图神经网络实战(12)------图同构网络
0. 前言
Weisfeiler-Leman (WL) 测试提供了一个理解图神经网络 (Graph Neural Networks, GNN)表达能力的框架,利用该框架我们比较了不同的 GNN 层,在本节中,我们将利用 WL 测试结果尝试设计比图卷积网络 (Graph Convolutional Network, GCN)、图注意力网络 (Graph Attention Networks,GAT)和 GraphSAGE 更强大的 GNN 架构------图同构网络 (Graph Isomorphism Network, GIN)。然后,使用 PyTorch Geometric 实现 GIN 架构,并执行图分类任务。我们将在 PROTEINS 数据集上实现 GIN 架构,将比较不同的图分类模型并分析结果。
为了验证这一想法,在下一节中,我们将根据这一思想构建。
1. 图同构网络原理
在Weisfeiler-Leman (WL) 测试一节中,我们看到之前所介绍的图神经网络 (Graph Neural Networks, GNN)(包括图卷积网络 (Graph Convolutional Network, GCN)、图注意力网络 (Graph Attention Networks,GAT)和 GraphSAGE 等)的表达能力不如 WL 测试,这暴露出一个问题,因为区分更多图结构的能力与最终嵌入的质量有关。在本节中,我们将把理论框架转化为一种新的 GNN 架构------图同构网络 (Graph Isomorphism Network, GIN)。
GIN 于 2018 年由 Xu 等人提出,旨在具有与 WL 测试相同的表达能力。作者将对聚合的观察归纳为两个函数:
- 聚合 (
Aggregate): 函数 f f f 选择GNN考虑的邻居节点 - 组合 (
Combine): 函数 ϕ ϕ ϕ 将所选节点的嵌入结合起来,生成目标节点的新嵌入
节点嵌入可以表达为以下形式:
h i ′ = ϕ ( h i , f ( h j : j ∈ N i ) ) h'_i=ϕ(h_i,f({h_j:j\in \mathcal N_i})) hi′=ϕ(hi,f(hj:j∈Ni))
在 GCN 中,函数 f f f 会聚合节点 i i i 的每个邻居,而 ϕ ϕ ϕ 则使用均值聚合算子。在 GraphSAGE 中,邻居采样就是函数 f f f, ϕ ϕ ϕ 具有三个不同选项,包括均值聚合算子、长短期记忆 (long short-term memory, LSTM) 聚合算子和池化聚合算子。
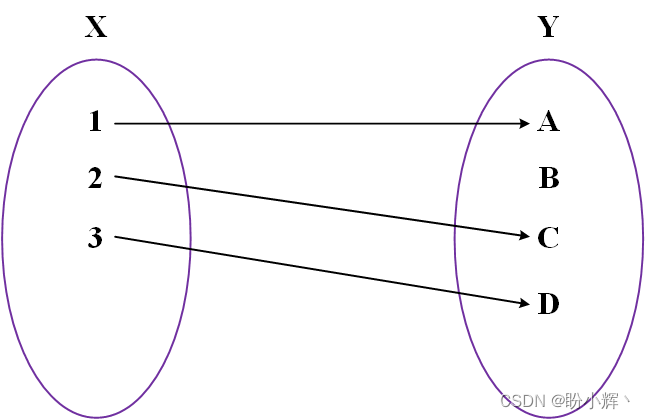
而在图同构网络 (Graph Isomorphism Network, GIN) 中,这些函数是必须是单射的。如下图所示,单射函数 (injective function) 将不同的输入映射到不同的输出,这正是我们想要区分图结构的原因。如果函数不是单射的,那么不同的输入将得到相同的输出。在这种情况下,嵌入就变得不那么有价值了,因为它们包含的信息会更少。
GIN 在设计这两个函数时,只是对这两个函数进行了近似。在 GAT 层中,我们学习了自注意力权重。在 GIN 中,我们可以利用通用近似定理,用一个多层感知机 (Multilayer Perceptron, MLP) 学习这两个函数:
h i ′ = M L P ( ( 1 + ɛ ) ⋅ h i + ∑ j ∈ N i h j ) h'i=MLP((1+ɛ)\cdot h_i+\sum{j\in \mathcal N_i}h_j) hi′=MLP((1+ɛ)⋅hi+j∈Ni∑hj)
其中, ɛ ɛ ɛ 是一个可学习的参数或固定标量,表示目标节点的嵌入与其邻居的嵌入相比的重要性。同时,MLP 必须具有多个层来区分特定的图结构。
现在,我们已经介绍了一个与 WL 测试具有相同表达能力的 GNN,但在此基础上,我们还可以进一步改进,将 WL 测试推广为一系列更高级别的测试,称为 k-WL 测试。与考虑单个节点不同,k-WL 测试考虑的是 k 元组节点。这意味着它们是非局部的,因为它们可以查看相距更远的节点,这也是 (k + 1) -WL 测试比 k-WL 测试(其中 k ≥ 2 )能区分更多图结构的原因。
目前已经提出了几种基于 k-WL 测试的架构,如 Morris 等人提出的 k-GNN。虽然这些架构有助于我们更好地理解 GNN 的工作原理,但与 GNN 或 GAT 等表达能力较弱的模型相比,它们在实际应用中往往表现不佳,但它们也有各自合适的应用场景,接下来,我们将 GIN 应用于图分类以发挥其性能。
2. 构建 GIN 模型执行图分类
我们可以直接实现用于节点分类的图同构网络 (Graph Isomorphism Network, GIN)模型,但 GIN 架构对于执行图分类任务更加有效。在本节中,我们将了解如何使用全局池化技术将节点嵌入转化为图嵌入。然后,将这些技术应用于 PROTEINS 数据集,并对比 GIN 和图卷积网络 (Graph Convolutional Network, GCN)在图分类任务中的性能差异。
