Redis Cluster集群
-
- [Redis Cluster](#Redis Cluster)
- Redis性能管理
Redis Cluster
Redis 分布式扩展之 Redis Cluster 方案
主从切换的过程中会丢失数据,因为只有一个 master,只能单点写,没有解决水平扩容的问题。而且每个节点都保存了所有数据,一个是内存的占用率较高,另外就是如果进行数据恢复时,非常慢。而且数据量过大对数据 IO 操作的性能也会有影响。
所以我们同样也有对 Redis 数据分片的需求,所谓分片就是把一份大数据拆分成多份小数据,在 3.0 之前,我们只能通过构建多个 redis 主从节点集群,把不同业务数据拆分到不冉的集群中,这种方式在业务层需要有大量的代码来完成数据分片、路由等工作,导致维护成本高、增加、移除节点比较繁琐。
Redis3.0 之后引入了 Redis Cluster 集群方案,它用来解决分布式扩展的需求,同时也实现了高可用机制。
功能
- 读和写可以负载均衡
- 自动故障转移
- 突破了单机存储限制,方便扩展
数据如何进行存储
- 槽(slot)
使用hash算法,16384(2^14)个hash槽,每个hash槽有512字节
redis 集群架构
- redis的集群模式中可以实现多个节点同时提供写操作,redis集群模式采用无中心结构,节点之间互相连接从而知道整个集群状态。
- redis 集群采用了多主多从,按照一定的规则进行分片,每个节点都保存数据,将数据分别存储,一定程度上解决了哨兵模式下单机存储有限的问题。
- 下面我这里采用的是三主三从的架构模式,由于硬件问题,主从都配置到了同一台服务器上,启动6个redis实例。
开启群集功能
bash
#其他5个文件夹的配置文件以此类推修改,注意6个端口都要不一样。
vim redis.conf
#bind 127.0.0.1 #69行,注释掉bind 项,默认监听所有网卡
protected-mode no #88行,修改,关闭保护模式
port 6379 #92行,修改,redis监听端口,
daemonize yes #136行,开启守护进程,以独立进程启动
cluster-enabled yes #832行,取消注释,开启群集功能
cluster-config-file nodes-6379.conf #840行,取消注释,群集名称文件设置
cluster-node-timeout 15000 #846行,取消注释群集超时时间设置
appendonly yes #699行,修改,开启AOF持久化
cd /usr/local/redis/bin
mkdir -p redis-cluster/redis600{1..6}
for i in {1..6}
do
cp -i redis.conf redis-cluster/redis600$i
cp -i redis-cli redis-server redis-cluster/redis600$i
sed -i "s/6379/600$i/" redis-cluster/redis600$i/redis.conf
done启动redis节点
bash
for d in {1..6}
do
cd /usr/local/redis/bin/redis-cluster/redis600$d
redis-server redis.conf
done
ps -ef | grep redis
启动集群
bash
redis-cli \
#-a redis123 起名
--cluster create \
127.0.0.1:6001 127.0.0.1:6002 127.0.0.1:6003 127.0.0.1:6004 127.0.0.1:6005 127.0.0.1:6006 \ #随机分组
--cluster-replicas 1
