paper: https://arxiv.org/abs/2506.15564
code: https://github.com/showlab/Show-o
由新加坡国立大学和字节联合
文章目录
- 核心问题
- 核心思想
- 方法介绍
-
- [1. 整体架构 (Overall Framework)](#1. 整体架构 (Overall Framework))
- [2. 两阶段训练方案 (Two-stage Training Recipe)](#2. 两阶段训练方案 (Two-stage Training Recipe))
- 实验介绍
- 核心贡献
核心问题
尽管大型语言模型(LLMs)和大型多模态模型(LMMs)在各自领域取得了进展,但如何设计原生(natively)统一多模态理解和生成能力,并能可扩展地支持文本、图像和视频这三种模态,是一个关键挑战。具体挑战包括:
- 模态统一: 如何构建统一的视觉表示,使其能够同时支持多模态理解和视觉生成任务,并且能有效处理图像和视频两种视觉模态。
- 训练效率与知识保留: 如何设计高效的训练方法,使模型在获得强大的视觉生成能力的同时,能够保留其原有的语言知识 ,并且不需要依赖大规模的文本语料库。
- 原生集成: 如何在一个单一模型内,原生集成自回归建模(用于文本)和生成建模(用于图像/视频)这两种不同的范式。
核心思想
Show-o2的核心思想是构建一个原生统一的多模态模型 ,通过集成两种主要的建模范式和一个可扩展的统一视觉表示来实现文本、图像和视频的全面处理:
