文章目录
- 大模型训练的艺术:从预训练到增强学习的四阶段之旅
-
- [1. 预训练阶段(Pretraining)](#1. 预训练阶段(Pretraining))
- [2. 监督微调阶段(Supervised Finetuning, SFT)](#2. 监督微调阶段(Supervised Finetuning, SFT))
- [3. 奖励模型训练阶段(Reward Modeling)](#3. 奖励模型训练阶段(Reward Modeling))
- [4. 增强学习微调阶段(Reinforcement Learning, RL)](#4. 增强学习微调阶段(Reinforcement Learning, RL))
大模型训练的艺术:从预训练到增强学习的四阶段之旅
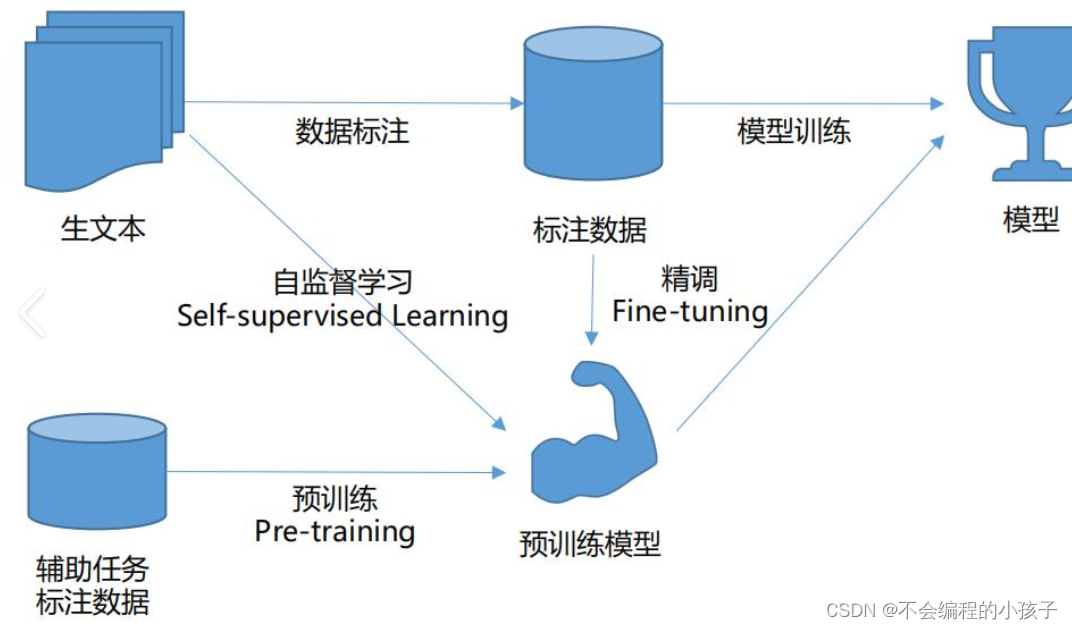
在当今人工智能领域,大型模型以其卓越的性能和广泛的应用前景,成为推动技术进步的重要力量。训练这样复杂的模型并非一日之功,而是需历经精心设计的四个阶段:预训练、监督微调(SFT)、奖励模型训练、以及增强学习微调(RL)。本文将深入探索这四大阶段,揭示每一步骤背后的技术逻辑和实施细节。
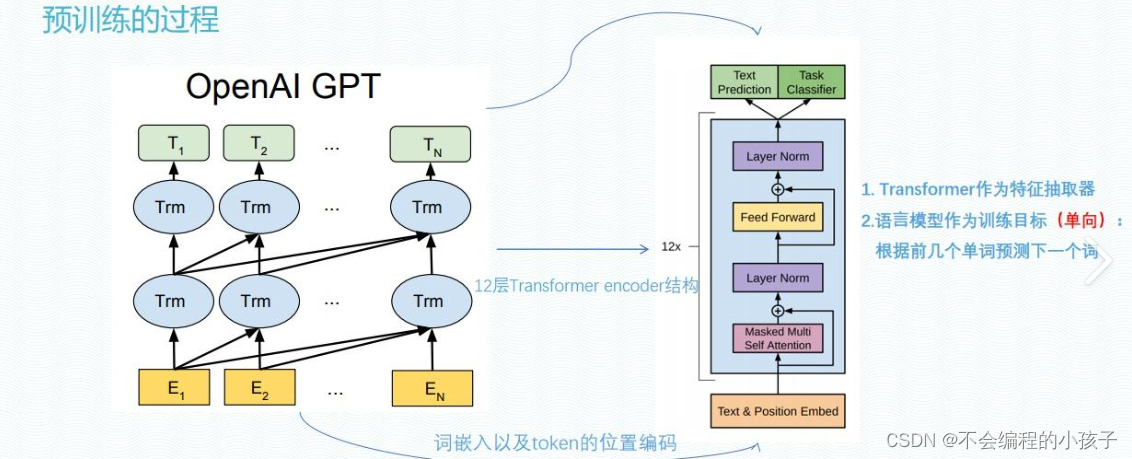
1. 预训练阶段(Pretraining)
核心目标: 构建一个对广泛数据具有普遍理解的基础模型。预训练阶段通过让模型在大规模未标注数据集上学习,来捕获语言、图像或其他类型数据的统计规律和潜在结构。这一步骤通常使用自监督学习策略,如掩码语言模型(如BERT)或对比学习(如SimCLR)。
实施细节: 模型会尝试预测被遮盖的部分或在图像中找出相似性,从而在无监督环境下学习数据的内在特征。此阶段需要大量计算资源,并且模型规模往往非常庞大,以便能更好地泛化至各种任务。
应用场景: 预训练模型如BERT、RoBERTa在自然语言处理领域被广泛应用,为后续的微调和具体任务适应奠定了坚实的基础。
2. 监督微调阶段(Supervised Finetuning, SFT)