#IP1:6001 IP1:6004 IP2:6002 IP2:6005 IP3:6003 IP3:6006 六个实例分为三组,每组一主一从,前面的做主节点,后面的做从节点。下面交互的时候 需要输入 yes才可以创建。
--replicas 1 表示每个主节点有1个从节点。
测试群集
bash
redis-cli -p 6001 -c #加-c参数,节点之间就可以互相跳转
127.0.0.1:6001> cluster slots #查看节点的哈希槽编号范围
bash
set name zhangli
bash
cluster keyslot name #查看name键的槽编号
bash
127.0.0.1:6002> quit
redis-cli -p 6005 -c
127.0.0.1:6005> keys * #对应的slave节点也有这条数据,但是别的节点没有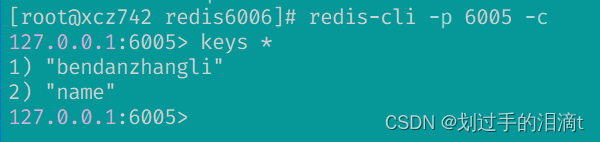
集群伸缩
作为分片集群,其中有一个很重要的功能,就是支持集群伸缩。比如平时非活动期间访问量不会很大,使用三主三从就可以,618、双十一期间,大促活动时候,这种访问量很高的,这个时候,就需要我们对Redis集群进行扩容了,当活动过后,流量下来会,我们又要进行缩容。那么分片集群怎么做到集群伸缩的。
cluster meet
CLUSTER MEET 是 Redis Cluster 内置的命令,可以直接在任何一个节点上执行。它需要指定要加入集群的新节点的 IP 地址和端口号。
【注意】若 cluster meet 加入已存在于其它集群的节点,会致使集群合并,造成数据错乱!建议使用redis-cli add-node
bash
#Redis Cluster是Redis的集群模式,它通过分片和复制来提供高可用性和可扩展性。
#下面是一些常用的Redis Cluster命令:
CLUSTER MEET <ip> <port>:将当前节点与指定的节点进行集群连接。
CLUSTER ADDSLOTS <slot> [<slot> ...]:将指定的槽位分配给当前节点。
CLUSTER DELSLOTS <slot> [<slot> ...]:从当前节点中移除指定的槽位。
CLUSTER REPLICATE <node_id>:将当前节点设置为指定节点的从节点。
CLUSTER INFO:查看集群的整体信息,包括节点数量、槽位分布、复制信息等。
CLUSTER NODES:列出所有的集群节点及其状态、角色、地址等详细信息。
CLUSTER SLOTS:显示集群中的槽位信息,以及这些槽位所属的主节点和从节点。
CLUSTER KEYSLOT <key>:根据键名计算该键所属的槽位。
CLUSTER COUNTKEYSINSLOT <slot>:统计指定槽位中的键数量。
CLUSTER FORGET <node_id>:从集群中移除指定的节点。
CLUSTER FLUSHSLOTS:清空当前节点的所有槽位信息。
CLUSTER REPLICATE <node_id>:将当前节点设置为指定节点的从节点。
CLUSTER SAVECONFIG:将集群的配置保存到硬盘上的redis.conf文件中。redis-cli --cluster 和 cluster meet区别
- 当您希望将一个新节点添加到已经运行的 Redis 集群时,可以使用CLUSTER MEET 命令来告诉现 有集群关于这个新节点。
- 而对于初始化一个全新的 Redis集群,首先需要选择其中一个作为种子(seed)或引导 (bootstrap)节点,并使用 --cluster add-node 选项来添加其他所有主从节点。
提供了很多操作集群的命令,我们可以通过help方式查看:
bash
redis-cli --cluster help
比如,添加节点命令:
向集群中添加一个新的master节点,并向其中存储 num=10 .
步骤:
①:启动一个新的Redis实例,地址为192.168.99.121:6010;
②:添加192.168.99.121:6010到之前的集群中,并作为一个master节点;
