一、大模型面临的挑战
1.1 Transformer模型的缺陷:
与RNN相比Transformer面临以下挑战:
- 并行计算能力不足。RNN需要按序处理序列数据中的每个时间步,这限制了它在训练过程中充分利用现代GPU的并行计算能力,从而影响训练效率。
- 长程依赖问题。尽管LSTM和GRU在处理长程依赖上比基本的RNN更为出色但在处理非常长的序列时,它们依然存在困难。
- 模型容量限制。LSTM和GRU的模型容量相对较小,这在大语言模型训练中限制了模型的规模,使获取更丰富的语义信息和构建更复杂的表示变得困难。
Transformer模型的结构如下图所示:
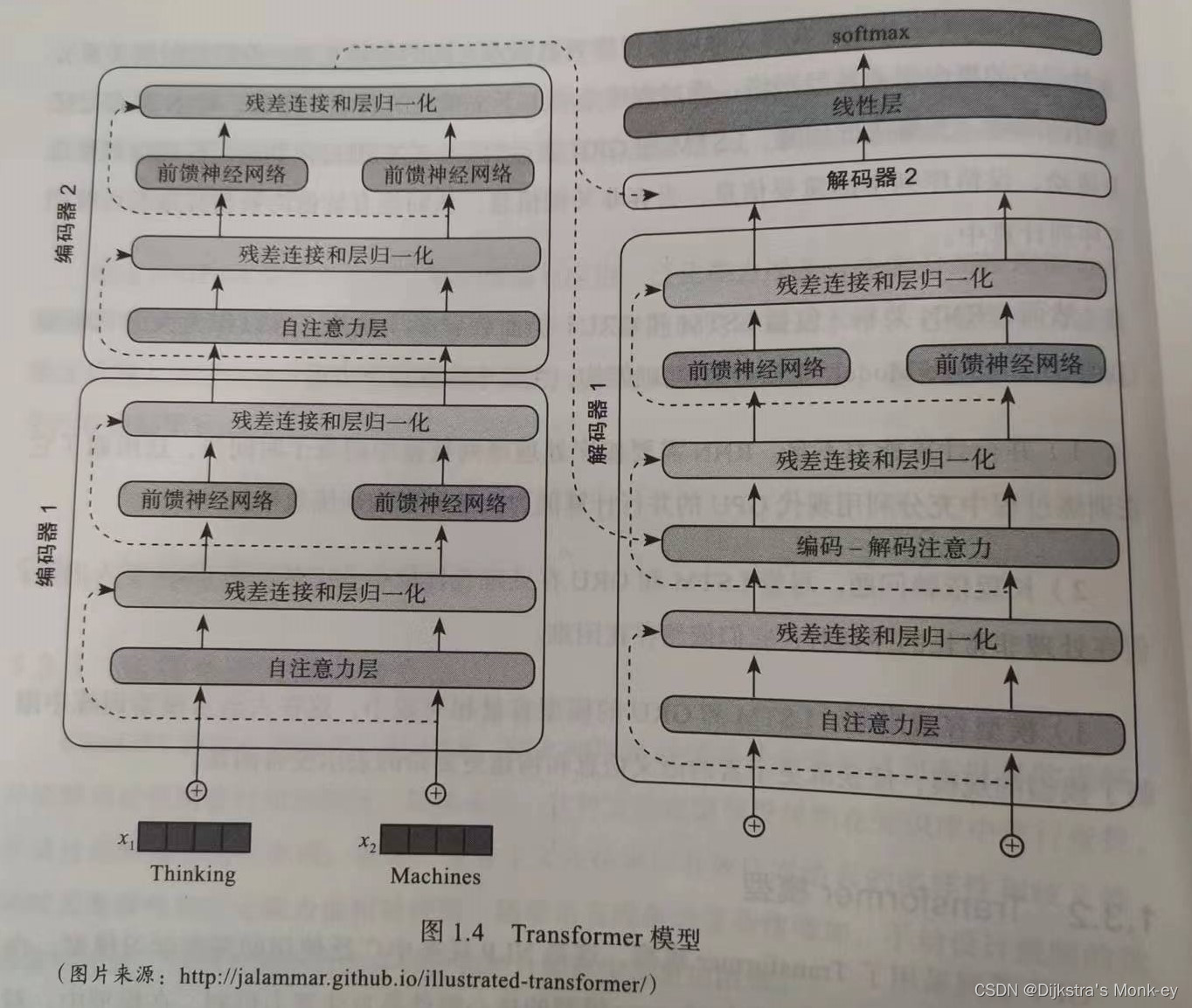
1.2 大模型发展的三个瓶颈
算力瓶颈
- 预训练阶段 :chatGPT 3.5参数量
1750亿以上,显存占用350G~500G,预训练需要1000个以上的A100 GPU算力。单次训练成本500万美元 - 推理与部署阶段 :
1750亿,假设有1300万个日活跃用户,每个GPU每小时成本1美元,日均计算硬件成本69万美元,每次查询成本0.69美分
数据瓶颈
- LLaMA使用数据集
4.6TB - GPT-3使用数据集
45TB(文本) - 全球最大中文语料库WuDaoCorpora:
3TB,公开200G
工程瓶颈
专业研究人员和工程师的技能标准要求高、培养和雇佣成本高
二、大模型的评估
GPT-4的智能水平可从以下几个关键方面进行评估:
- 任务表现
- 知识理解与应用
- 泛化能力
- 自主学习和推理能力
三、大模型的演变和架构
3.1 GPT-1
GPT-1的模型架构如下图所示:

