torch.nn --- PyTorch 2.3 documentation
torch.nn - PyTorch中文文档 (pytorch-cn.readthedocs.io)
torch.nn和torch.nn.functional的区别
-
torch.nn是对torch.nn.functional的一个封装,让使用torch.nn.functional里面的包的时候更加方便
-
torch.nn包含了torch.nn.functional,打个比方,torch.nn.functional相当于开车的时候齿轮的运转,torch.nn相当于把车里的齿轮都封装好了,为我们提供一个方向盘
-
如果只是简单应用,会torch.nn就好了。但要细致了解卷积操作,需要深入了解torch.nn.functional
-
打开torch.nn.functional的官方文档,可以看到许多跟卷积相关的操作:torch.nn.functional --- PyTorch 2.3 documentation
torch.nn中Convolution Layers 卷积层
- 一维卷积层 torch.nn.Conv1d
- 二维卷积层 torch.nn.Conv2d
- 三维卷积层 torch.nn.Conv3d
一维卷积层 torch.nn.Conv1d
class torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
一维卷积层,输入的尺度是(N, C_in,L),输出尺度( N,C_out,L_out)的计算方式:
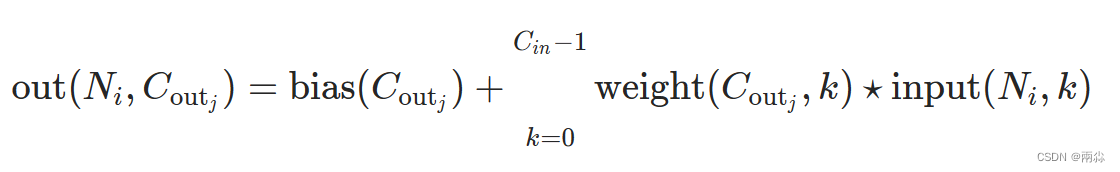
说明
bigotimes: 表示相关系数计算stride: 控制相关系数的计算步长dilation: 用于控制内核点之间的距离,详细描述在这里groups: 控制输入和输出之间的连接,group=1,输出是所有的输入的卷积;group=2,此时相当于有并排的两个卷积层,每个卷积层计算输入通道的一半,并且产生的输出是输出通道的一半,随后将这两个输出连接起来。
Parameters:
- in_channels(
int) -- 输入信号的通道 - out_channels(
int) -- 卷积产生的通道 - kerner_size(
intortuple) - 卷积核的尺寸 - stride(
intortuple,optional) - 卷积步长 - padding (
