
1.单个神经元
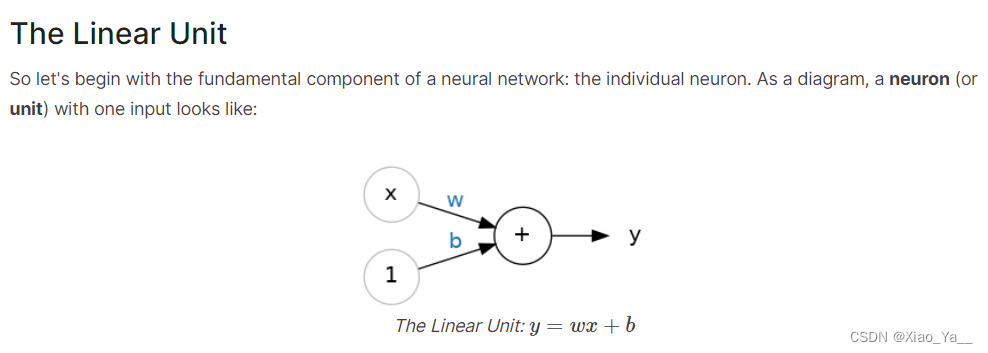
创建一个具有1个线性单元的网络
#线性单元
from tensorflow import keras
from tensorflow.keras import layers
#创建一个具有1个线性单元的网络
model=keras.Sequential([
layers.Dense(units=1,input_shape=[3])
])2.深度神经网络
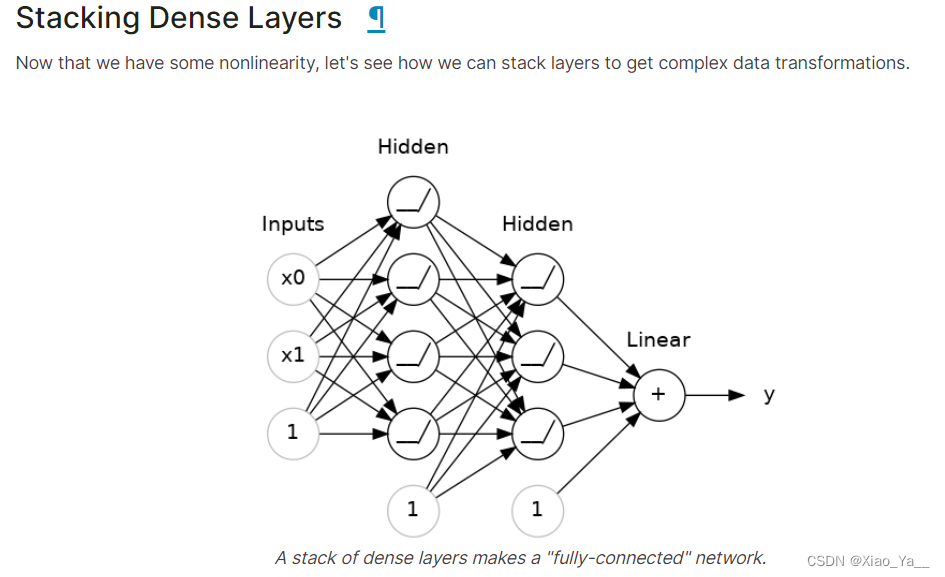
构建序列模型
#构建序列模型
from tensorflow import keras
from tensorflow.keras import layers
model=keras.Sequential([
#隐藏的 ReLU 层
layers.Dense(unit=4,activation='relu',input_shape=[2]),
layers.Dense(unit=3,activation='relu'),
#线性输出层
layers.Dense(units=1),
])重写代码以使用激活层
#重写代码以使用激活层
model = keras.Sequential([
layers.Dense(units=32, input_shape=[8]),
layers.Activation('relu'),
layers.Dense(units=32),
layers.Activation('relu'),
layers.Dense(1),
])3.梯度下降
深度学习中使用的几乎所有优化算法都属于随机梯度下降算法。它们是分步训练网络的迭代算法。训练的一个步骤如下:抽取一些训练数据,并通过网络运行以进行预测。测量预测值与真实值之间的损失。最后,朝着使损失更小的方向调整权重。