2.1 图分类任务
图分类是基于图神经网络 (Graph Neural Networks, GNN)生成的节点嵌入进行的,但与节点层面的任务不同,图分类需要关注图数据的全局信息,需要对全局的信息进行融合学习,在图中通常采用全局池化( global pooling,也称图读出机制,graph-level readout function)来提取全局信息。三种简单的实现方法如下:
- 全局均值池化 (
Mean global pooling): 通过对图中每个节点的嵌入取平均值,得到图嵌入 h G h_G hG:
h G = 1 N ∑ i = 0 N h i h_G=\frac 1N\sum_{i=0}^Nh_i hG=N1i=0∑Nhi - 全局最大池化 (
Max global pooling): 通过选择每个节点维度的最高值,得到图嵌入 h G h_G hG:
h G = m a x i = 0 N ( h i ) h_G=max_{i=0}^N(h_i) hG=maxi=0N(hi) - 全局求和池化 (
Sum global pooling):通过对图中每个节点的嵌入求和,得到图嵌入 h G h_G hG:
h G = ∑ i = 0 N h i h_G=\sum_{i=0}^Nh_i hG=i=0∑Nhi
根据Weisfeiler-Leman (WL) 测试可知,求和全局池化严格来说比其他两种池化技术更具表达能力。同时,要考虑所有结构信息,就必须考虑 GNN 每一层产生的嵌入,将 GNN 的 k k k 个层中每层产生的节点嵌入求和后串联起来:
h G = ∑ i = 0 N h i 0 ∣ ∣ ⋯ ∣ ∣ ∑ i = 0 N h i k h_G=\sum_{i=0}^Nh_i^0||\cdots ||\sum_{i=0}^Nh_i^k hG=i=0∑Nhi0∣∣⋯∣∣i=0∑Nhik
这种方法通过串联将求和运算符的表达能力与每层中存储的信息优雅的结合在一起。
2.2 PROTEINS 数据集分析
接下来,在 PROTEINS 数据集上使用图读出机制实现 GIN 模型。PROTEINS 数据集包含 1,113 个表示蛋白质的图,其中每个节点都是一个氨基酸。当两个节点之间的距离小于 0.6 纳米时,它们之间会有一条边相连。该数据集的目标是将每个蛋白质分类为酶或非酶,即二分类问题,酶可作为催化剂加速细胞内的化学反应,例如,脂肪酶可以帮助消化食物等,蛋白质的三维结构示例如下:
接下来,使用 PyTorch Geometric (PyG) 在 PROTEINS 数据集上构建 GIN 模型。
(1) 首先,使用 PyTorch Geometric 的 TUDataset 类导入 PROTEINS 数据集并打印相关信息:
python
from torch_geometric.datasets import TUDataset
dataset = TUDataset(root='.', name='PROTEINS').shuffle()
# Print information about the dataset
print(f'Dataset: {dataset}')
print('-----------------------')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of nodes: {dataset[0].x.shape[0]}')
print(f'Number of features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')
'''
Dataset: PROTEINS(1113)
-----------------------
Number of graphs: 1113
Number of nodes: 28
Number of features: 3
Number of classes: 2
'''(2) 以 8:1:1 的比例将数据集拆分为训练集、验证集和测试集:
python
from torch_geometric.loader import DataLoader
# Create training, validation, and test sets
train_dataset = dataset[:int(len(dataset)*0.8)]
val_dataset = dataset[int(len(dataset)*0.8):int(len(dataset)*0.9)]
test_dataset = dataset[int(len(dataset)*0.9):]
print(f'Training set = {len(train_dataset)} graphs')
print(f'Validation set = {len(val_dataset)} graphs')