intortuple,optional)- 输入的每一条边补充0的层数 - dilation(
intortuple, `optional``) -- 卷积核元素之间的间距 - groups(
int,optional) -- 从输入通道到输出通道的阻塞连接数 - bias(
bool,optional) - 如果bias=True,添加偏置
shape:
输入: (N,C_in,L_in)
输出: (N,C_out,L_out)
输入输出的计算方式:

变量:
weight(tensor) - 卷积的权重,大小是(out_channels, in_channels, kernel_size)
bias(tensor) - 卷积的偏置系数,大小是(out_channel)
二维卷积层
1、torch.nn.functional.conv2d
torch.nn.functional.conv2d(input , weight , bias=None , stride=1 , padding=0 , dilation=1 , groups=1)
对几个输入平面组成的输入信号应用2D卷积。
参数:
-
input : 输入,数据类型为tensor ,形状尺寸规定为:(minibatch, 几个通道(in_channels), 高, 宽)
-
weight : 权重。更专业地来说可以叫卷积核 ,形状尺寸规定为:*(输出的通道(out_channel),*in_channels/groups(groups一般取1), 高kH, 宽kW)
-
bias: 偏置。可选偏置张量 (out_channels)
-
strids: 步幅。卷积核的步长,可以是单个数字或一个元组 (sh x sw)
-
padding : 填充。默认为1 - padding -- 输入上隐含零填充。可以是单个数字或元组。
-
默认值:0 - groups -- 将输入分成组,in_channels应该被组数除尽
举例讲解参数strids
输入一个5×5的图像,其中的数字代表在每个像素中的颜色显示。卷积核设置为3×3的大小。
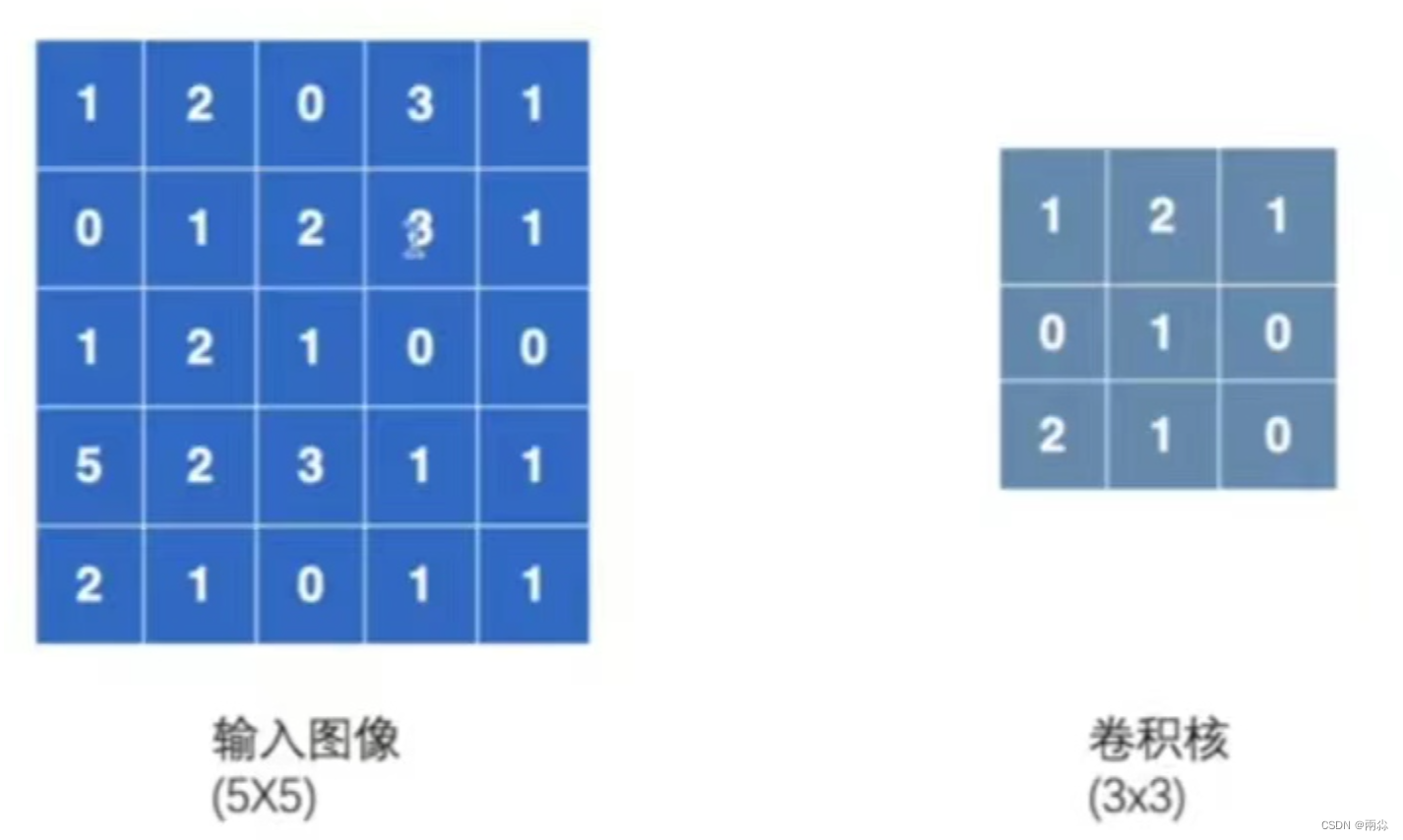
- strids 参数的输入格式是单个数 或者形式为 (sH,sW) 的元组,可以理解成:比如输入单个数:strids=1 ,每次卷积核在图像中向上下或左右移1位;如果输入strids=(2,3),那么每次卷积核在图像中左右移动(横向移动)时,是移动2位,在图像中上下移动(纵向移动)时,是移动3位。
