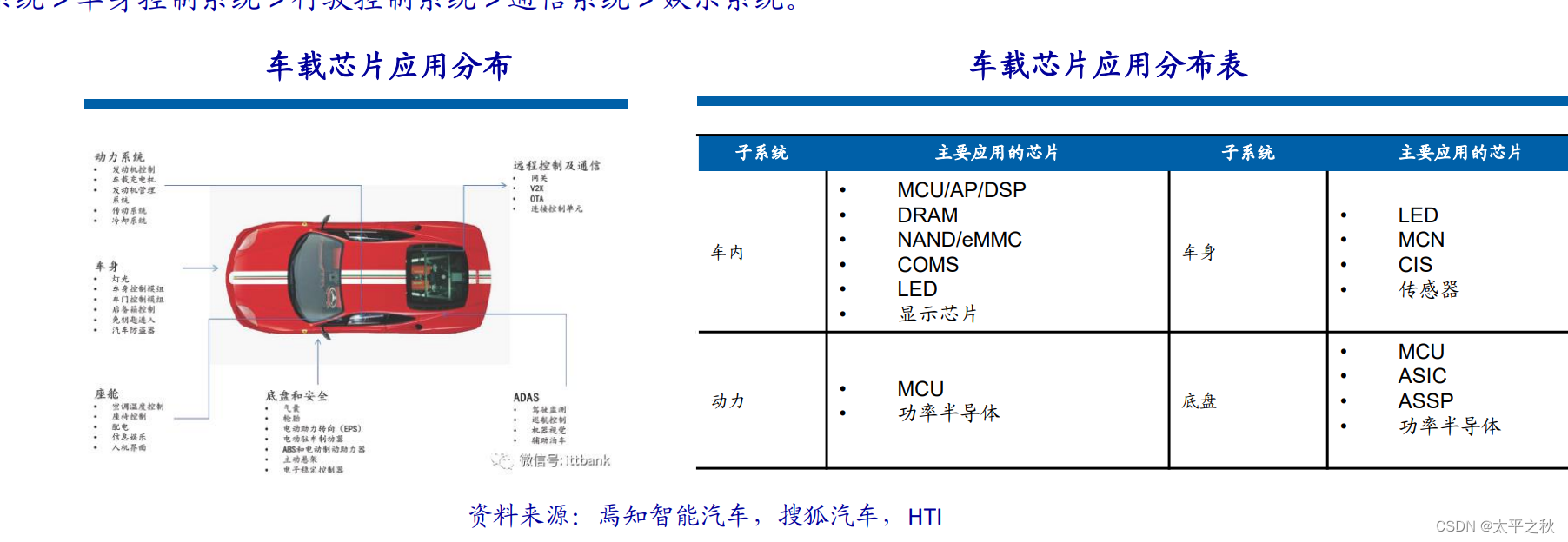
概述
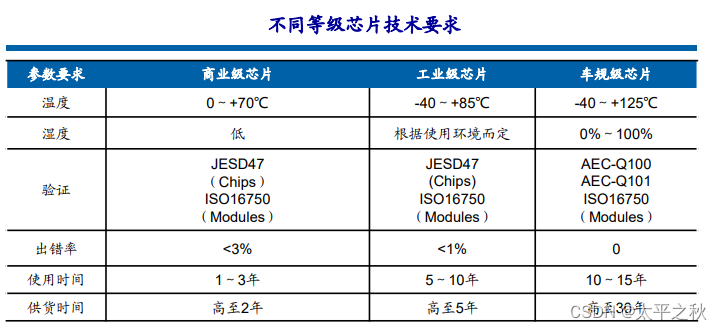
汽车是芯片应用场景之一,汽车芯片需要具备车规级。 车规级芯片对加工工艺要求不高,但对质量要求高。需要经过的认证过程,包括质量管理标准ISO/TS 16949、可靠性标准 AEC-Q100、功能安全标准ISO26262等。 汽车内不同用途的芯片要求也不同,美国制定的汽车电子标准把其分为5级。汽车各系统对芯片要求由高到低依次是:动力安 全系统 > 车身控制系统 > 行驶控制系统 > 通信系统 > 娱乐系统。
自动驾驶芯片产品趋势:一体化
云和边缘计算的数据中心,以及自动驾驶等超级终端领域,都是典型的复杂计算场景,这类场景的计算平台都是典型的大算 力芯片。大芯片的发展趋势已经越来越明显的从GPU、DSA的分离趋势走向DPU、超级终端的再融合,未来会进一步融合成超 异构计算宏系统芯片。
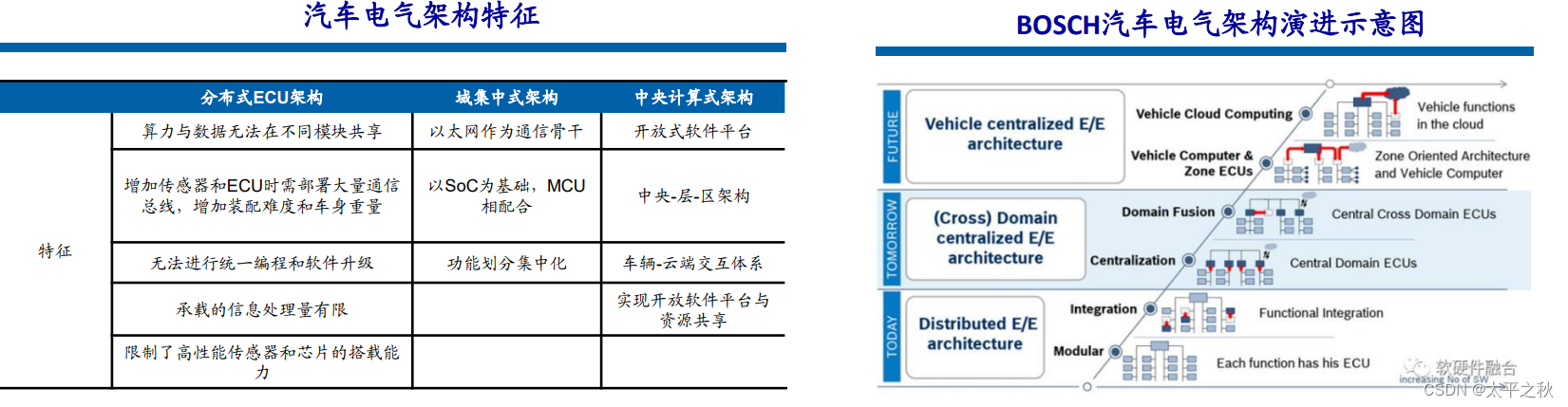
BOSCH给出了汽车电气架构演进示意图。从模块级的ECU到集中相关功能的域控制器,再到完全集中的车载计算机。每个阶段 还分了两个子阶段,例如完全集中的车载计算机还包括了本地计算和云端协同两种方式。
英伟达一体化方案(thor 芯片官网信息)

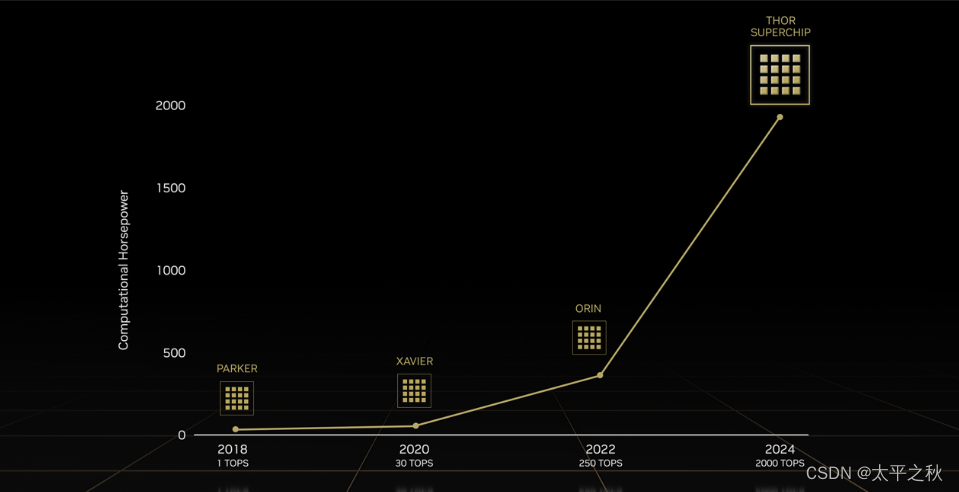
2022年NVIDIA 创始人兼首席执行官黄仁勋公布了一款令人惊艳的超级芯片------DRIVE Thor。这款车规级系统级芯片 (SoC) 基于最新 CPU 和 GPU 打造,可提供每秒 2000 万亿次浮点运算性能,在大幅度提升性能的同时降低整体系统的运行成本。
DRIVE Thor 将逐步接替 DRIVE Orin,以最新的计算技术,加速智能汽车技术在行业内的部署,赋能汽车制造商的 2025 年车型。
