CLIP (Contrastive Language--Image Pre-training) 是由 OpenAI 于 2021 年推出的一种**跨模态(Cross-Modal)**预训练模型,它的出现极大地改变了计算机视觉和自然语言处理的结合方式,并成为了后来所有优秀文生图模型(如 DALL-E 2、Stable Diffusion)的基础。
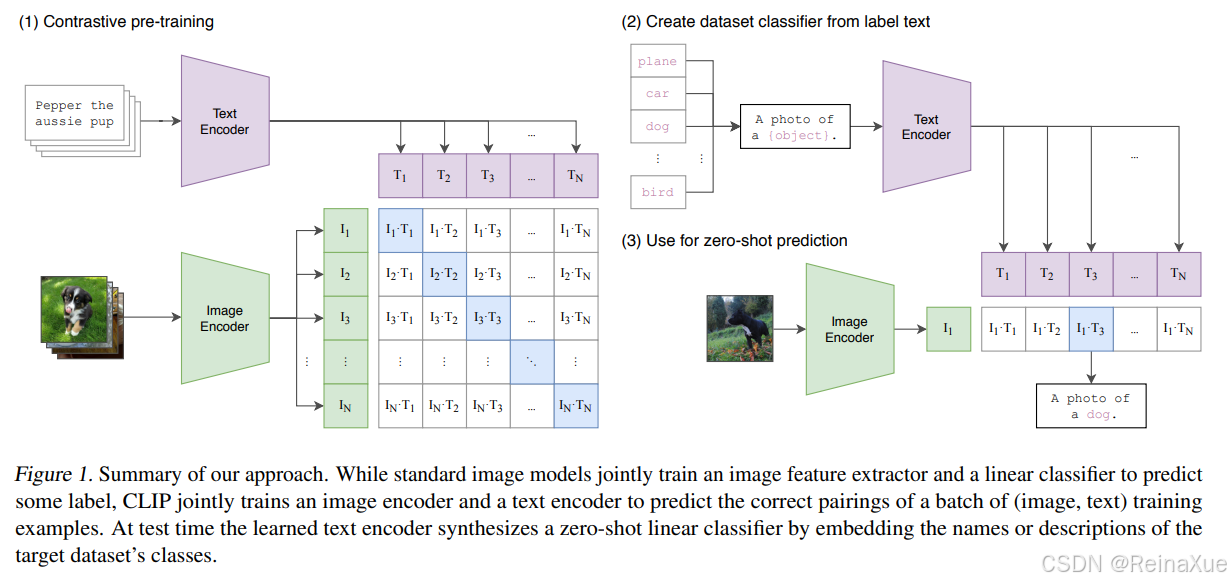
1. CLIP 的核心思想:视觉与语言的桥梁
CLIP 的核心思想是:
通过对比学习,将图像和文本映射到一个共享的、低维的表示空间(Embedding Space)中,使得匹配的图像和文本对(例如,一只猫的图片和文本"一只可爱的猫")在这个空间中的距离更近,而不匹配的对距离更远。
结构组成
CLIP 主要由两个独立的编码器组成:
-
图像编码器 (Image Encoder):负责将输入的图像 I 转换成图像向量 E_I。
- 架构选择:通常使用 ResNet 或 Vision Transformer (ViT) 结构。
-
文本编码器 (Text Encoder):负责将输入的文本 T 转换成文本向量 E_T。
- 架构选择:通常使用 Transformer 结构。
这两个编码器都是独立训练的,但它们的输出维度必须相同,以便在共享的潜在空间中进行比较。
2. 训练方法:对比学习 (Contrastive Learning)
CLIP 的训练是其成功的关键,它使用了对比学习的方法,在大规模数据集上进行预训练。
2.1 训练数据
CLIP 使用了从互联网上收集的 4 亿 (400 Million) 个 (图像, 文本) 配对数据。这些数据是"自然"配对的,例如,图片和它的 Alt-text(替代文本)、标题或描述。
2.2 训练目标:InfoNCE 损失
假设一个训练批次中有 对 (图像
, 文本
) 样本。
-
计算嵌入(Embeddings):
-
将所有
张图像编码为
-
将所有
-
-
计算相似度矩阵:
-
通过计算所有
-
对角线元素
-
非对角线元素
-
-
计算损失函数 (InfoNCE):
-
目标是最大化 对角线元素的相似度,同时最小化所有非对角线元素的相似度。
-
可以理解为,模型需要区
-
其中, 是温度参数(Temperature Parameter),用于调整分布的集中程度。
2.3 训练结果的意义
训练完成后,CLIP 学习到的共享嵌入空间具有强大的特性:
-
语义对齐:在这个空间中,"一只狗的图片"的向量会非常接近于"一条狗"的文本向量,甚至会接近于"一只忠实的宠物"的文本向量。
-
零样本能力的基础:图像和文本之间的语义关系被直接编码在这个空间中。
3. CLIP 的革命性应用:零样本学习 (Zero-Shot Learning)
CLIP 最强大的能力在于其**零样本(Zero-Shot)**分类和识别能力。
