论文:How to Prompt LLMs for Text-to-SQL: A Study in Zero-shot, Single-domain, and Cross-domain Settings
⭐⭐⭐⭐
arXiv:2305.11853, NeurlPS 2023
Code: GitHub
一、论文速读
本文主要是在三种常见的 Text2SQL ICL settings 评估不同的 prompt construction strategies。
二、Text2SQL ICL settings
论文在下面三种 Text2SQL settings 下来做的评估:
- Zero-shot Text2SQL:输入一个 task instruction、一个 test question 以及相应的 DB,在没有任何 demonstrations 情况下让 LLM 直接推理出 SQL
- Single-domain Few-shot Text2SQL:ICL 的 demonstrations 是构造自与 test question 相同的 database。这个 setting 的目标是评估 LLM 在最小的域内训练数据下执行 Text2SQL 的能力。
- Cross-domain Few-shot Text2SQL:ICL 的 demonstrations 是构造自与 test question 的不同的 database 中。这个 setting 的目标是评估 LLM 通过 out-of-domain demonstrations 中来学习的泛化能力。
三、Prompt Construction
论文在每个 Text2SQL setting 中测试了不同的 prompt construction 的效果。
一个 prompt 中包含 Database Prompt 和 Demonstration Prompt。
3.1 Database Prompt
一个关系型 DB 包含 database schema 和 database content:
- database schema 由 table headers 和 tables 之间的 relationships 组成。
- database content 指的是存储在 tables 中的 data
3.1.1 Database Schema 的 prompt 结构
下图展示了之前的研究中使用的 database schema 的各种 prompt 结构:

同时为了保证文本的一致性,论文对 db schema 和 SQL 做了规范化:将 SQL 中除了数据库内容之外的所有单词转换为小写,并统一文本中的空格和换行符。如下图就是规范化前后的示例:

3.1.2 Database Content 的 prompt 结构
之前的研究内容也表示,了解数据库的内容示例可以提高模型的性能。
下图展示了 Database Content 部分的 prompt style:
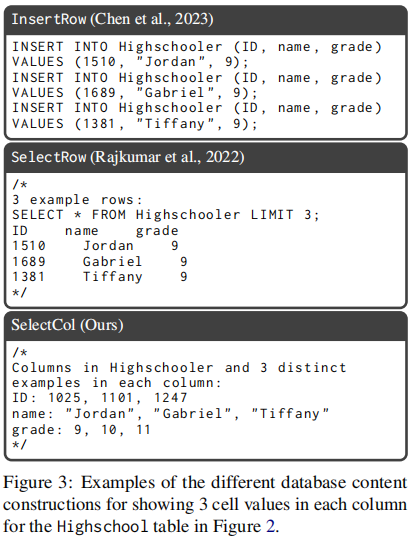
- InsertRow :通过
INSERT INTO语句显示每个 table 的几行数据 - SelectRow :显示
SELECT * FROM T LIMIT X的查询结果 - SelectCol:按照列式的格式显示多行数据
本文提出使用 SELECT DISTINCT [Column] FROM [Table] LIMIT R 去列出 R 行数据,从而避免重复。
3.2 Demonstration Prompt
在 few-shots settings 中,demonstrations 被放入 prompt text 来输入给 LLM。
在 single-domain few-shot setting 中,这里融入了一些 question-SQL 的 pairs 作为 demonstrations。
在 cross-domain few-shot setting 中,以往的研究都是:
