kNN的算法思路:找K个离预测点最近的点,然后让它们进行投票决定预测点的类型。
- step 1: kNN存储样本点的特征数据和标签数据
- step 2: 计算预测点到所有样本点的距离,关于这个距离,我们用欧几里德距离来度量(其实还有很多其他的,比如曼哈顿距离等),并进行排序,拿出前k个样本点。
- step 3: 统计前k个样本点的类别,以最多的那个类型作为预测结果。
欧几里德距离:
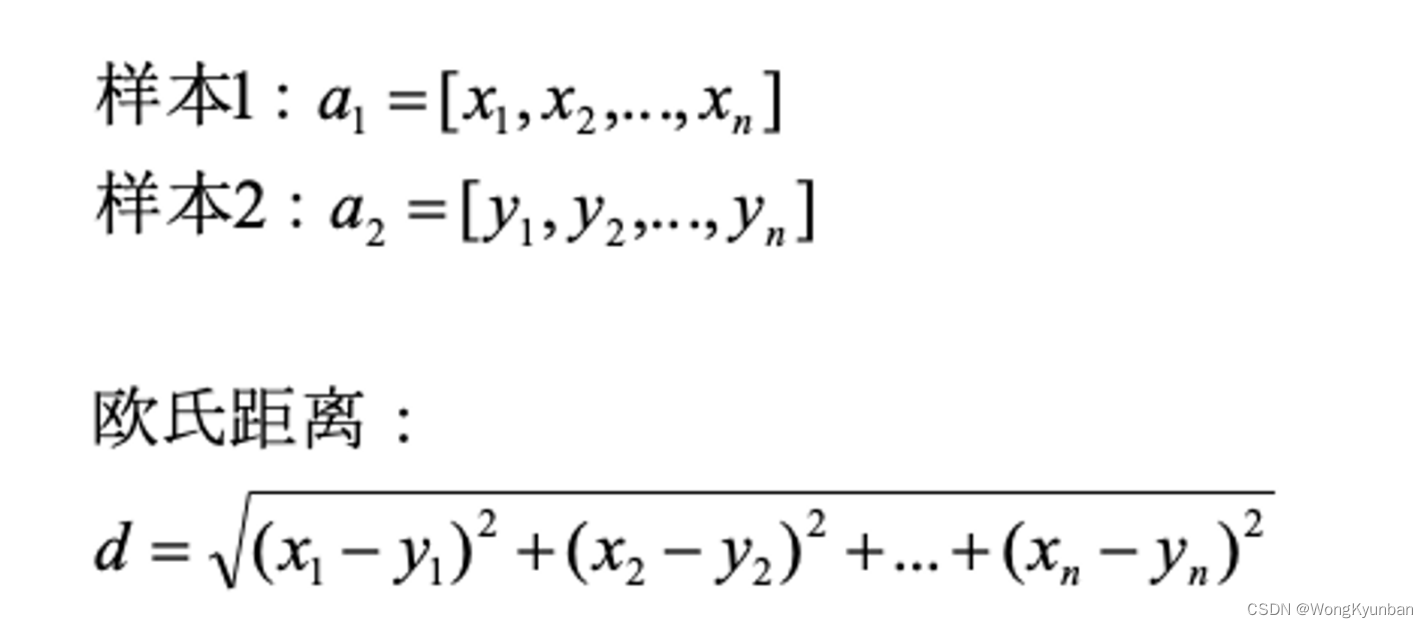
上代码:
python
import numpy as np
# 用于统计
from collections import Counter
class MyKnn:
# 初始化投票的数量,neighbors表示我们要找的点的数量,用于投票决定预测点的类型
def __init__(self,neighbors):
self.k = neighbors
# 因为kNN是一个惰性机器性学习模型,只在预测阶段才会用到的训练数据,不存在训练阶段。或者说在所谓的训练阶段,只是为了存储样本数据。
# X为特征集
# Y为对应的标签集
def fit(self,X,Y):
self.X = np.array(X)
self.Y = np.array(Y)
# 如果特征集不是矩阵阵列或则标签集不是一维数组,都直接抛异常。
if self.X.ndim != 2 or self.Y.ndim != 1:
raise Exception("dimensions are wrong!")
# 如果标签的数量不竺于特征集的行数也直接抛异常
if self.X.shape[0] != self.Y.shape[0]:
raise Exception("input labels are not correct!")
def predict(self,X_pre):
# 这是要预测的点
pre = np.array(X_pre)
# 判断测试点的矩阵是不是和样本点的矩阵一样的,不是直接抛异常
if self.X.ndim != pre.ndim:
raise Exception("input dimensions are wrong!")
# 我们用rs数组来存储预测结果
rs = []
for p in pre:
# 用temp临时数组来存储预测点到所有样本点的欧几里德距离
temp = []
for a in self.X:
# 取出每一个样本点来与预测点计算欧几里德距离
# np.sqrt(((p - a) ** 2).sum(-1)) 算出距离,先求出每预测点到样本点的差值,再平方,再将所有平方后的值加在一起,最后对加起来的结果进行开方,得到欧几里德距离。并临时存储在temp数组里
temp.append(np.sqrt(((p - a) ** 2).sum(-1)))
temp = np.array(temp)
# 对所有距离进行排序,用np.argsort排序时,结果对识破距离的下标,而不是具体的值,因为我们并不关心具体的值,我们只要前k个点。用np.argsort排序完,取出前k个点的indices(就是下标)
neighbors_indices = np.argsort(temp)[:self.k]
# 通过前k个点的下标,取出相应的标签,然后用Counter进行统计(这个就是计票环节)
ss = np.take(self.Y,neighbors_indices)
# 我们开始计票,取出票数第一的标签值。
# e.g: Counter(ss) -> {2: 4, 1: 1} 表示标签值为2的得4示,标签为1的得1票
# most_common(1) -> [(2, 4)] , 所以most_common(1)[0][0]的值就是 2
found = Counter(ss).most_common(1)[0][0]
# 预测结果存储到rs数组中
rs.append(found)
return rs欧几里德距离的计算:

测试上面的kNN算法:
python
# 用鸢尾花数据集来验证我们上面写的算法
from sklearn.datasets import load_iris
# 使用train_test_split对数据集进行拆分,一部分用于训练,一部分用于测试验证
from sklearn.model_selection import train_test_split
# 1.生成一个kNN模型
myknn = MyKnn(5)
# 2.准备数据集:特征集X_train和标签集y_train
X_train,y_train = load_iris(return_X_y=True)
# 留出30%的数据集用于验证测试
X_train,X_test,y_train,y_test = train_test_split(X_train,y_train,test_size=0.3)
# 3.训练模型
myknn.fit(X_train,y_train)
# 4.预测,acc就是预测结果
acc = myknn.predict(X_test)
# 计算准确率
(acc == y_test).mean()acc == y_test 得到的结果是
python
array([ True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
False, True, True, True, True, True, True, True, True])True 是1,False是0,准确率就是:
正确的个数 / 总数 = 准确率