Meta Llama 3 前馈层
flyfish
图片来自论文 http://arxiv.org/pdf/2304.13712
因为树根是Transformer,所以这里会将 Llama 3 与Transformer比较下
Transformer的前馈层
在Transformer模型中,每个编码器和解码器层中都包含一个前馈神经网络(Feed-Forward Neural Network, FFN)。前馈神经网络的作用是对经过自注意力机制处理后的输出进行进一步的非线性变换和特征提取。
前馈神经网络的结构
每个前馈神经网络由两个线性变换和一个激活函数组成。具体结构如下:
FFN ( x ) = Linear 2 ( ReLU ( Linear 1 ( x ) ) ) \text{FFN}(x) = \text{Linear}_2(\text{ReLU}(\text{Linear}_1(x))) FFN(x)=Linear2(ReLU(Linear1(x)))
前馈神经网络的激活函数
Transformer中的前馈神经网络使用的激活函数是ReLU(Rectified Linear Unit)。ReLU的定义如下: ReLU ( x ) = max ( 0 , x ) \text{ReLU}(x) = \max(0, x) ReLU(x)=max(0,x)
前馈神经网络的优缺点
优点
非线性特征提取:
ReLU激活函数引入非线性,使得前馈神经网络能够提取和表示输入数据中的复杂特征。
计算效率:
ReLU激活函数的计算非常简单,只需比较输入是否大于零,因此计算效率很高。
缓解梯度消失问题:
相较于传统的激活函数(如Sigmoid或Tanh),ReLU可以缓解梯度消失问题,特别是在深层神经网络中。
缺点
ReLU的死亡问题(Dead ReLU Problem):
当输入为负时,ReLU的输出恒为零。如果大量的神经元在训练过程中输出恒为零,它们将不会对模型的学习做出贡献。
参数选择:
前馈神经网络的隐藏层维度 d_ff 的选择需要经验和实验调整,过大或过小都会影响模型的性能和计算效率。
代码实现
py
import torch
import torch.nn as nn
import torch.nn.functional as F
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(FeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(d_ff, d_model)
self.norm = nn.LayerNorm(d_model)
def forward(self, x):
# 前馈神经网络的计算过程
out = F.relu(self.linear1(x))
out = self.linear2(self.dropout(out))
# 残差连接和层归一化
out = self.norm(x + out)
return out
# 定义模型参数
d_model = 512
d_ff = 2048
dropout = 0.1
# 创建前馈神经网络层
ffn = FeedForward(d_model, d_ff, dropout)
# 创建示例输入张量 (batch_size, seq_length, d_model)
batch_size = 32
seq_length = 10
input_tensor = torch.randn(batch_size, seq_length, d_model)
# 执行前向传播
output = ffn(input_tensor)
print("Output shape:", output.shape)输出
Output shape: torch.Size([32, 10, 512])self.linear1:第一个线性层,将输入从 d_model 维度变换到 d_ff 维度。
self.dropout:Dropout 层,用于在训练过程中随机丢弃一些神经元,防止过拟合。
self.linear2:第二个线性层,将隐藏层的输出从 d_ff 维度变换回 d_model 维度。
self.norm:层归一化,用于规范化输入,增加模型的稳定性。
LLama3的前馈神经网络实现
源码是
py
class FeedForward(nn.Module):
def __init__(
self,
dim: int,
hidden_dim: int,
multiple_of: int,
ffn_dim_multiplier: Optional[float],
):
super().__init__()
hidden_dim = int(2 * hidden_dim / 3)
# custom dim factor multiplier
if ffn_dim_multiplier is not None:
hidden_dim = int(ffn_dim_multiplier * hidden_dim)
hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)
self.w1 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
self.w2 = RowParallelLinear(
hidden_dim, dim, bias=False, input_is_parallel=True, init_method=lambda x: x
)
self.w3 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))改造
不使用FairScale
py
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import Optional
class FeedForward(nn.Module):
def __init__(
self,
dim: int,
hidden_dim: int,
multiple_of: int,
ffn_dim_multiplier: Optional[float] = None,
):
super().__init__()
hidden_dim = int(2 * hidden_dim / 3)
# custom dim factor multiplier
if ffn_dim_multiplier is not None:
hidden_dim = int(ffn_dim_multiplier * hidden_dim)
hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)
self.w1 = nn.Linear(dim, hidden_dim, bias=False)
self.w2 = nn.Linear(hidden_dim, dim, bias=False)
self.w3 = nn.Linear(dim, hidden_dim, bias=False)
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))
# 示例用法
dim = 512