- 原生统一建模: 模型在基于语言模型(LLM)的架构上,原生 地将自回归建模(Autoregressive Modeling)应用于Language Head 进行文本预测,并将Flow Matching 应用于 Flow Head 进行图像/视频生成。
- 统一视觉表示: 基于3D因果变分自编码器(3D Causal VAE)空间,通过一个空间(-时间)融合的双路径机制构建统一的视觉表示,使其能够同时捕获丰富的语义信息和低级特征,并可扩展到图像和视频模态。
方法介绍
Show-o2的主要方法包括模型架构设计和两阶段训练策略:
1. 整体架构 (Overall Framework)
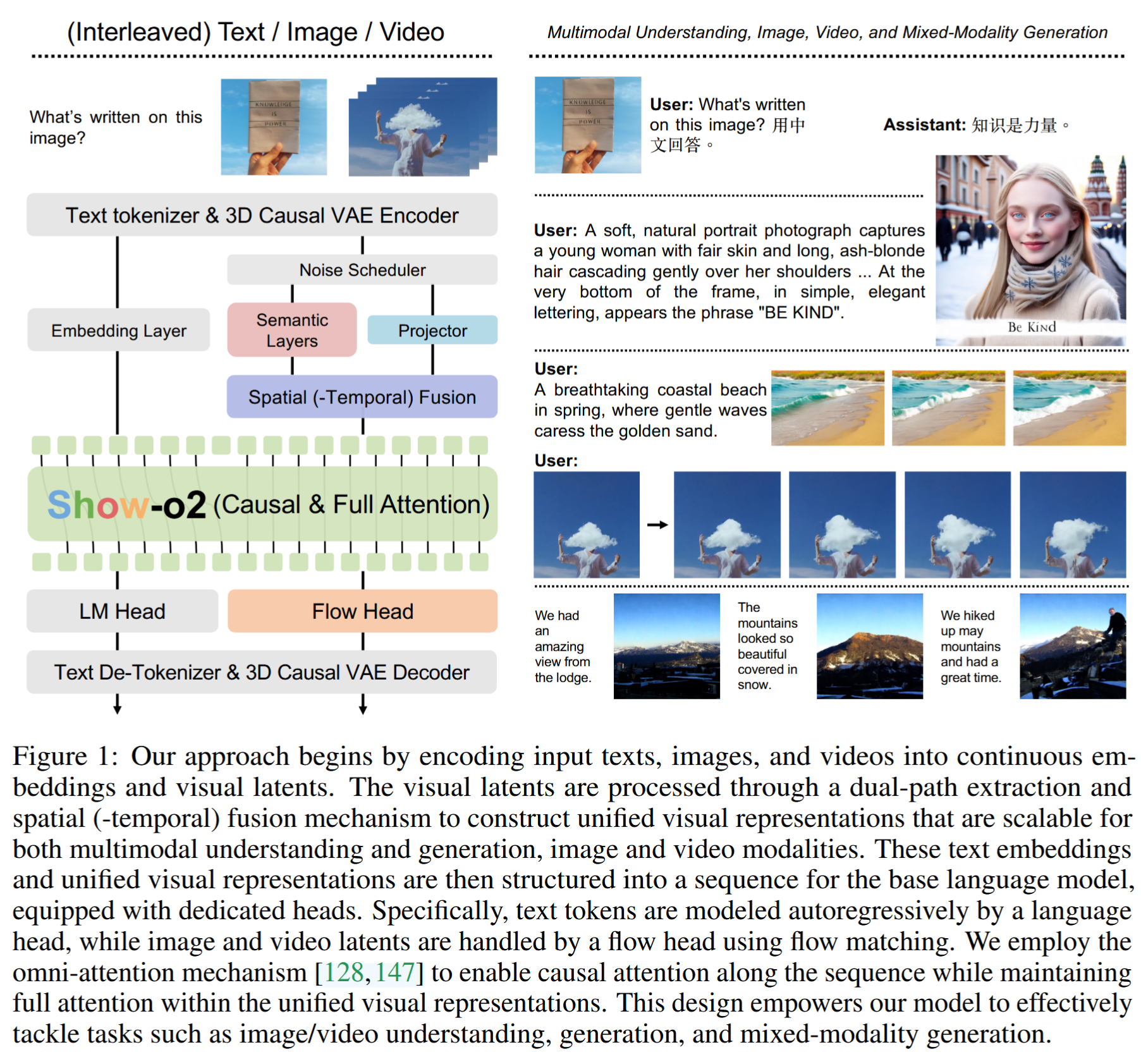
- 视觉编码: 使用3D因果VAE编码器 Wan2.1 将图像/视频编码为视觉潜在表示。
- 统一表示构建(双路径融合): 视觉潜在表示经过双路径提取:
- 语义层 ( S ( ⋅ ) \mathcal{S}(\cdot) S(⋅)) SigLIP-so400m-patch14384∗: 提取具有丰富语义上下文信息的高级表示。
- 投影仪 ( P ( ⋅ ) \mathcal{P}(\cdot) P(⋅)): 用于保留完整的低级信息。
- 空间(-时间)融合 (STF): 将高级和低级表示进行特征维度上的连接和融合,得到统一视觉表示。