借助DRIVE Thor,汽车制造商可以在单个系统级芯片上高效整合数字仪表盘、信息娱乐、泊车、辅助驾驶等多种功能,从而极大地提高开发效率和软件更新迭代的速度。
DRIVE Thor 能够被配置为多种模式,可以将其 2000 TOPS 和 2000 TFLOPS 全部用于自动驾驶工作流,也可以进行拆分,将其配置为一部分用于驾驶舱 AI 和信息娱乐功能,一部分用于辅助驾驶。
与当前的 NVIDIA DRIVE Orin 一样,DRIVE Thor可以利用高效的 NVIDIA DRIVE 软件开发套件,且已获得 ASIL-D级功能安全产品认证。同时,DRIVE Thor 基于可扩展架构打造,因而开发人员可以将过去的软件开发成果无缝移植到新平台。
DRIVE Thor,快如闪电
除了原始性能之外,DRIVE Thor 在深度神经网络 (DNN) 准确性方面也实现了惊人的飞跃。
此外,DRIVE Thor 也是首个采用推理 Transformer 引擎的NVIDIA自动驾驶汽车平台。Transformer 引擎是 NVIDIA GPU Tensor Core 的一个全新组件。Transformer 网络将视频数据作为单个感知帧来处理,使计算平台能够随着时间的推移具有处理更多数据的能力。
凭借着 8 位浮点(FP8)的精度,DRIVE Thor为汽车领域引入了一种新的数据处理方式。传统意义上讲,开发人员在从32 位浮点转换为 8 位整数 (8-int) 的数据格式时,会发现准确性有所下降。DRIVE Thor的FP8精度有助于促进数据的转换,允许开发人眼在不牺牲准确性的情况下进行数据传输。
此外,DRIVE Thor还采用了升级后的ARM Poseidon AE内核,这也让其成为业界最高性能的处理器之一。
一芯多用 多域计算
DRIVE Thor 不仅功能强劲,且运行高效。