print(f'Test set = {len(test_dataset)} graphs')训练集、验证集和测试集中图的数量输出如下:
shell
Training set = 890 graphs
Validation set = 111 graphs
Test set = 112 graphs(3) 使用批大小为 64 的 DataLoader 对象将这些数据集合转换为批数据,即每批数据最多包含 64 个图:
python
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=True)(4) 打印每批数据的相关信息:
python
print('\nTrain loader:')
for i, batch in enumerate(train_loader):
print(f' - Batch {i}: {batch}')
print('\nValidation loader:')
for i, batch in enumerate(val_loader):
print(f' - Batch {i}: {batch}')
print('\nTest loader:')
for i, batch in enumerate(test_loader):
print(f' - Batch {i}: {batch}')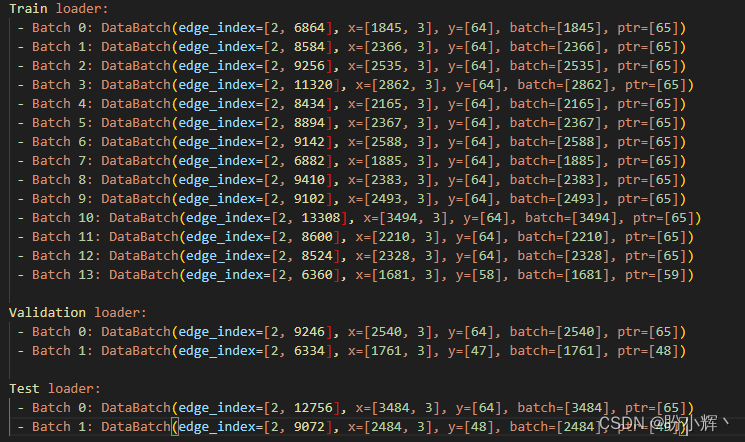
2.3 构建 GIN 实现图分类
构建训练数据集后,开始实施 GIN 模型。首先需要考虑 GIN 层的架构,使用一个至少有两层的多层感知机 (Multilayer Perceptron, MLP) ,引入批归一化来标准化每个隐藏层的输入,用于稳定并加快训练速度。总体而言, GIN 架构如下所示:

(1) 使用 PyTorch Geometric (PyG) 实现以上架构,作为对比,我们同时实现了 GCN 模型:
python
import torch
import torch.nn.functional as F
from torch.nn import Linear, Sequential, BatchNorm1d, ReLU, Dropout
from torch_geometric.nn import GCNConv, GINConv
from torch_geometric.nn import global_mean_pool, global_add_pool
class GCN(torch.nn.Module):
"""GCN"""
def __init__(self, dim_h):
super(GCN, self).__init__()
self.conv1 = GCNConv(dataset.num_node_features, dim_h)
self.conv2 = GCNConv(dim_h, dim_h)
self.conv3 = GCNConv(dim_h, dim_h)
self.lin = Linear(dim_h, dataset.num_classes)
def forward(self, x, edge_index, batch):
# Node embeddings
h = self.conv1(x, edge_index)
h = h.relu()
h = self.conv2(h, edge_index)
h = h.relu()
h = self.conv3(h, edge_index)
# Graph-level readout
hG = global_mean_pool(h, batch)
# Classifier
h = F.dropout(hG, p=0.5, training=self.training)
h = self.lin(h)
return F.log_softmax(h, dim=1)
class GIN(torch.nn.Module):
"""GIN"""
def __init__(self, dim_h):
super(GIN, self).__init__()
self.conv1 = GINConv(
Sequential(Linear(dataset.num_node_features, dim_h),
BatchNorm1d(dim_h), ReLU(),
Linear(dim_h, dim_h), ReLU()))
self.conv2 = GINConv(
Sequential(Linear(dim_h, dim_h), BatchNorm1d(dim_h), ReLU(),
Linear(dim_h, dim_h), ReLU()))
self.conv3 = GINConv(
Sequential(Linear(dim_h, dim_h), BatchNorm1d(dim_h), ReLU(),
Linear(dim_h, dim_h), ReLU()))PyTorch Geometric 还内置了 GINE 层,GINE是 GIN 层的一种改进。与 GIN 相比,GINE 的主要改进在于能够在聚合过程中考虑边特征。由于 PROTEINS 数据集没有边特征,因此本节采用经典的 GIN 模型。