- 本例设置strids=1
第一次移位:
- 基于上述的假设,在做卷积的过程中,需要将卷积核将图像的前三行和前三列进行匹配:
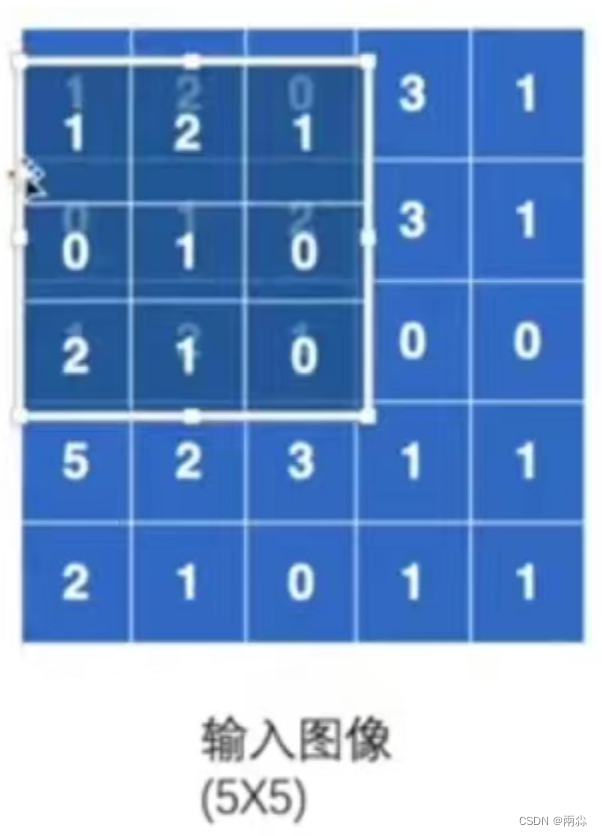
- 在匹配过后,进行卷积计算 :对应位相乘然后相加,即
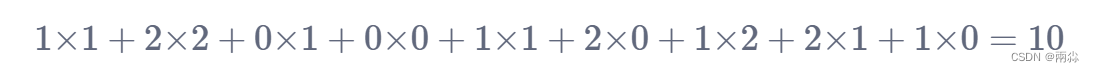
- 上面的得出的10可以赋值给矩阵,然后作为一个输出

之后卷积核可以在图像中进行一个移位,可以向旁边走1位或2位,如下图(向右走2位)。具体走多少位由strids 参数决定,比如strids=2 ,那就是走2位。本例设置stride=1。
第二次移位:
- 向右移动一位,进行卷积计算:
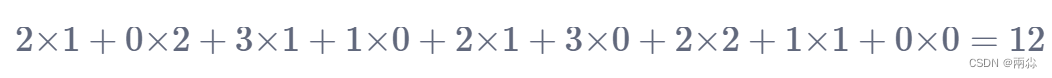
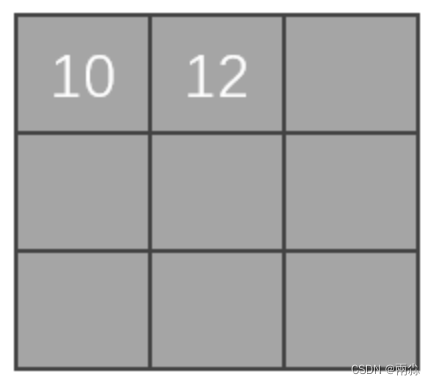
以此类推,走完整个图像,最后输出的矩阵如下图。这个矩阵是卷积后的输出。

举例讲解参数padding
padding的作用是在输入图像的左右两边进行填充,padding的值决定填充的大小有多大,它的输入形式为一个整数 或者一个元组 ( padH, padW ) ,其中,padH=高 ,padW=宽 。默认padding=0,即不进行填充。
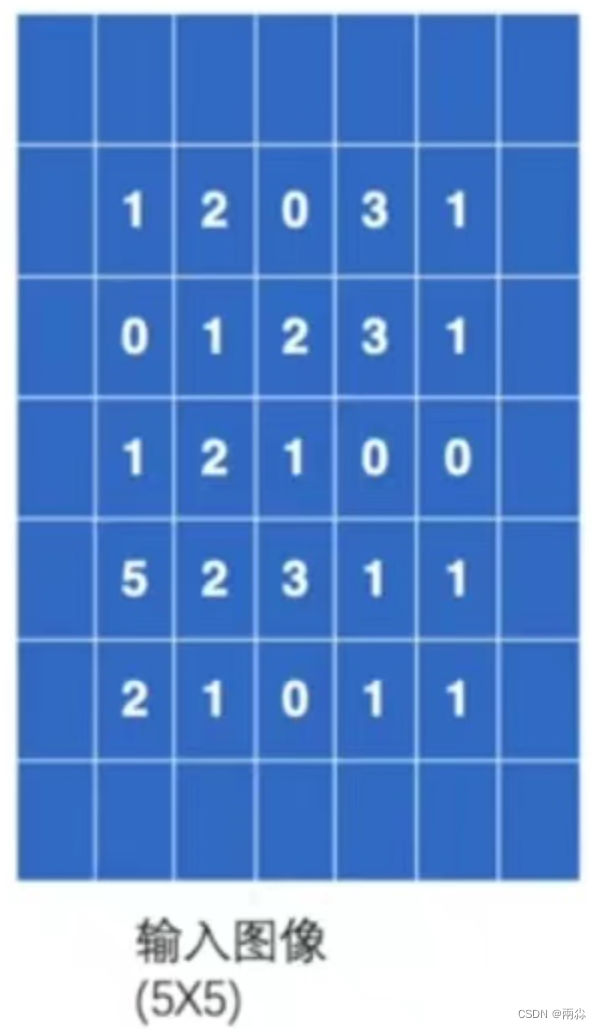
- 仍输入上述的5×5的图像,并设置padding=1,那么输入图像将会变成下图,即图像的上下左右都会拓展一个像素,然后这些空的地方像素(里面填充的数据)都默认为0。
- 按上面的顺序进行卷积计算,第一次移位时在左上角3×3的位置,卷积计算公式变为:
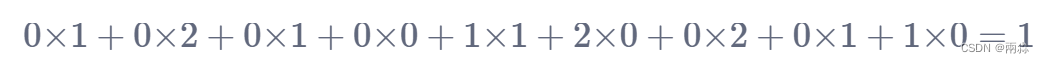
- 以此类推,完成后面的卷积计算,并输出矩阵
程序代码
python
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
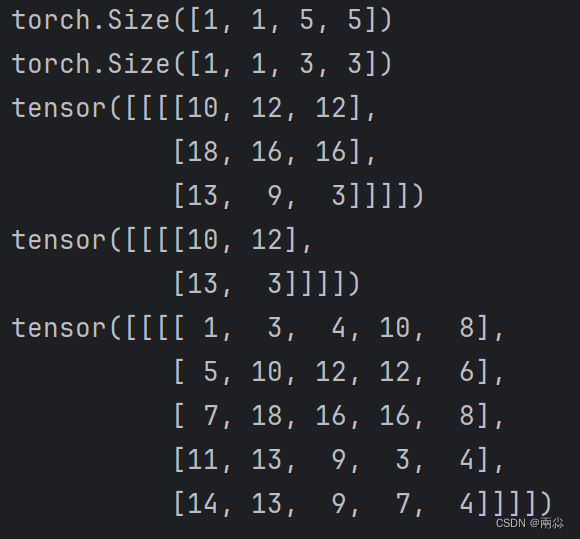
print(input.shape)
print(kernel.shape)
output = F.conv2d(input, kernel, stride=1)