核心目标: 将预训练得到的通用模型适应特定任务。通过在特定领域的带标签数据集上进行微调,模型学习特定任务的输出模式,比如情感分析、命名实体识别或图像分类。
实施细节: 在预训练模型的基础上,添加额外的输出层并使用监督学习策略,调整模型参数以最小化预测错误。这一阶段的训练数据相对较少,但针对性极强,使模型在特定任务上表现更佳。
应用场景: 例如,针对医疗记录的情感分析,会在预训练的语言模型基础上,使用标注了情感的医疗文本进行微调。
3. 奖励模型训练阶段(Reward Modeling)
核心目标: 为模型的行为制定评价标准。在某些复杂或开放式的任务中,简单的正确/错误标签不足以指导模型学习。奖励模型通过给模型的输出分配分数(奖励),引导其产生更高质量的输出。
实施细节: 通过人工或自动化方法,为模型的不同行为或生成内容分配奖励分数,建立奖励模型。这要求设计合理的奖励函数,确保模型追求的目标与实际任务目标一致。
应用场景: 在生成对话系统中,奖励模型可以用来评价对话的连贯性、信息丰富度和用户满意度,促使模型产生更加自然和有用的回复。
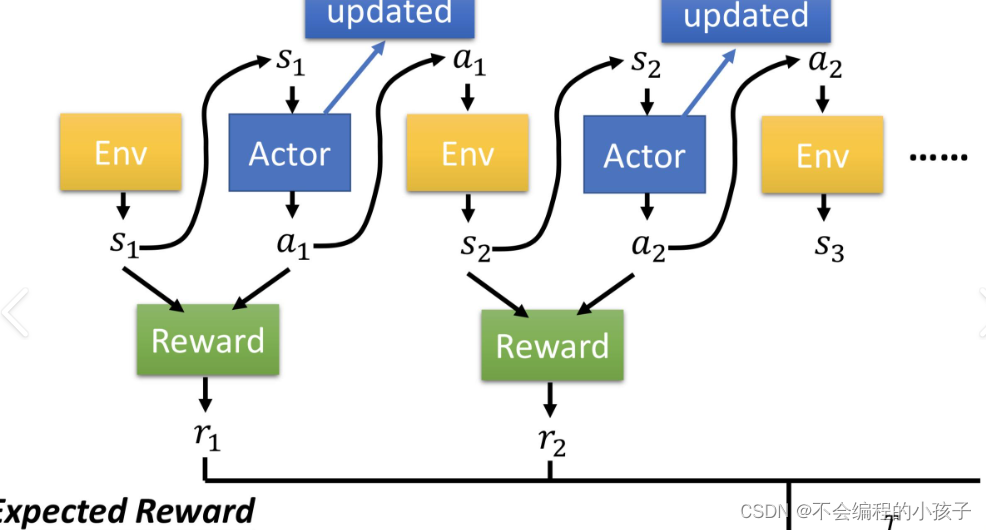
4. 增强学习微调阶段(Reinforcement Learning, RL)
核心目标: 通过与环境的互动,优化模型的决策策略。增强学习阶段利用奖励信号,使模型在特定环境中通过试错学习,不断优化其行为策略,以最大化长期奖励。
实施细节: 模型在环境中采取行动,根据奖励模型给出的反馈调整策略。这通常涉及策略梯度方法等技术,模型通过多次迭代逐渐学会如何做出最优选择。
应用场景: 在游戏AI、自动机器人导航等场景,增强学习能让模型在动态环境中自主学习最佳策略,实现高效解决问题的能力。
结语
这四个阶段构成了一个系统化的训练流程,从广泛而基础的预训练,到针对任务的精炼微调,再到高级的策略优化,每一步都是为了让模型更加智能、高效地服务于特定应用场景。随着技术的不断演进,这一流程也在持续优化,推动着大模型向更广泛、更深层次的应用领域迈进。