(2) 要进行图分类,还需要对每一层中图上每个节点嵌入进行求和。换句话说,我们需要为每一层存储一个大小为 dim_h 的向量,本节中 dim_h 为 3。在最终的线性层之前,添加一个大小为 3 * dim_h 的线性层,用于二分类 (data.num_classes = 2):
python
self.lin1 = Linear(dim_h*3, dim_h*3)
self.lin2 = Linear(dim_h*3, dataset.num_classes)(3) 接下来,实现连接初始化层的逻辑。每一层都会产生不同的嵌入张量------h1、h2 和 h3。使用 global_add_pool() 函数对它们进行求和,然后使用 torch.cat() 将它们串联起来。这样,就得到了分类器的输入,类似一个带有 Dropout 层的普通神经网络:
python
def forward(self, x, edge_index, batch):
# Node embeddings
h1 = self.conv1(x, edge_index)
h2 = self.conv2(h1, edge_index)
h3 = self.conv3(h2, edge_index)
# Graph-level readout
h1 = global_add_pool(h1, batch)
h2 = global_add_pool(h2, batch)
h3 = global_add_pool(h3, batch)
# Concatenate graph embeddings
h = torch.cat((h1, h2, h3), dim=1)
# Classifier
h = self.lin1(h)
h = h.relu()
h = F.dropout(h, p=0.5, training=self.training)
h = self.lin2(h)
return F.log_softmax(h, dim=1)(4) 使用批数据实现一个常规的训练循环,共训练 100 个 epoch:
python
def train(model, loader):
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
epochs = 100
model.train()
for epoch in range(epochs+1):
total_loss = 0
acc = 0
val_loss = 0
val_acc = 0
# Train on batches
for data in loader:
optimizer.zero_grad()
out = model(data.x, data.edge_index, data.batch)
loss = criterion(out, data.y)
total_loss += loss / len(loader)
acc += accuracy(out.argmax(dim=1), data.y) / len(loader)
loss.backward()
optimizer.step()
# Validation
val_loss, val_acc = test(model, val_loader)(5) 每 20 个 epoch 打印一次训练和验证准确率,并返回训练后的模型:
python
# Print metrics every 20 epochs
if(epoch % 20 == 0):
print(f'Epoch {epoch:>3} | Train Loss: {total_loss:.2f} | Train Acc: {acc*100:>5.2f}% | Val Loss: {val_loss:.2f} | Val Acc: {val_acc*100:.2f}%')
return model(6) 在 test() 方法中也必须使用批处理,因为验证和测试加载器同样包含多个批数据:
python
@torch.no_grad()
def test(model, loader):
criterion = torch.nn.CrossEntropyLoss()
model.eval()
loss = 0
acc = 0
for data in loader:
out = model(data.x, data.edge_index, data.batch)
loss += criterion(out, data.y) / len(loader)
acc += accuracy(out.argmax(dim=1), data.y) / len(loader)
return loss, acc(7) 定义用于计算准确率的函数:
python
def accuracy(pred_y, y):
"""Calculate accuracy."""