print(output)
# Stride=2
output2 = F.conv2d(input, kernel, stride=2)
print(output2)
# padding=1
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print(output3)运行结果
2、torch.nn.Conv2d
class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
Parameters:
- in_channels(
int) -- 输入信号的通道。输入图像的通道数,彩色图像一般为3(RGB三通道) - out_channels(
int) -- 卷积产生的通道。产生的输出的通道数 - kerner_size(
intortuple) - 卷积核的尺寸。一个数或者元组,定义卷积大小。如kernel_size=3 ,即定义了一个大小为3×3 的卷积核;kernel_size=(1,2) ,即定义了一个大小为1×2的卷积核。 - stride(
intortuple,optional) - 卷积步长。 默认为1,卷积核横向、纵向的步幅大小 - padding(
intortuple,optional) - 默认为0,对图像边缘进行填充的范围 - dilation(
intortuple,optional) -- 卷积核元素之间的间距。默认为1,定义在卷积过程中,它的核之间的距离。这个我们称之为空洞卷积,但不常用。 - groups(
int,optional) -- 从输入通道到输出通道的阻塞连接数。默认为1。分组卷积,一般都设置为1,很少有改动 - bias(
bool,optional) - 默认为True。偏置,常年设置为True。代表卷积后的结果是否加减一个常数。
二维卷积层, 输入的尺度是(N, C_in,H,W),输出尺度(N,C_out,H_out,W_out)
关于卷积操作,官方文档的解释如下:

图像输入输出尺寸转化计算公式
参数说明:
-
N: 图像的batch_size
-
C: 图像的通道数
-
H: 图像的高
-
W: 图像的宽
计算过程
shape:
input: (N,C_in,H_in,W_in)
output: (N,C_out,H_out,W_out)or(C_out,H_out,W_out)
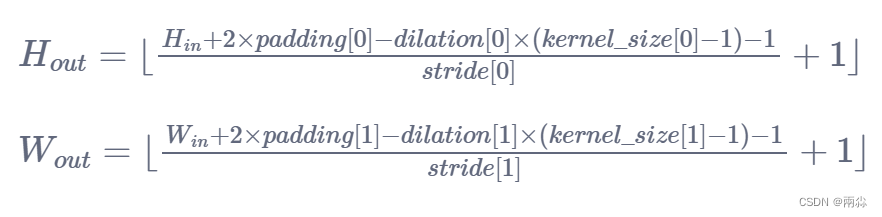