一个"损失函数",用于衡量网络预测的好坏。
一个"优化器",可以告诉网络如何改变其权重。
#随机梯度下降
#一个"损失函数",用于衡量网络预测的好坏。
#一个"优化器",可以告诉网络如何改变其权重
#添加损失和优化器¶
#定义模型后,可以使用模型的编译方法添加损失函数和优化器:
model.compile(
optimizer="adam",
loss="mae",
)开始训练:告诉 Keras 每次向优化器提供 256 行训练数据(batch_size),并在整个数据集中执行 10 次。
#开始训练:告诉 Keras 每次向优化器提供 256 行训练数据(batch_size),并在整个数据集中执行10次(epoch)。
history=model.fit(
X_train,y_train,
validation_data=(X_vaild,y_vaild),
batch_size=256,
epochs=10,
)用图表的形式查看损失
#用图表的形式查看损失
import pandas as pd
#将训练历史转换为数据框
history_df=pd.DataFrame(history.history)
#使用 Pandas 原生的 plot 方法
history_df['loss'].plot();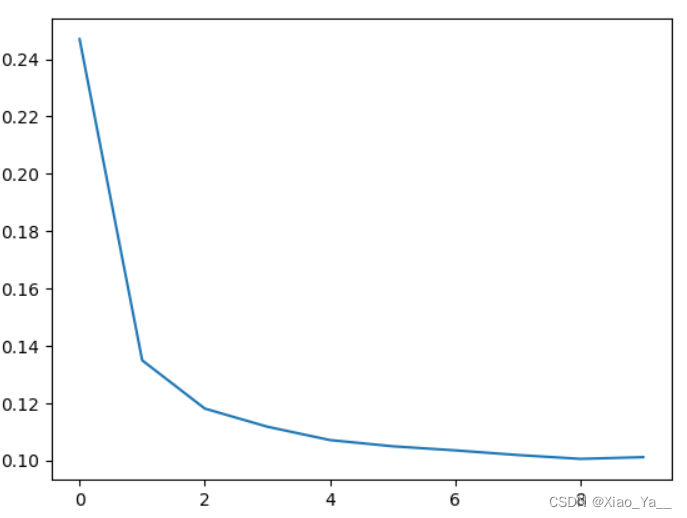
4.过拟合和欠拟合
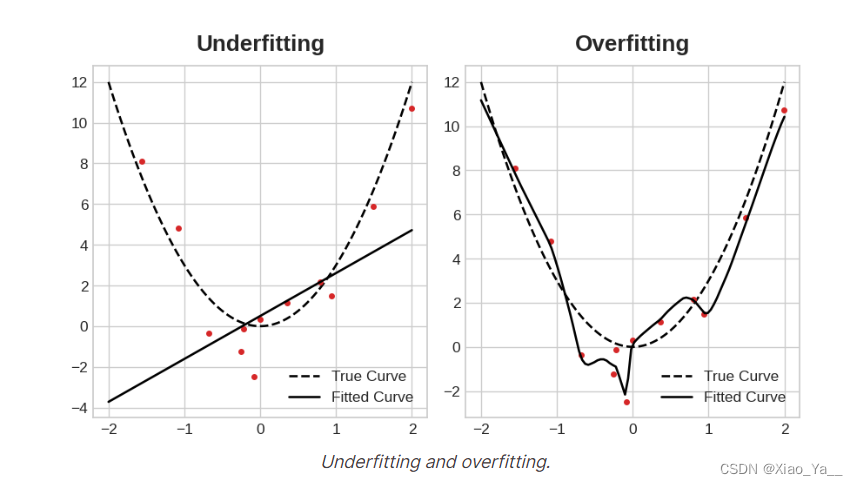
使网络更深(添加更多层)来增加网络的容量。
更宽的网络更容易学习更多的线性关系,而更深的网络则更倾向于非线性关系。
#过拟合和欠拟合
#使网络更深(添加更多层)来增加网络的容量。
#更宽的网络更容易学习更多的线性关系,而更深的网络则更倾向于非线性关系。
model = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(1),
])
wider = keras.Sequential([
layers.Dense(32, activation='relu'),
layers.Dense(1),
])
deeper = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(16, activation='relu'),
layers.Dense(1),
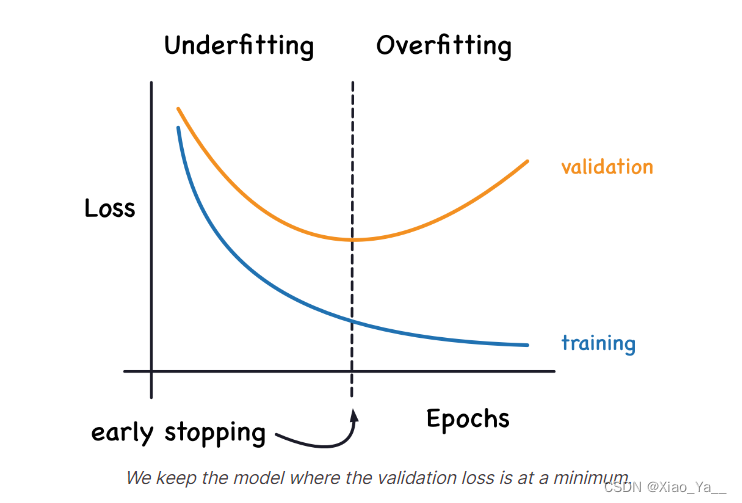
])当模型过于热衷于学习噪声时,验证损失可能会在训练期间开始增加。
为了防止这种情况,我们可以在验证损失似乎不再减少时停止训练。
以这种方式中断训练称为提前停止。
#模型过于热衷于学习噪声时,验证损失可能会在训练期间开始增加。
#为了防止这种情况,我们可以在验证损失似乎不再减少时停止训练。
#以这种方式中断训练称为提前停止。
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(
#视为改进的最小变化量
min_delta=0.001,
#停止前要等待多少个 epoch
patience=20,
restore_best_weights=True,
)5. Dropout和批量标准化
添加 Dropout正则化
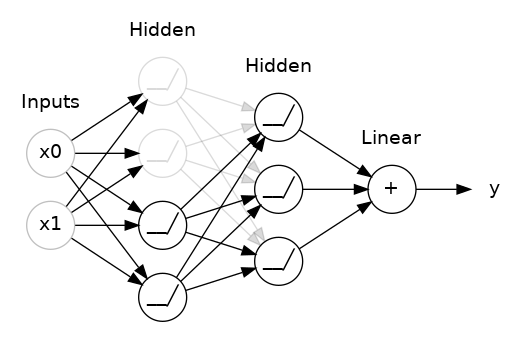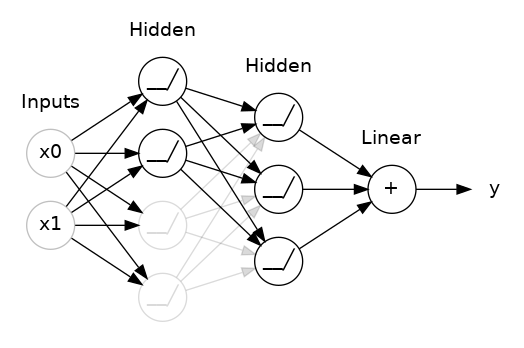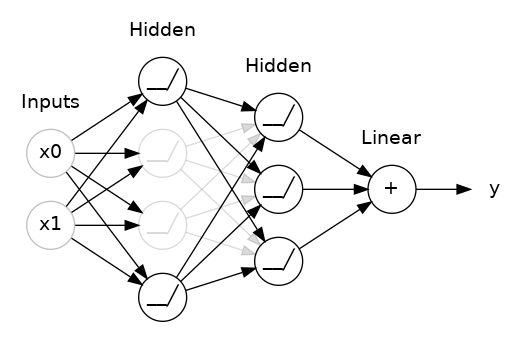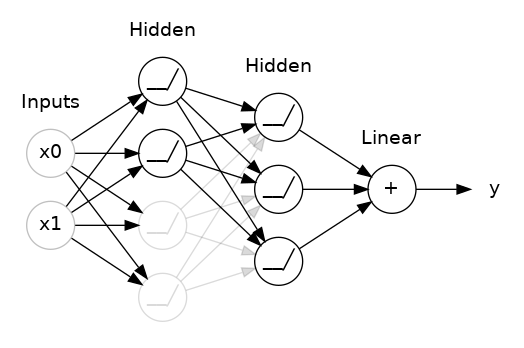