③:给192.168.99.121:6010节点分片插槽,是的num这个key可以存放到192.168.99.121:6010实例中。
对需求进行分析,我们可以知道,这里其实需要两个新的功能:
①:添加一个节点到集群中;
②:将部分插槽分配到新的master节点上
bash
127.0.0.1:6001> set num 100创建新的Redis实例
redis6010

添加新的节点到redis集群中
bash
redis-cli --cluster add-node 192.168.99.121:6010 192.168.99.121:6001通过命令查看集群状态。命令:
bash
redis-cli -h 192.168.99.121 -p 6001 cluster nodes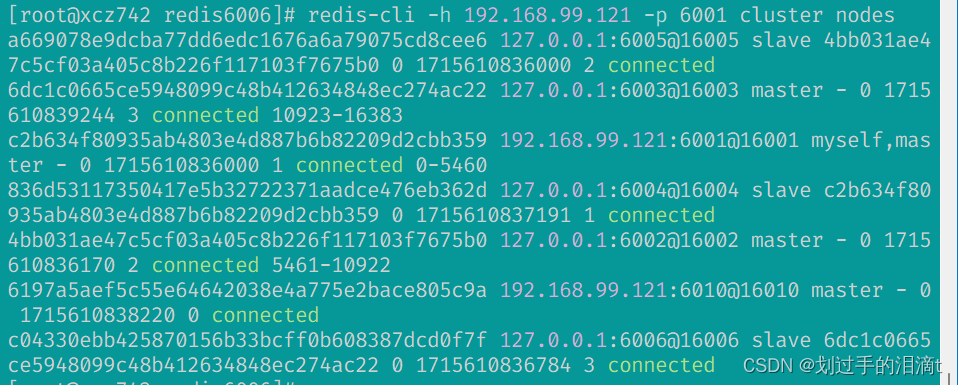
从上图中,我们可以看到,新加入的6001节点,是以master身份加入到了集群中,但是,没有插槽。如果没有插槽的话,也就意味着没有任何数据可以存储到6010上。
那么接下来,我们就来进行插槽的转移。
转移插槽
我们要将key为num的数据存储在6001,这个新插入节点上,因此,需要先看看key==num对应的插槽是多少。可以执行CLUSTER KEYSLOT
命令:
bash
CLUSTER KEYSLOT num
那么我们可以将0~3000的插槽从1节点转移到10这个新节点上。
bash
redis-cli --cluster reshard 192.168.99.121:6010依次输入
bash
#插槽数量
3000
#6010的node id
6197a5aef5c55e64642038e4a775e2bace805c9a
#6001的node id
c2b634f80935ab4803e4d887b6b82209d2cbb359
done
yes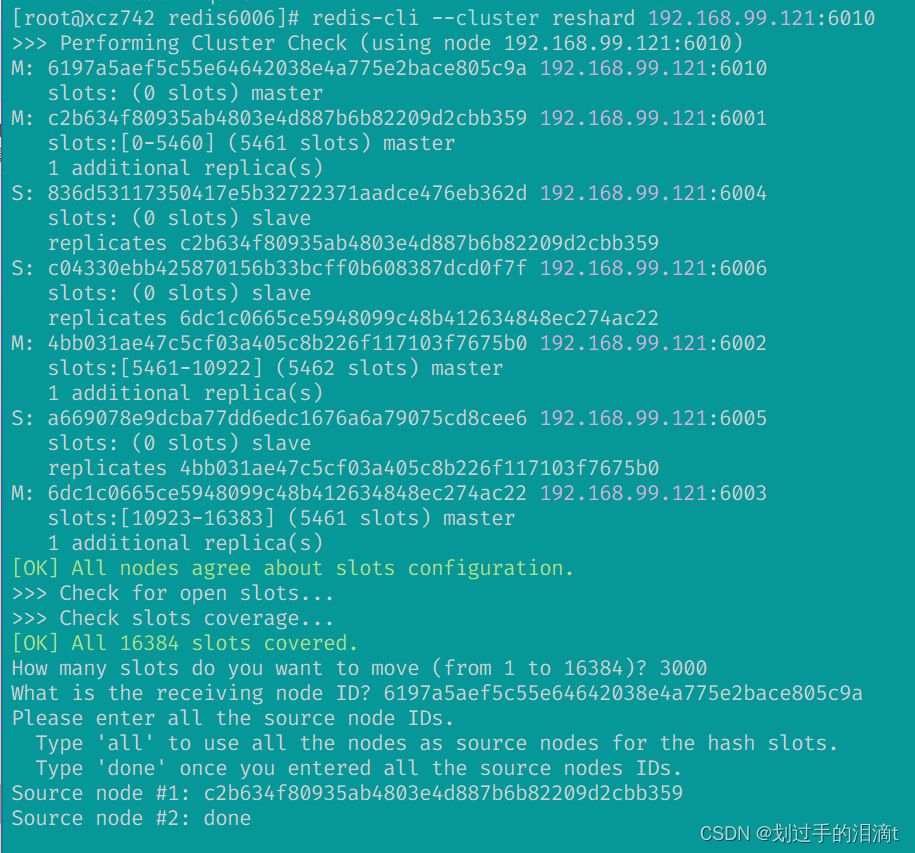
验证是否转移插槽成功
bash
127.0.0.1:6001> get num
-> Redirected to slot [2765] located at 192.168.99.121:6010
"100"脚本对redis集群扩容缩容,脚本参数为redis集群,固定从6001移动2000个哈希槽到新实例上
bash
#!/bin/bash
# 定义槽的数量,用于Redis集群重新分配槽
SlotsNumber=2000
# 定义接收迁移槽的节点IP和端口
ReceiveIP=192.168.99.121
ReceivePort=6010
# 定义源节点IP和端口,即迁移槽来源的节点
SourceIP=192.168.99.121
SoursePort=6001
# 通过Redis命令行工具获取接收节点和源节点的ID,用于后续的槽迁移操作
ReceiveNodeID=$(redis-cli -h $SourceIP -p $SoursePort cluster nodes | grep $ReceiveIP:$ReceivePort | awk '{print $1}')
SourseNodeID=$(redis-cli -h $SourceIP -p $SoursePort cluster nodes | grep $SourceIP:$SoursePort | awk '{print $1}')
# 创建一个Expect脚本,用于自动交互式地执行Redis集群槽迁移命令
cat >RedisClusterReshard.exp <<EOF
#!/bin/expect
spawn redis-cli --cluster reshard $ReceiveIP:$ReceivePort
# 自动回答迁移的槽数量
expect "How many slots do you want to move (from 1 to 16384)?"