看论文的时候,有些比如像padding这样的参数不知道,就可以用这条公式去进行推导
变量:
weight(tensor) - 卷积的权重,大小是(out_channels, in_channels,kernel_size)
bias(tensor) - 卷积的偏置系数,大小是(out_channel)
参数kernel_size的说明
-
kernel_size主要是用来设置卷积核大小尺寸的,给定模型一个kernel_size,模型就可以据此生成相应尺寸的卷积核。
-
卷积核中的参数从图像数据分布中采样计算得到的。
-
卷积核中的参数会通过训练不断进行调整。
参数out_channel的说明
- 如果输入图像in_channel=1,并且只有一个卷积核,那么对于卷积后产生的输出,其out_channel也为1
- 如果输入图像in_channel=2,此时有两个卷积核,那么在卷积后将会输出两个矩阵,把这两个矩阵当作一个输出,此时out_channel=2
程序代码
使用CIFAR中的图像数据,对Conv2d进行讲解
python
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import Dataset, DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
print(tudui)
writer = SummaryWriter('./logs')
step = 0
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
print(imgs.shape) # torch.Size([64, 3, 32, 32])
print(outputs.shape) # torch.Size([64, 6, 30, 30])
writer.add_images("input", imgs, step)
# torch.Size([64, 6, 30, 30]) ->> [64, 3, 32, 32]
output = torch.reshape(outputs, [-1, 3, 30, 30])#由于第一个值不知道是多少,所以写-1,它会根据后面的值去计算
writer.add_images("output", output, step)
step += 1
writer.close()