return ((pred_y == y).sum() / len(y)).item()(8) 实例化并训练 GCN 和 GIN 模型:
python
print('GCN training')
gcn = GCN(dim_h=32)
gcn = train(gcn, train_loader)
print('GIN training')
gin = GIN(dim_h=32)
gin = train(gin, train_loader)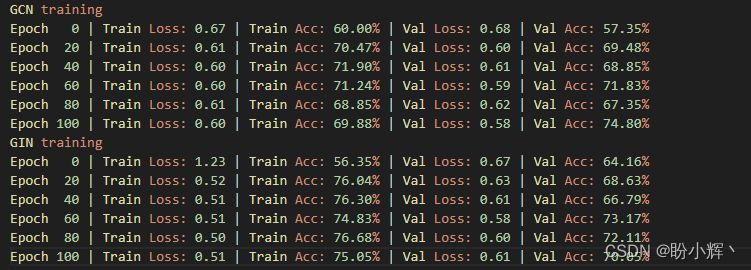
(9) 使用测试加载器测试训练后的模型:
python
test_loss, test_acc = test(gcn, test_loader)
print(f'GCN test Loss: {test_loss:.2f} | GCN test Acc: {test_acc*100:.2f}%')
test_loss, test_acc = test(gin, test_loader)
print(f'Gin test Loss: {test_loss:.2f} | Gin test Acc: {test_acc*100:.2f}%')
# GCN test Loss: 0.56 | GCN test Acc: 65.70%
# GIN test Loss: 0.46 | GIN test Acc: 78.12%2.4 GCN 与 GIN 性能差异分析
根据上一小节的结果可以看出,用简单的全局均值池( PyTorch Geometric 中使用 global_mean_pool() 实现)实现 GCN 执行图分类,在完全相同的设定下,进行 100 次实验的平均准确率为 72.72%(±0.73%)。这远低于 GIN 模型的平均准确率 77.57% (±1.77%)。
据此,可以得出结论,GIN 架构比 GCN 更适合图分类任务。根据 WL 测试理论框架,这是因为 GCN不如 GIN 的表达能力强。换句话说,GIN 比 GCN 能区分更多的图结构,这也是它更准确的原因。可以通过可视化两种模型错误分类的图来验证这一假设。
(1) 导入 matplotlib 和 networkx 库,用于绘制蛋白质结构:
python
import numpy as np
import matplotlib.pyplot as plt
import networkx as nx
from torch_geometric.utils import to_networkx
fig, ax = plt.subplots(4, 4)
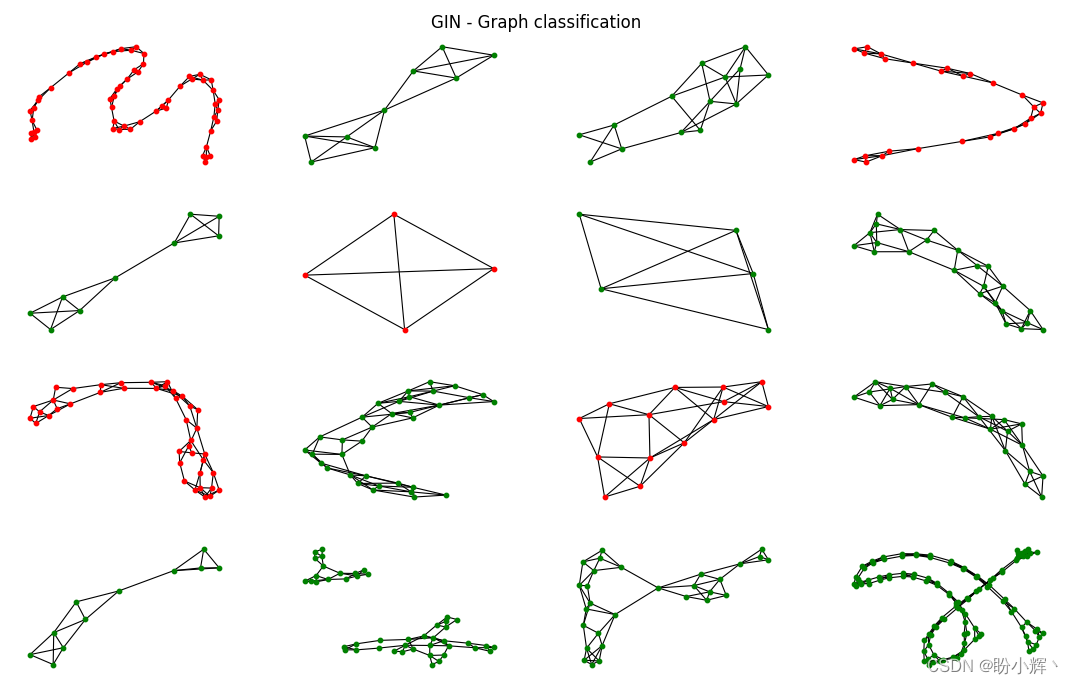
fig.suptitle('GIN - Graph classification')(2) 对于每个蛋白质,使用训练后的 GIN 获取最终分类结果。如果预测是正确的,将其绘制为绿色(否则绘制为红色):
python
for i, data in enumerate(dataset[-16:]):
# Calculate color (green if correct, red otherwise)
out = gin(data.x, data.edge_index, data.batch)