3.2 GPT-2
GPT-2模型的自回归过程:

3.3 GPT-3
GPT-3的模型架构示意图:

3.4 GPT系列
总结GPT的技术栈和模型结构。
大语言模型的技术栈如下图所示:

GPT系列的模型架构示意图:

3.5 应用流程

四、大模型的未来发展
在探索GPT-5及后续版本的可能性与发展前景时,有几个关键因素必须予以重点考数据量、数据质量以及数据来源。这些可能决定了GPT-5及后续版本是否能够接近虑:或超越人类智能的关键要素。
4.1 数据量
有媒体开始预测GPT-5的发布日期,并预测GPT-5在多模态处理能力方面将有重大突破。据现有资料表明,GPT-5可能会在约25000个GPU的规模上进行训练。据TechRadar的报道,ChachiBT已经在10000个性能超越A100 GPU的NVIDIA GPU上进行了训练。对于GPT-5的发布时间,GeordieRybass的预测可以作为参考,他预测GPT-5或类似模型可能在2024年春末或初夏发布。
一项对 DeepMind研究的总结指出,模型的参数规模与训练数据量之间存在一种优化平衡。例如,GPT-3和Palm 等模型的参数数量远超出其实际需求,它们实际上更需要大量高质量的数据。
因此,GPT-4需要1万亿参数的说法似乎并不准确 。事实上,GPT-5的参数可能与GPT-4相同,甚至可能更少。根据2022年7月的一篇LessWrong博客文章,当前的语言建模性能主要受到数据量的限制,而不是模型规模。只要获得足够多的数据,就无须运行拥有5000亿参数,甚至1万亿或更大规模参数的模型。
4.2 数据质量
在GPT模型的提升过程中,数据质量至关重要,然而,获取高质量的数据仍然是一个挑战。目前,GPT-3和其他一些模型在大约3000亿个token上进行了训练。考虑到DeepMind的 Chinchila模型在大约1.4万亿个token上进行了训练,GPT-5在数据量方面可能会有显著的提升。高质量数据的已知来源包括科学论文、书籍、网络爬取的内容新闻、代码以及维基百科。目前已知的高质量数据大约在4.6万亿到17万亿个词之间。这表明距离耗尽高质量数据仅有一个数量级的距离,这种情况可能出现在2023-2027年,对人工智能的近期发展将产生深远影响。
4.3 数据来源
此外,数据来源的不确定性仍是一个问题。例如,Google和OpenAI并未透露他们的数据来源,可能是为了避免所有权和补偿的争议。同时,随着AI图像生成等领域的法律问题日益突出,确定数据来源将成为重要议题。尽管如此,GPT-5仍然会借鉴过去的经验,尽可能获取更多的高质量数据。自GPT-4交给微软以来,在没有进一步提高数据利用或提取效率的情况下,高质量数据的存量每年增长约10%。
4.4 技术突破
除数据问题以外,GPT-5在各方面都有可能取得技术突破。一方面,研究者或许能发现从质量较低的数据源中提取高质量数据的方法。另一方面,引入自动化链式思维引导(ChainofThoughtPrompting)策略,有望显著提升模型的表现。尽管性能和成本因素可能限制模型训练,但多轮利用同一数据训练模型是行之有效的策略。人工生成并筛选数据集也是一个提升模型在复杂数学问题等方面表现的有效方法。
如果GPT-5能有效利用9万亿高质量token数据,其性能预期将实现数量级的提升这可能对就业市场产生深远影响。在阅读理解、逻辑和批判性思考、高中物理以及数学等领域,GPT-5有望超过人类评估者。并且,随着文本到语音、图像到文本、文本到图像以及文本到视频虚拟形象等技术的进步,AI教师的出现可能近在咫尺。然而,GPT-5的发布时间尚不确定,其中一个原因是它的发布可能取决于OpenAl内部的安全研究进展。OpenAI的首席执行官Sam Altman表示,只有在完成对齐工作、进行安全考量并与外部审计机构合作之后,相关模型才会发布。
参考文献
ChatGPT原理与架构:大模型的预训练、迁移和中间件编程 程戈 著 机械工业出版社 2023年12月