字节跳动的SEED TTS(Seed-TTS)是一系列大规模自回归文本转语音(TTS)模型,能够生成与人类语音几乎没有区别的高质量语音。该模型在语音上下文学习方面表现出色,尤其在说话者相似度和自然度方面的表现,与真实人类语音相匹配。
1 模型架构
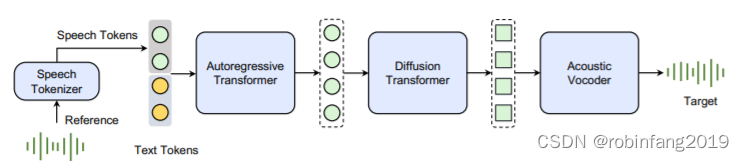
1.1 模型架构组成
Seed-TTS 模型主要由语音分词器、语言模型、扩散模型、 语音合成器组成。
1.1.1 语音分词器 (Speech Tokenizer)
- 功能:将语音信号转换为离散的语音 token 序列。
- 类型:可以是连续语音分词器或离散语音分词器。
- 作用:降低模型复杂度,提高训练效率。
1.1.2 语言模型 (Token Language Model)
- 功能:根据文本和语音 token 序列生成语音 token 序列。
- 类型:自回归 Transformer 模型。
- 作用:学习文本和语音之间的关系,生成自然流畅的语音。
1.1.3 扩散模型 (Diffusion Model)
- 功能:根据语音 token 序列生成连续的语音特征表示。
- 类型:自回归 Transformer 模型。
- 作用:学习语音特征之间的关系,生成具有丰富细节的语音。
1.1.4 语音合成器 (Acoustic Vocoder)
- 功能:将语音特征表示转换为语音波形。
- 类型:例如 WaveNet、HiFiGAN 等。
- 作用:生成高质量的语音波形。
1.2 模型架构特点
- 自回归模型:使用自回归模型进行语音生成,可以保证语音的流畅性和自然度。
- Transformer 模型:使用 Transformer 模型进行语音生成,可以学习更复杂的语音生成规律。
- 扩散模型:使用扩散模型进行语音生成,可以生成具有丰富细节的语音。
- 端到端训练:将语音分词器、语言模型、扩散模型和语音合成器联合训练,可以提高模型的性能。
1.3 变体
- Seed-TTSDiT:基于扩散模型的非自回归 TTS 模型,可以直接预测语音特征的潜表示,具有更简单的流程和更快的生成速度。
- Seed-TTSVC:基于 Seed-TTS 模型的语音转换模型,可以转换说话人身份、音色和语调等。
2模型的训练过程
Seed-TTS 模型的训练过程可以分为三个阶段:
2.1 预训练阶段
- 目标:最大化场景和说话人覆盖范围,建立健壮的语音生成基础模型。
- 数据:使用大量语音数据,比之前的 TTS 模型规模大几个数量级。
- 任务:学习将文本和语音数据转换为对应的编码表示。
- 模型:采用自回归 Transformer 模型,包括语音分词器、语言模型和扩散模型。
- 损失函数:使用交叉熵损失函数。
2.2 微调阶段
- 目标:提高模型对特定说话人或指令的控制能力。
- 数据:使用特定说话人的语音数据或指令数据。
- 任务:
- 说话人微调:学习特定说话人的音色和语调。
- 指令微调:学习理解并执行特定指令,例如控制情感、语速等。
- 模型:使用预训练的 Seed-TTS 模型作为基础模型,并进行微调。
- 损失函数:使用与预训练阶段相同的损失函数,并根据需要添加额外的损失函数,例如说话人相似度损失函数。
2.3 后训练阶段
- 目标:进一步提高模型的性能,包括鲁棒性、说话人相似度和可控性。
- 方法:使用强化学习技术,例如 REINFORCE 或 Proximal Policy Optimization。
- 奖励函数:根据需要设计奖励函数,例如说话人相似度、情绪控制准确率等。
- 模型:使用微调后的 Seed-TTS 模型作为基础模型,并进行后训练。
2.4 训练过程中的关键因素
- ++++数据质量:高质量的数据是训练出高性能 TTS 模型的关键。++++
- 模型规模:更大的模型规模可以学习更复杂的语音生成规律。
- 训练时间:TTS 模型的训练时间较长,需要耐心等待。
- 损失函数:合适的损失函数可以有效地指导模型学习。
- 评估指标:客观指标和主观评估可以全面评估模型的性能。
3 技术创新
3.1 基础模型 (Foundation Model)
- 大规模数据训练: Seed-TTS 使用比以往 TTS 系统大几个数量级的数据进行训练,涵盖了更广泛的场景和说话人,使得模型具有更强的泛化能力和涌现能力。
- 自回归 Transformer 模型: Seed-TTS 使用自回归 Transformer 模型进行语音生成,可以学习更复杂的语音生成规律,生成更自然流畅的语音。
- 扩散模型: Seed-TTS 使用扩散模型进行语音生成,可以生成具有丰富细节的语音,例如音色、语调和情感等。
3.2 上下文学习 (In-context Learning)
- 零样本上下文学习: Seed-TTS 可以根据少量语音样本生成与样本具有相同音色和语调的语音,即使是在野外采集的语音样本也能取得很好的效果。