#添加 Dropout正则化
keras.Sequential([
# ...
#将 30% 的 dropout 应用到下一层
layers.Dropout(rate=0.3),
layers.Dense(16),
# ...
])添加批量标准化
#添加批量标准化
layers.Dense(16, activation='relu'),
layers.BatchNormalization(),
#或者
layers.Dense(16),
layers.BatchNormalization(),
layers.Activation('relu'),Droupout和批量标准化
#Droupout和批量标准化
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(1024, activation='relu', input_shape=[11]),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1024, activation='relu'),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1024, activation='relu'),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1),
])6.二分类
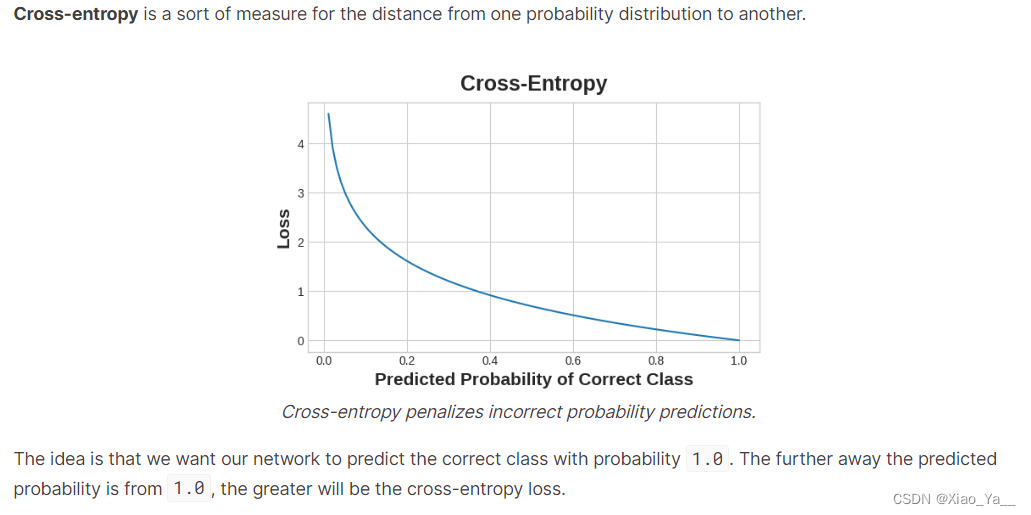

#二分类
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(4, activation='relu', input_shape=[33]),
layers.Dense(4, activation='relu'),
layers.Dense(1, activation='sigmoid'),
])将交叉熵损失和准确度指标添加到模型中
#将交叉熵损失和准确度指标添加到模型中
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['binary_accuracy'],
)这个特定问题中的模型可能需要相当多的时期才能完成训练,因此我们将包含一个早期停止回调以方便使用。
#这个特定问题中的模型可能需要相当多的时期才能完成训练,
#因此我们将包含一个早期停止回调以方便使用。
early_stopping = keras.callbacks.EarlyStopping(
patience=10,
min_delta=0.001,
restore_best_weights=True,
)