hidden_dim = 2048
multiple_of = 64
ffn_dim_multiplier = 1.0
ffn = FeedForward(dim, hidden_dim, multiple_of, ffn_dim_multiplier)
# 创建示例输入张量 (batch_size, seq_length, dim)
batch_size = 32
seq_length = 10
input_tensor = torch.randn(batch_size, seq_length, dim)
# 执行前向传播
output = ffn(input_tensor)
print("Output shape:", output.shape)输出
Output shape: torch.Size([32, 10, 512])类定义:
FeedForward 类继承自 nn.Module,这是PyTorch中的基本模块类。
构造函数:
init 方法初始化前馈神经网络层的各个参数:
dim:输入和输出的特征维度。
hidden_dim:隐藏层的维度。
multiple_of:隐藏层维度的倍数,用于确保隐藏层的维度是某个值的整数倍。
ffn_dim_multiplier:一个可选的乘数,用于调整隐藏层的维度。
隐藏层维度计算:
hidden_dim 初始设定为 2/3 的原始隐藏层维度。
如果提供了 ffn_dim_multiplier,则乘以该值调整 hidden_dim。
使用 multiple_of 来确保 hidden_dim 是其整数倍
py
hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)线性层定义:
self.w1、self.w2 和 self.w3 都是 nn.Linear 层,分别用于不同的线性变换:
self.w1:将输入从 dim 维度映射到 hidden_dim 维度。
self.w2:将中间层从 hidden_dim 维度映射回 dim 维度。
self.w3:将输入从 dim 维度再次映射到 hidden_dim 维度。
前向传播:
在 forward 方法中,定义了前向传播的计算过程
return self.w2(F.silu(self.w1(x)) * self.w3(x))self.w1(x):对输入 x 进行第一次线性变换。
F.silu(self.w1(x)):对线性变换的结果应用SiLU激活函数。
self.w3(x):对输入 x 进行第二次线性变换。
F.silu(self.w1(x)) * self.w3(x):将激活后的结果与 self.w3(x) 的结果相乘。
self.w2(...):将乘积结果通过 self.w2 线性变换映射回原始维度 dim。
LLama3和Transformer中的FFN的比较

相同点
基本结构:
都包含两层线性变换和一个激活函数。
都使用残差连接和归一化来增强模型的稳定性。
激活函数:
虽然实现有所不同,但都通过激活函数(如ReLU或SiLU)引入非线性。
不同点
激活函数:
Transformer使用ReLU激活函数,而LLama3使用SiLU(Swish Linear Unit),定义为:
SiLU ( x ) = x ⋅ sigmoid ( x ) \text{SiLU}(x) = x \cdot \text{sigmoid}(x) SiLU(x)=x⋅sigmoid(x)
线性层组合:
Transformer的FFN是两个顺序的线性层:
out = self.linear2(F.relu(self.linear1(x)))LLama3的FFN则是两个线性层的组合,包含一个乘积操作:
return self.w2(F.silu(self.w1(x)) * self.w3(x))维度调整:
LLama3中加入了一个可选的维度调整因子和倍数约束,以确保隐藏层维度符合某些特定的需求。
ReLU:
简单且高效,适合大多数应用。
但在负输入时,输出恒为零,可能导致部分神经元在训练过程中"死亡"。
SiLU:
平滑的非线性转换,梯度在输入的正负范围内都能够有效传播。
相比ReLU,更能捕获输入的细微变化,但计算复杂度略高。
ReLU和SiLU 可视化比较
py
import matplotlib.pyplot as plt
import numpy as np
# 定义ReLU和SiLU函数
def relu(x):
return np.maximum(0, x)
def silu(x):
return x / (1 + np.exp(-x))
# 创建输入数据
x = np.linspace(-10, 10, 400)
# 计算ReLU和SiLU的输出
y_relu = relu(x)
y_silu = silu(x)
# 绘图
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(x, y_relu, label='ReLU')
plt.title('ReLU Activation Function')
plt.xlabel('Input')
plt.ylabel('Output')
plt.legend()
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(x, y_silu, label='SiLU', color='orange')
plt.title('SiLU Activation Function')
plt.xlabel('Input')
plt.ylabel('Output')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()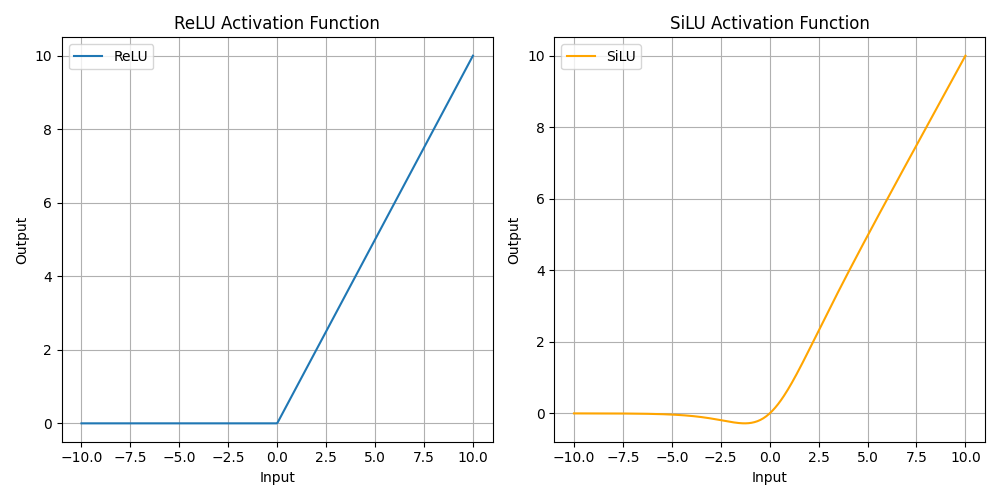
官方的llama 3 的代码使用FairScale ,上面的代码为了分析流程,没有使用FairScale。
FairScale 简单介绍下
FairScale是一个由Facebook AI Research(FAIR)团队开发的用于PyTorch的开源库,旨在简化大规模深度学习模型的训练和推理。FairScale提供了多种优化工具和模块,帮助研究人员和工程师更高效地进行分布式训练和模型并行化。
FairScale的主要功能
分布式数据并行(Distributed Data Parallel, DDP):
提供增强的分布式数据并行功能,相比于PyTorch自带的DDP模块,FairScale的DDP具有更高的灵活性和性能优化。
分布式模型并行(Distributed Model Parallel, DMP):
允许将模型的不同部分分布到多个设备上,从而使得超大规模模型的训练成为可能。
梯度检查点(Gradient Checkpointing):
通过在反向传播过程中保存和重用部分计算结果,减少显存占用,从而训练更大规模的模型。
优化器状态并行(Optimizer State Sharding):
将优化器的状态分片到多个设备上,从而降低单个设备的显存需求。
张量并行(Tensor Parallelism):
支持在多个设备间并行执行张量计算,进一步提升大规模模型的训练效率