例题一

解法(贪⼼):
贪⼼策略:
分情况讨论:
a. 遇到 5 元钱,直接收下;
b. 遇到 10 元钱,找零 5 元钱之后,收下;
c. 遇到 20 元钱:
i. 先尝试凑 10 + 5 的组合;
ii. 如果凑不出来,拼凑 5 + 5 + 5 的组合;

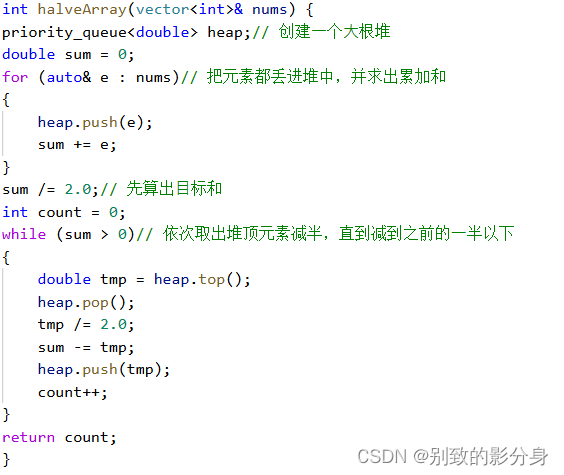
例题二

解法(贪⼼):
贪⼼策略:
a. 每次挑选出「当前」数组中「最⼤」的数,然后「减半」;
b. 直到数组和减少到⾄少⼀半为⽌。
为了「快速」挑选出数组中最⼤的数,我们可以利⽤「堆」这个数据结构。
例题三

3. 解法(贪⼼):
可以先优化:
将所有的数字当成字符串处理,那么两个数字之间的拼接操作以及⽐较操作就会很⽅便。
贪⼼策略:
按照题⽬的要求,重新定义⼀个新的排序规则,然后排序即可。
排序规则:
a. 「A 拼接 B」 ⼤于 「B 拼接 A」,那么 A 在前,B 在后;
b. 「A 拼接 B」 等于 「B 拼接 A」,那么 A B 的顺序⽆所谓;
c. 「A 拼接 B」 ⼩于 「B 拼接 A」,那么 B 在前,A 在后;

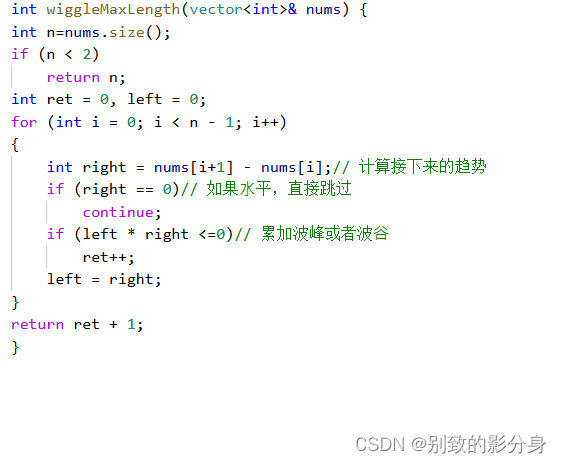
例题四

解法(贪⼼):
贪⼼策略:
对于某⼀个位置来说:
◦ 如果接下来呈现上升趋势的话,我们让其上升到波峰的位置;
◦ 如果接下来呈现下降趋势的话,我们让其下降到波⾕的位置。
因此,如果把整个数组放在「折线图」中,我们统计出所有的波峰以及波⾕的个数即可。
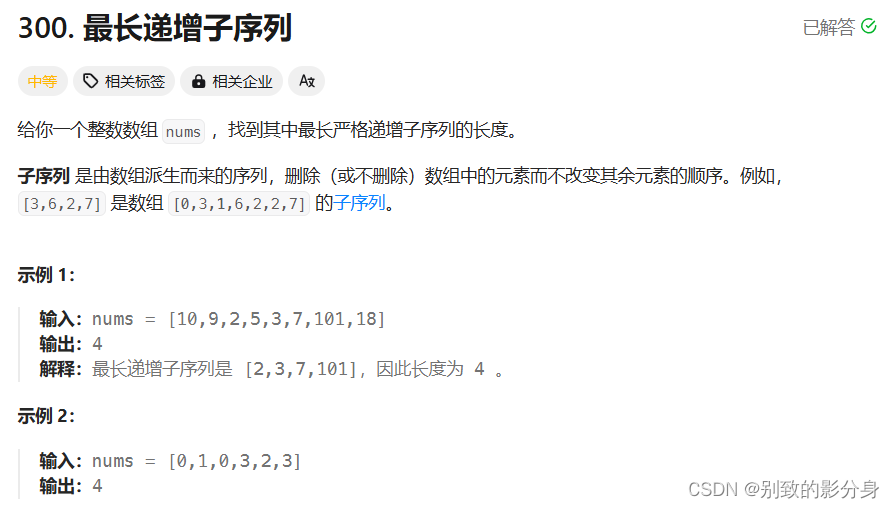
例题五
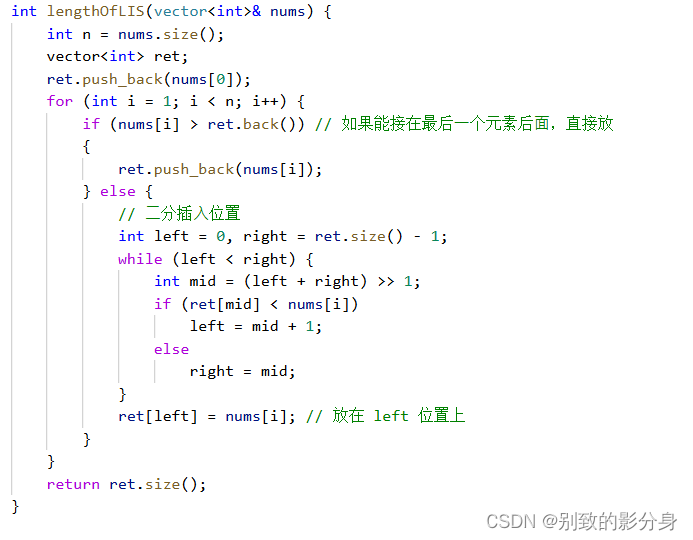
解法(贪⼼):
贪⼼策略:
我们在考虑最⻓递增⼦序列的⻓度的时候,其实并不关⼼这个序列⻓什么样⼦,我们只是关⼼最后
⼀个元素是谁。这样新来⼀个元素之后,我们就可以判断是否可以拼接到它的后⾯。 因此,我们可以创建⼀个数组,统计⻓度为 x 的递增⼦序列中,最后⼀个元素是谁。为了尽可能的让这个序列更⻓,我们仅需统计⻓度为 x 的所有递增序列中最后⼀个元素的「最⼩值」。统计的过程中发现,数组中的数呈现「递增」趋势,因此可以使⽤「⼆分」来查找插⼊位置。
例题六

解法(贪⼼):
贪⼼策略:
最⻓递增⼦序列的简化版。不⽤⼀个数组存数据,仅需两个变量即可。也不⽤⼆分插⼊位置,仅需两次⽐较就可以找到插⼊位置。

例题七

解法(贪⼼):
贪⼼策略:
找到以某个位置为起点的最⻓连续递增序列之后(设这个序列的末尾为 j 位置),接下来直接以 j + 1 的位置为起点寻找下⼀个最⻓连续递增序列。