- 序列建模与注意力: 文本嵌入和统一视觉表示被结构化为一个序列,输入到基础语言模型。采用全注意力机制(Omni-attention):序列上的注意力是因果的,但在统一视觉表示内部是完全注意力。
- 学习目标: 总损失函数 L \mathcal{L} L 结合了语言头上的下一词元预测(Next Token Prediction, L N T P \mathcal{L}_{NTP} LNTP) 和Flow Head上的 Flow Matching, L F M \mathcal{L}_{FM} LFM) 目标。
2. 两阶段训练方案 (Two-stage Training Recipe)
两阶段所使用的数据集
66M image: CC12M, COYO, LAION-Aesthetic-12M∗ and AI synthetic data
9M high-quality multimodal understanding instruction data: Densefusion-1M, and LLaVA-OneVision

该方案旨在有效保留语言知识,同时学习视觉生成能力:
- 阶段一: 主要训练投影仪、空间(-时间)融合模块和流头 ,使用(交错的)文本、图像和视频数据,侧重于视觉生成能力的预训练。
- 阶段二: 使用高质量的多模态理解和生成数据,对整个模型(不含VAE)进行微调,以增强模型的通用能力。
实验介绍
论文使用基于Qwen2.5-1.5B-Instruct和Qwen2.5-7B-Instruct的模型变体进行了广泛的实验。
-
