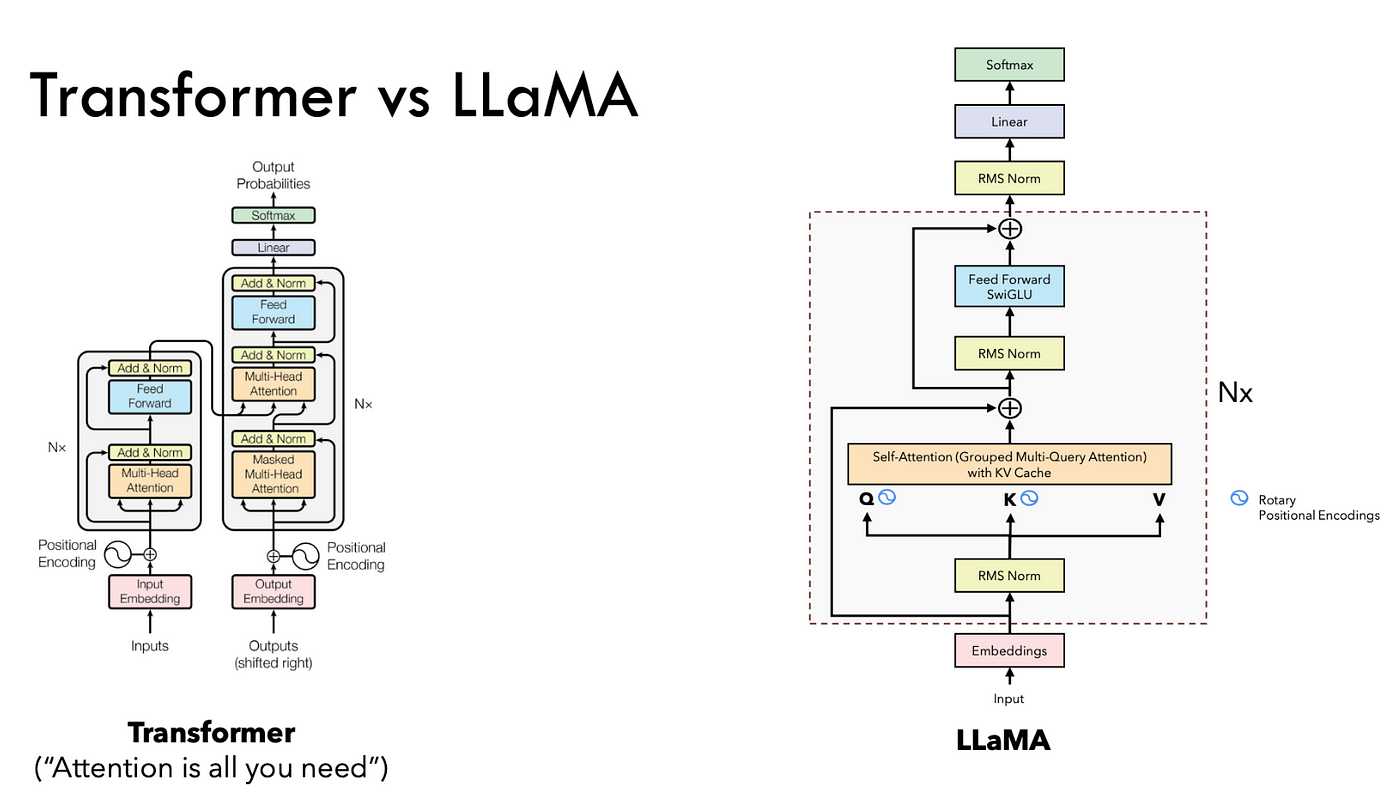
标准Transformer使用LayerNorm,并在子层输入和残差连接之后进行归一化。
Llama 3 使用RMSNorm代替LayerNorm,并且只在子层输入前进行归一化。
py
# 标准Transformer中的残差块
class TransformerBlock(nn.Module):
def __init__(self, dim, n_heads):
super().__init__()
self.attention = MultiHeadAttention(dim, n_heads)
self.feed_forward = FeedForward(dim)
self.norm1 = LayerNorm(dim)
self.norm2 = LayerNorm(dim)
def forward(self, x):
h = self.norm1(x)
h = x + self.attention(h)
h = self.norm2(h)
out = h + self.feed_forward(h)
return out
# Llama 3 中的残差块
class LlamaBlock(nn.Module):
def __init__(self, dim, n_heads, norm_eps):
super().__init__()
self.attention = Attention(dim, n_heads)
self.feed_forward = FeedForward(dim)
self.attention_norm = RMSNorm(dim, eps=norm_eps)
self.ffn_norm = RMSNorm(dim, eps=norm_eps)
def forward(self, x, start_pos, freqs_cis, mask):
h = x + self.attention(self.attention_norm(x), start_pos, freqs_cis, mask)
out = h + self.feed_forward(self.ffn_norm(h))
return out