3.1 传统分类 vs. CLIP
| 特性 | 传统分类模型(如 ResNet) | CLIP (Zero-Shot) |
|---|---|---|
| 训练 | 需要在特定任务数据集(如 ImageNet 的 1000 个类别)上进行训练。 | 在大规模图像-文本对上预训练,不针对任何具体类别。 |
| 推理/新任务 | 需要收集新任务数据,并进行微调 (Fine-tuning)。 | 无需训练,通过文本描述直接推理。 |
3.2 CLIP 的零样本分类步骤
假设我们要对一张图片 I 进行分类,判断它是否属于 \\{C_1, C_2, \\dots, C_K\\} 这 K 个类别中的一个。
-
文本提示工程 (Prompt Engineering) :为每个类别 C_k 构建一个文本提示 (Text Prompt),例如:"A photo of a C_k." (一张 C_k 的照片)。
-
获取嵌入:
-
使用图像编码器得到图像嵌入 E_I。
-
使用文本编码器得到所有 K 个文本提示的嵌入 \\{E_{T_1}, \\dots, E_{T_K}\\}。
-
-
计算相似度 :计算 E_I 与所有 \\{E_{T_k}\\} 之间的余弦相似度。
-
分类:选择相似度最高的那个文本提示所对应的类别 C_k 作为预测结果。
这个过程完全不需要在目标数据集上进行任何梯度更新,体现了强大的泛化能力。
4. CLIP 的重要性及衍生模型
4.1 重要性
-
解决了通用性问题 :CLIP 证明了可以从互联网上大量的"弱监督"数据(图像-文本对)中学习到一种通用的、强大的视觉表示,能够泛化到很多从未见过的视觉概念上。
-
统一了视觉和语言 :它提供了一个标准的、可计算的语义空间,使得计算机能够通过文本理解图像的内容,反之亦然。
-
驱动生成模型 :CLIP 是文生图模型(如 DALL-E 2、Stable Diffusion、Midjourney)的关键组件。
-
引导生成 :在生成过程中,CLIP 相似度被用作损失函数(CLIP Loss) ,来引导生成器(如扩散模型)朝着与输入文本描述语义最匹配的方向去修改和优化图像。
-
效果评估:生成的图像是否符合文本提示,也可以用图像和文本嵌入的 CLIP 相似度来衡量。
-
4.2 衍生模型
CLIP 的成功启发了许多后续工作:
-
ALIGN (Google):使用了更大的数据集(18 亿对)和不同的架构,进一步验证了对比学习的有效性。
-
OpenCLIP:社区复现和开源的 CLIP 训练框架,使得研究人员可以更容易地训练和使用 CLIP 模型。
-
文生图模型:所有 SOTA (State-of-the-Art) 的文生图模型都依赖 CLIP 来理解用户输入的文本提示,并评估生成图像的质量。
总而言之,CLIP 是一个跨时代的模型,它将图像和文本拉进了同一个语义表示空间,奠定了现代多模态 AI 的基石。