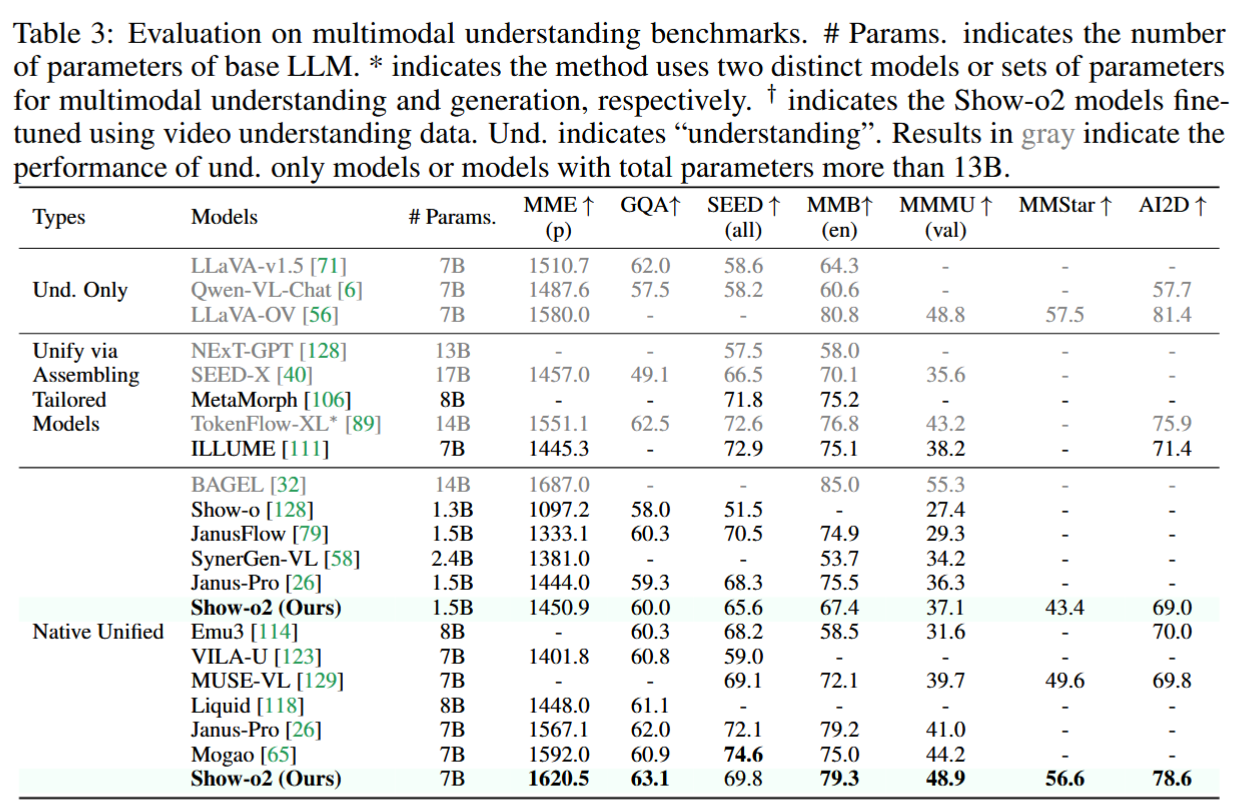
多模态理解评估: 在MME、GQA、SEED-Bench、MM-Bench、MMMU、MMStar和AI2D等多个基准上进行了评估。
-
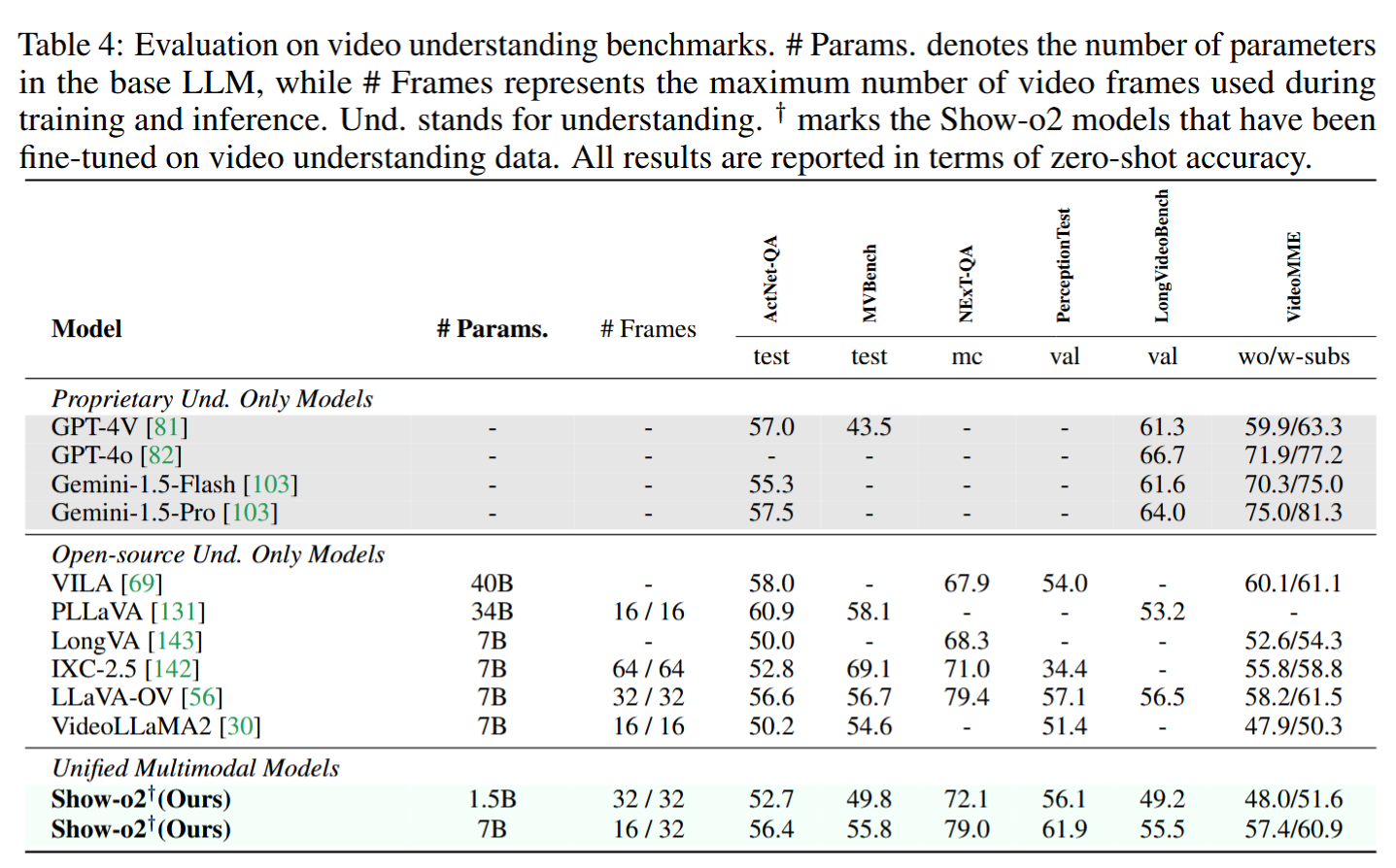
视频理解评估: 在多个视频理解基准上进行了零样本准确率评估。
-
主要成果:
- 在多模态理解任务上,1.5B和7B的Show-o2变体在多数指标上持续优于现有的最先进模型。
- 7B模型在MME-p、GQA、MMMU-val、MMStar和AI2D等指标上超越了参数量更大(例如14B的TokenFlow-XL)或同等规模(例如Janus-Pro)的模型,体现了统一视觉表示和训练策略的有效性。
- 模型在视频理解和视觉生成基准上也展现了强大的能力。
-
效果展示

核心贡献
- 提出了改进的原生统一多模态模型(Show-o2) ,无缝集成了自回归建模和流匹配,实现了对(交错的)文本、图像和视频的广泛多模态理解和生成。
- 构建了统一的视觉表示 ,基于3D因果VAE空间,通过空间(-时间)融合的双路径机制结合语义和低级特征,使其可扩展到多模态理解和生成任务,以及图像和视频模态。
- 设计了有效的两阶段训练流水线 ,该方案能够高效地学习统一多模态模型,保留语言知识 并能有效地扩展到更大的模型,而不需要大规模文本语料库。
- 模型在多模态理解和视觉生成基准上取得了最先进的性能,在各种指标上超越了现有方法。