color = "green" if out.argmax(dim=1) == data.y else "red"(3) 为了方便起见,将蛋白质转换成 networkx 图,然后使用 nx.draw_networkx() 函数进行绘制:
python
ix = np.unravel_index(i, ax.shape)
ax[ix].axis('off')
G = to_networkx(dataset[i], to_undirected=True)
nx.draw_networkx(G,
pos=nx.spring_layout(G),
with_labels=False,
node_size=10,
node_color=color,
width=0.8,
ax=ax[ix])
plt.show()GIN 模型分类结果的准确性如下所示:
(4) 对 GCN 模型重复以上过程:
python
fig, ax = plt.subplots(4, 4)
fig.suptitle('GCN - Graph classification')
for i, data in enumerate(dataset[-16:]):
# Calculate color (green if correct, red otherwise)
out = gcn(data.x, data.edge_index, data.batch)
color = "green" if out.argmax(dim=1) == data.y else "red"
# Plot graph
ix = np.unravel_index(i, ax.shape)
ax[ix].axis('off')
G = to_networkx(dataset[i], to_undirected=True)
nx.draw_networkx(G,
pos=nx.spring_layout(G),
with_labels=False,
node_size=10,
node_color=color,
width=0.8,
ax=ax[ix])
plt.show()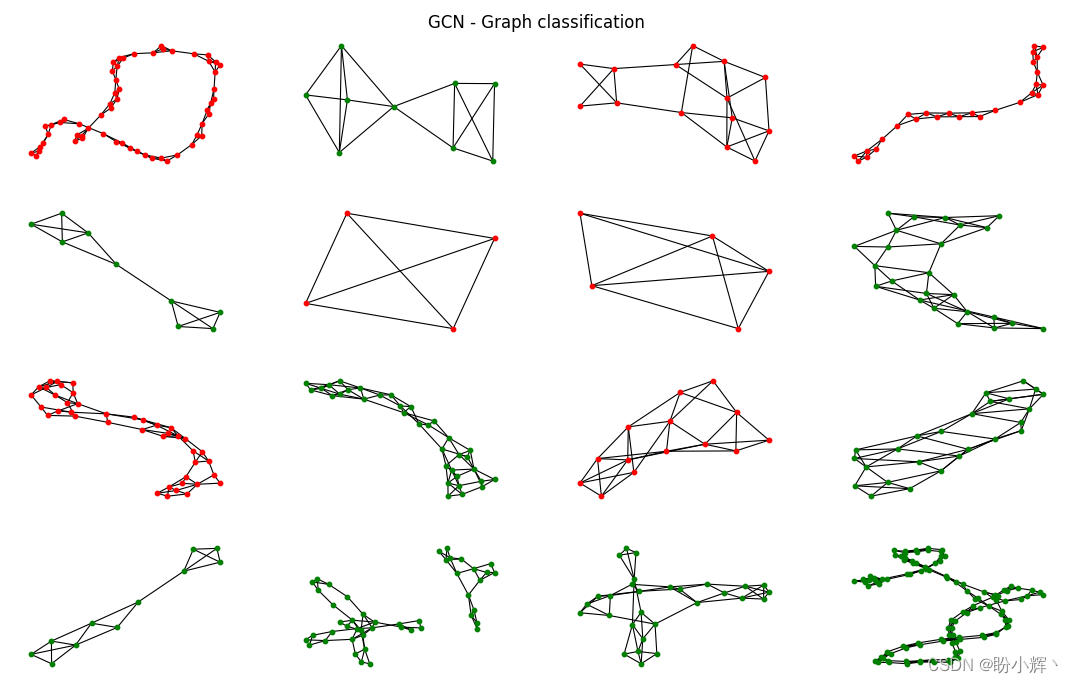
可以看到,GCN 模型将更多的图错误分类。要了解哪些图结构没有被充分捕捉,需要对 GIN 正确分类的每个蛋白质进行大量分析。但可以看到 GIN 也出现了不同的错误,这证明了这些模型可以互补。
3. 提升模型性能
在机器学习中,将出现不同错误的模型集成为一个更优秀的模型是一种常见技术。可以采用不同的方法,例如在最终分类的基础上训练第三个模型。为了简单起见,本节中我们将实现一种简单的模型平均技术:
(1) 首先,我们将模型设置为评估模式 (eval()),并定义变量用于存储准确率:
python
gcn.eval()
gin.eval()
acc_gcn = 0
acc_gin = 0
acc_ens = 0(2) 得到每个模型的最终分类结果,然后将它们组合起来,作为集成模型的预测结果:
python
for data in test_loader:
# Get classifications
out_gcn = gcn(data.x, data.edge_index, data.batch)