send "$SlotsNumber\r"
# 自动提供接收节点ID
expect "What is the receiving node ID?"
send "$ReceiveNodeID\r"
# 自动提供源节点ID
expect "Source node #1:"
send "$SourseNodeID\r"
# 因为只有一个源节点,所以此处人为输入"done"结束源节点输入
expect "Sourse node #2:"
send "done\r"
# 确认迁移操作
expect "*(yes/no)?"
send "yes\r"
interact
EOF
# 设置Expect脚本的执行权限
chmod 755 RedisClusterReshard.exp
# 执行Expect脚本,开始槽迁移操作
./RedisClusterReshard.exp故障转移
自动故障转移
当集群中有一个master宕机会发生什么
- 首先该实例与其他实例失去连接
- 疑似宕机
- 确定下线,自动提升一个slave为新的master
手动故障转移
数据迁移
在新的slave节点利用cluster failover命令可以手动让集群中的某个master宕机,切换到执行cluster failover命令的这个slave节点,实现无感知的数据迁移.
手动的failover支持三种不同模式:
- 缺省:默认的流程
- force:省略了对offset的一致性校验
- takeover:直接执行第5步,忽略数据一致性、忽略master状态和其他master的意见
集群总线
Redis集群中的每个节点都需要打开两个TCP连接。一个连接用于正常的给Client提供服务,比如 6379,那么对应的还有一个额外的端口就是16379作为数据端口。
这个作为数据端口是在6379端口端号上加10000。
例如:redis的端口为 6379,那么另外一个需要开通的端口是:6379 + 10000, 即需要开启 16379。
16379 端口用于集群总线,这是一个用二进制协议的点对点通信信道。这个集群总线(Cluster bus)用于节点的失败侦测、配置更新、故障转移授权,等等。
解决问题:
开放16379等端口即可:
bash
sudo firewall-cmd --add-port=16370-16379/tcp --permanent
firewall-cmd --reload
firewall-cmd --list-allRedis性能管理
查看Redis内存使用
bash
info memory内存碎片率
操作系统分配的内存值 used_memory_rss 除以 Redis 使用的内存总量值 used_memory 计算得出。
内存值 used_memory_rss 表示该进程所占物理内存的大小,即为操作系统分配给 Redis 实例的内存大小。
除了用户定义的数据和内部开销以外,used_memory_rss 指标还包含了内存碎片的开销, 内存碎片是由操作系统低效的分配/回收物理内存导致的(不连续的物理内存分配)。
举例来说:Redis 需要分配连续内存块来存储 1G 的数据集。如果物理内存上没有超过 1G 的连续内存块, 那操作系统就不得不使用多个不连续的小内存块来分配并存储这 1G 数据,该操作就会导致内存碎片的产生。
#跟踪内存碎片率对理解Redis实例的资源性能是非常重要的:
- 内存碎片率稍大于1是合理的,这个值表示内存碎片率比较低,也说明 Redis 没有发生内存交换。
- 内存碎片率超过1.5,说明Redis消耗了实际需要物理内存的150%,其中50%是内存碎片率。需要在redis-cli工具上输入
shutdown save命令,让 Redis 数据库执行保存操作并关闭 Redis 服务,再重启服务器。 - 内存碎片率低于1的,说明Redis内存分配超出了物理内存,操作系统正在进行内存交换。需要增加可用物理内存或减少 Redis 内存占用。
内存使用率
redis实例的内存使用率超过可用最大内存,操作系统将开始进行内存与swap空间交换。
#避免内存交换发生的方法:
- 针对缓存数据大小选择安装 Redis 实例
- 尽可能的使用Hash数据结构存储
- 设置key的过期时间
内存回收key
内存清理策略,保证合理分配redis有限的内存资源。
当达到设置的最大阀值时,需选择一种key的回收策略,默认情况下回收策略是禁止删除。
配置文件中修改 maxmemory-policy 属性值:
bash
vim /etc/redis/6379.conf
bash
--598--
maxmemory-policy noenviction
volatile-lru:使用LRU算法从已设置过期时间的数据集合中淘汰数据(移除最近最少使用的key,针对设置了TTL的key)
volatile-ttl:从已设置过期时间的数据集合中挑选即将过期的数据淘汰(移除最近过期的key)
volatile-random:从已设置过期时间的数据集合中随机挑选数据淘汰(在设置了TTL的key里随机
移除)
allkeys-lru:使用LRU算法从所有数据集合中淘汰数据(移除最少使用的key,针对所有的key)
allkeys-random:从数据集合中任意选择数据淘汰(随机移除key)
noenviction:禁止淘汰数据(不删除直到写满时报错)