智能手机如何仅凭拍摄的照片就能识别物体?社交媒体网站又是如何自动标记照片中的人物?这些功能背后,是人工智能驱动的图像识别和分类技术。
图像识别和分类技术是人工智能领域中一些最令人瞩目的成就。但计算机是如何学会检测和分类图像的呢?本文将介绍计算机对图像进行解释和检测的一般方法,并探讨一些用于图像分类的流行技术。
像素级与基于对象的分类
图像分类技术主要可以分为两类: 基于像素的分类 和基于对象的分类。
像素是图像的基本单位,像素分析是图像分类的主要方式。 然而,分类算法可以仅使用单个像素内的光谱信息来对图像进行分类,也可以检查空间信息(附近的像素)以及光谱信息。 基于像素的分类方法仅利用光谱信息(像素的强度),而基于对象的分类方法则考虑像素光谱信息和空间信息。
有多种不同的分类技术用于基于像素的分类。 这些包括最小均值距离、最大似然度和最小马哈拉诺比斯距离。 这些方法要求已知类别的均值和方差,并且它们都通过检查类别均值和目标像素之间的"距离"来进行操作。
基于像素的分类方法受到以下事实的限制:它们不能使用来自其他附近像素的信息。 相反,基于对象的分类方法可以包括其他像素,因此它们也使用空间信息来对项目进行分类。 请注意,"对象"仅指像素的连续区域,而不指该像素区域内是否存在目标对象。
预处理图像数据以进行目标检测
最新且可靠的图像分类系统主要使用对象级分类方案,对于这些方法,必须以特定方式准备图像数据。 需要选择并预处理对象/区域。
在对图像以及该图像内的对象/区域进行分类之前,必须由计算机解释包含该图像的数据。图像需要进行预处理并准备好输入分类算法,这是通过对象检测完成的。这是准备数据和图像以训练机器学习分类器的关键部分。
物体检测是通过 多种方法和技术。 首先,是否存在多个感兴趣对象或单个感兴趣对象都会影响图像预处理的处理方式。 如果只有一个感兴趣的对象,则对图像进行图像定位。 组成图像的像素具有由计算机解释并用于显示正确的颜色和色调的数值。 在感兴趣的对象周围绘制一个称为边界框的对象,这有助于计算机了解图像的哪些部分是重要的以及哪些像素值定义了该对象。 如果图像中有多个感兴趣的对象,则使用一种称为对象检测的技术将这些边界框应用于图像中的所有对象。

另一种预处理方法是图像分割。 图像分割功能通过根据相似特征将整个图像划分为多个片段。 与图像的其他区域相比,图像的不同区域将具有相似的像素值,因此这些像素被分组到与图像内相关对象的形状和边界相对应的图像掩模中。 图像分割帮助计算机隔离图像的特征,这将有助于它对对象进行分类,就像边界框所做的那样,但它们提供了更准确的像素级标签。
完成对象检测或图像分割后,将标签应用于相关区域。 这些标签与构成对象的像素值一起被输入到机器学习算法中,该算法将学习与不同标签相关的模式。
机器学习算法
一旦数据准备好并标记,数据就会被输入到机器学习算法中,该算法对数据进行训练。 我们将介绍一些最常见的机器学习类型 图像分类算法 联络一位教师
K最近邻居
K 最近邻是一种分类算法,它检查最接近的训练示例并查看它们的标签以确定给定测试示例的最可能的标签。 当使用 KNN 进行图像分类时,训练图像的特征向量和标签会被存储,并且在测试期间仅将特征向量传递到算法中。 然后比较训练和测试特征向量的相似性。
基于 KNN 的分类算法非常简单,并且可以轻松处理多个类别。 然而,KNN 平等地基于所有特征计算相似度。 这意味着当提供的图像中只有一部分特征对于图像的分类很重要时,很容易出现错误分类。
支持向量机
支持向量机是一种分类方法,它将点放置在空间中,然后在点之间绘制分割线,根据点落在分割平面的哪一侧将对象放置在不同的类中。 支持向量机能够通过使用称为核技巧的技术进行非线性分类。 虽然 SVM 分类器通常非常准确,但 SVM 分类器的一个重大缺点是它们往往受到大小和速度的限制,随着大小的增加,速度会受到影响。
多层感知器(神经网络)
多层感知器,也称为神经网络模型,是受人脑启发的机器学习算法。 多层感知器由相互连接在一起的各个层组成,就像人脑中的神经元连接在一起一样。 神经网络对输入特征与数据类别的关系做出假设,并且这些假设在训练过程中进行调整。 像多层感知器这样的简单神经网络模型能够学习非线性关系,因此,它们比其他模型更准确。 然而,MLP 模型存在一些值得注意的问题,例如存在非凸损失函数。
深度学习算法 (CNN)
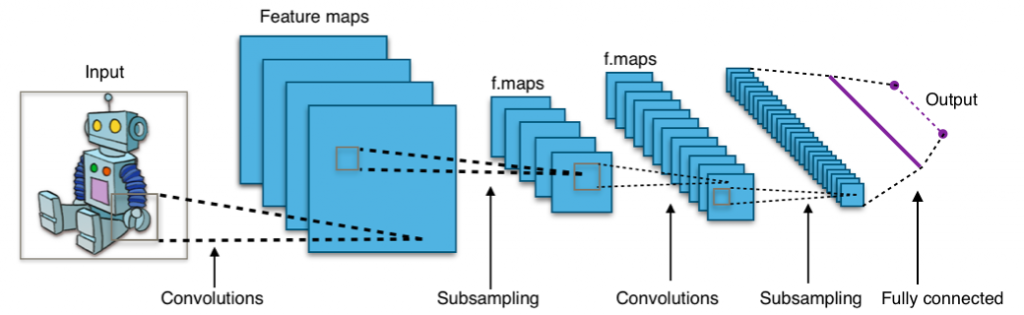
近年来最常用的图像分类算法是卷积神经网络(CNN)。 CNN 是神经网络的定制版本,它将多层神经网络与专用层相结合,能够提取与对象分类最重要且相关的特征。 CNN 可以自动发现、生成和学习图像特征。这大大减少了手动标记和分割图像以准备机器学习算法的需要。它们还比 MLP 网络有优势,因为它们可以处理非凸损失函数。
卷积神经网络因其创建"卷积"而得名。 CNN 的工作原理是采用过滤器并将其滑过图像。 您可以将其视为通过可移动的窗口查看景观的各个部分,只关注在任何时间通过窗口可以看到的特征。 过滤器包含与像素本身的值相乘的数值。 结果是一个新的帧或矩阵,其中充满了代表原始图像的数字。 对于选定数量的滤波器重复此过程,然后将帧连接在一起形成比原始图像稍小且不太复杂的新图像。 一种称为池化的技术用于仅选择图像中最重要的值,目标是卷积层最终提取图像中最显着的部分,这将有助于神经网络识别图像中的对象。
卷积神经网络 由两个不同的部分组成。 卷积层提取图像的特征并将其转换为神经网络层可以解释和学习的格式。 早期的卷积层负责提取图像的最基本元素,例如简单的线条和边界。 中间的卷积层开始捕获更复杂的形状,例如简单的曲线和角。 后来的更深的卷积层提取图像的高级特征,这些特征被传递到 CNN 的神经网络部分,也是分类器学习的内容。