out_gin = gin(data.x, data.edge_index, data.batch)
out_ens = (out_gcn + out_gin)/2(3) 计算三个模型预测的准确率:
python
# Calculate accuracy scores
acc_gcn += accuracy(out_gcn.argmax(dim=1), data.y) / len(test_loader)
acc_gin += accuracy(out_gin.argmax(dim=1), data.y) / len(test_loader)
acc_ens += accuracy(out_ens.argmax(dim=1), data.y) / len(test_loader)(4) 最后,打印模型的准确率:
python
# Print results
print(f'GCN accuracy: {acc_gcn*100:.2f}%')
print(f'GIN accuracy: {acc_gin*100:.2f}%')
print(f'GCN+GIN accuracy: {acc_ens*100:.2f}%')
'''
GCN accuracy: 73.70%
GIN accuracy: 78.91%
GCN+GIN accuracy: 79.43%
'''在本节示例中,集成模型的预测结果优于其它两个模型,准确率为 79.43% (GCN 为 73.70%,GIN 为 78.91%)。模型集成技术的准确率提升相当显著,为构建高性能模型提供了更多可能性。然而,这并不一定是普遍情况,即使在本例中,集成模型的表现也并不总是优于 GIN。可以用其他架构(如 Node2Vec )的嵌入来丰富集成模型,并观察是否能提高最终的准确率。
小结
图同构网络 (Graph Isomorphism Network, GIN) 架构受 WL 测试启发而设计的,其表达能力与 WL 测试相近,因此在严格意义上比 GCN、GAT 或 GraphSAGE 更具表达能力。在本节中,将这一架构用于图分类任务,介绍了将节点嵌入融合到图嵌入中的不同方法,GIN 通过连接求和运算符和每个 GIN 层产生图嵌入,其性能明显优于通过 GCN 层获得的经典全局均值池化。最后,我们将两个模型的预测结果进行简单的集成,从而进一步提高了准确率。
系列链接
图神经网络实战(1)------图神经网络(Graph Neural Networks, GNN)基础
图神经网络实战(2)------图论基础
图神经网络实战(3)------基于DeepWalk创建节点表示
图神经网络实战(4)------基于Node2Vec改进嵌入质量
图神经网络实战(5)------常用图数据集
图神经网络实战(6)------使用PyTorch构建图神经网络
图神经网络实战(7)------图卷积网络(Graph Convolutional Network, GCN)详解与实现
图神经网络实战(8)------图注意力网络(Graph Attention Networks, GAT)
图神经网络实战(9)------GraphSAGE详解与实现
图神经网络实战(10)------归纳学习
图神经网络实战(11)------Weisfeiler-Leman测试