- 多任务学习: Seed-TTS 可以同时进行说话人调整和指令调整,使得生成的语音具有更高的可控性和交互性。
3.3 模型扩展 (Model Extensions)
- 语音分解 (Speech Factorization): Seed-TTS 通过自蒸馏方法实现语音分解,可以将语音分解为不同的独立属性,例如音色、语调和情感等,从而可以灵活地合成具有不同属性的语音。
- 强化学习 (Reinforcement Learning): Seed-TTS 通过强化学习技术进一步提高模型的性能,例如提高说话人相似度、鲁棒性和情感控制能力。
3.4 非自回归模型 (Non-Autoregressive Model)
- Seed-TTSDiT: Seed-TTS 的非自回归变体,使用扩散模型直接预测语音特征的潜表示,具有更简单的流程和更快的生成速度。
- 语音编辑: Seed-TTSDiT 可以进行语音编辑,例如内容编辑和语速编辑,为语音合成应用提供了更多可能性。
3.5低延迟推理和流式处理 (Low-latency Inference and Streaming Processing)
- 因果扩散架构: Seed-TTS 使用因果扩散架构,可以在扩散模块中实现流式处理,从而显著降低处理延迟和第一包延迟。
- 模型压缩: Seed-TTS 使用各种模型压缩技术,例如分组查询注意力、分页注意力、FlashAttention 和模型量化等,可以降低模型的计算成本和内存消耗,使其更易于部署。
4 实验
4.1 零样本上下文学习 (Zero-shot In-context Learning):
- 数据集: 使用了两个测试集,分别包含英语和中文的语音样本,用于评估模型在客观指标和主观评价方面的表现。
- 评价指标: 使用词错误率 (WER) 和说话人相似度 (SIM) 进行客观评估,使用主观平均意见得分 (CMOS) 进行主观评价。
- 实验结果: Seed-TTS 在客观指标上取得了与真实人类语音相当的性能,在主观评价方面也取得了非常接近真实人类语音的得分,证明了模型在零样本上下文学习方面的强大能力。
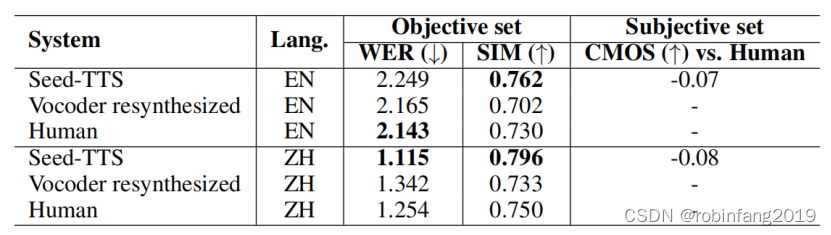
与传统说话人调整模型的对比: 与传统的说话人调整模型相比,Seed-TTS 在"常见"说话人集上表现出明显的优势,但在"困难"说话人集上仍然存在一定的差距。
4.2 说话人调整 (Speaker Fine-tuning)
- 数据集: 使用了 5 个说话人的语音数据,用于对 Seed-TTS 进行说话人调整。
- 评价指标: 使用词错误率 (WER)、说话人相似度 (SIM) 和主观平均意见得分 (CMOS) 进行评估。
- 实验结果: 说话人调整后的 Seed-TTS 在客观指标上与基线模型相当,但在主观评价方面取得了更高的得分,表明模型可以更好地捕捉目标说话人的细微特征,例如语调和发音模式。
4.3 情感控制 (Emotion Control)
- 数据集: 使用了 4 种主要情感的语音数据,用于评估模型对情感的控制能力。
- 评价指标: 使用语音情感识别 (SER) 模型的准确率进行评估。
- 实验结果: 即使没有明确的控制信号,Seed-TTS 仍然可以取得一定的情感控制能力,当结合额外的控制信号时,可以显著提高情感控制准确率。
4.4低延迟推理和流式处理 (Low-latency Inference and Streaming Processing)
- 优化方法: 使用了因果扩散架构、一致性蒸馏、修改的流匹配算法、分组查询注意力、分页注意力、FlashAttention 和模型量化等技术。
- 实验结果: 优化后的模型在主观和客观测试中取得了与离线模型相当的性能,同时显著降低了延迟、计算成本和内存消耗。

4.5 语音分解 (Speech Factorization)
- 方法: 使用自蒸馏方法,通过生成具有不同音色的语音对来训练模型,实现音色的分解。
- 实验结果: 与传统的语音分解方法相比,Seed-TTS 的自蒸馏方法在音色分解方面取得了更好的性能,在零样本语音转换任务中取得了更高的说话人相似度。
4.6 强化学习 (Reinforcement Learning)
- 方法: 使用 REINFORCE 算法,分别使用说话人相似度和词错误率、以及语音情感识别模型的准确率作为奖励函数,对模型进行训练。
- 实验结果: 强化学习可以显著提高模型的说话人相似度、鲁棒性和情感控制能力,但也需要注意奖励黑客问题。
4.7 非自回归模型 (Non-Autoregressive Model)
- 模型: Seed-TTSDiT,一个完全基于扩散模型的语音合成模型。
- 实验结果:++++Seed-TTSDiT 在说话人相似度方面取得了比 Seed-TTS 更好的性能,在词错误率方面与 Seed-TTS 相当,并且在语音编辑任务中表现出色++++。