- 要么 N 个 examples 都来自于一个相同的 db
- 要么 N 个 examples 的每一个来自于不同的 db
本文考虑了更泛用的场景:N 个 examples 是由 M 个 db 组成,每个 db 由 K 个 question-SQL pairs,由此 M × K = N M \times K = N M×K=N。
四、实验
本文在 Spider 数据集的 dev split 上实验,采用执行精度(EX)来评估 predicted SQL 和 gold SQL。
这里论文指出,在选择 few-shots 的 demonstrations 时,由于少数 db 包含长模式,这有可能导致 prompt token 数量超过 LLM 限制,所以在构造 CreateTable prompt 时,这里只使用 token 少于 1000 的 db。
具体的实验细节可以参考原论文。
五、实验结果
这一章介绍了在 zero-shot、single-domain 和 cross-domain 的三种 settings 下 Text2SQL 的经验发现。
5.1 zero-shot 的 Text2SQL
zero-shot setting 中重点关注于比较不同的 database prompt construction。下图展示了多种 database prompt 的 Codex 和 ChatGPT 的表现:
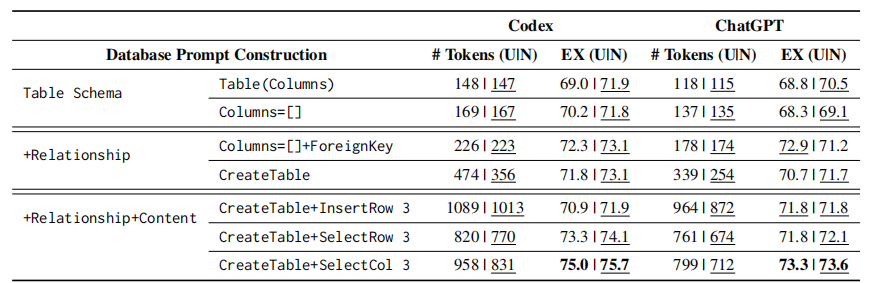
实验发现:
- 规范化后的 db schema 和 SQL 可以有更好的表现
- db table 的 relationship 和 content 是很重要的,有效地提高了 LLM 的表现
- Codex 在 zero-shot Text2SQL 任务上始终优于 ChatGPT
基于以上发现,论文建议将 Codex 与规范化后的 CreateTable-SelectCol prompt construction 结合起来使用,来实现 zero-shot 的 Text2SQL。
5.2 single-domain 的 Text2SQL
下图展示了在 Codex 和 ChatGPT 上做 single-domain Text2SQL 任务时,不同的 in-domain examples 的执行精确度的实验结果:
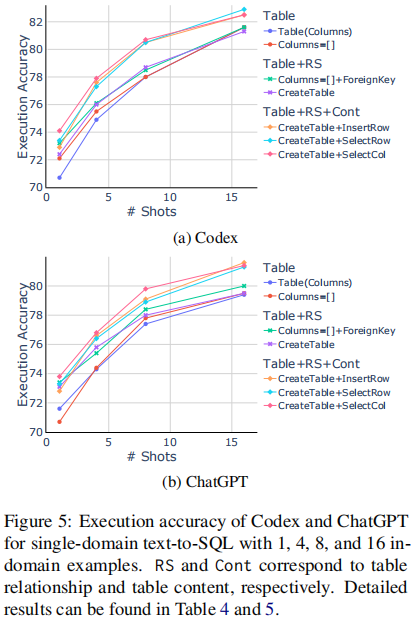
得出以下结论:
- in-domain 的 demonstrations 能有效提升 LLM 的表现,并随着示例数量的提高,LLM 的效果也在逐渐变好
- LLM 能够从 in-domain demonstrations 中快速学习到 table relationship,但难以从中学习到 table content 的知识,因此 table content 的 prompt 是重要的
5.3 cross-domain 的 Text2SQL
ICL 的 demonstrations 中使用了 M 的 demonstration databases,每一个包含 K 个 NLQ-SQL pairs。
下面这个热力图展示了 M 和 K 的个数对精确度的影响(横轴是 M,纵轴是 K,颜色越深,精确度越高):
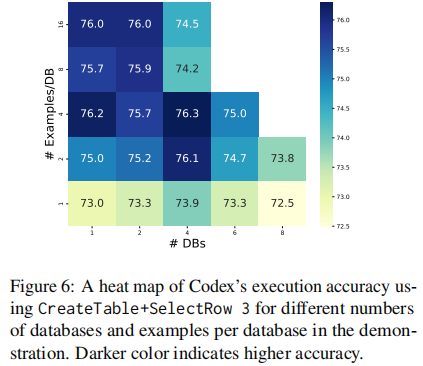
这里对实验的分析可以参考原论文。
总之,out-of-domain 的 demonstrations 增强了 LLM 在 Text2SQL 中的能力,但这些示例并没有提供特定于 DB 的知识,因此,仔细构建 Database Prompt 仍然至关重要,这也与在 zero-shot setting 中所做的观察是一致的。
六、总结
整的来说,论文在三种 Text2SQL ICL settings 中比较了各种 prompt constructions 的效果,为未来的研究提供了指导。