DRIVE Thor能够进行多域计算,这意味着它可以将自动驾驶、车载信息娱乐等功能划分为不同的任务区间,同时运行,互不干扰。多计算域隔离能力,可支持时间关键型的进程不间断同时运行,也就是说,车辆在一台计算机上可以同时运行 Linux、QNX 和 Android。
这些类型不同的功能,通常由分布在车辆各处的数十个电子控制单元控制。如今,汽车制造商可借助DRIVE Thor隔离特定任务的能力,告别分布式的电子控制单元,整合全车功能。
汽车制造商可以借助 DRIVE Thor 在单个 SoC 上整合智能汽车所有功能
此外,DRIVE Thor芯片也可以让车辆所有的显示器、传感器等都连接到单一芯片上,极大地简化了汽车制造的复杂程序,这也是汽车电子电气架构从分布式向集中式演进的大势所趋。
NVLink-C2C 芯片互连技术
单独使用一个 DRIVE Thor 即可实现卓越性能,那么两个一起呢?用户可以单独使用 DRIVE Thor 芯片,也可以通过最新的 NVLink-C2C 芯片互连技术同时连接两个 Thor芯片,使两个芯片作为单一操作系统的统一平台。NVLink-C2C 的优势在于它能够以最小的开销在超高速数据传输链路中共享、调度和分发任务。在软件定义汽车的发展趋势下,这为汽车制造商带来足够大的算力冗余和灵活性,支持软件定义车辆的开发,这些车辆可通过安全的 OTA 更新持续升级。

高通一体化方案
2020年CES上,高通推出全新自动驾驶平台高通Snapdragon Ride,自动驾驶芯片"骁龙 Ride"。 该平台包括安全系统级芯片SoC(ADAS应用处理器)、安全加速器(自动驾驶专用加速器)和自动驾驶软件栈,可支持L1-L5 级别的自动驾驶;安全系统级芯片SoC和安全加速器的功能安全安全等级为ASIL-D级;平台高度可扩展、开放、完全可定制化, 且能够提供功耗高度优化的自动驾驶解决方案;平台将于2020年上半年交付OEM和Tire1进行前期开发,搭载该平台的汽车预 计将于2023年投产。

Snapdragon Ride视觉系统是基于4纳米制程的系统级芯片(SoC)打造,集成了专用高性能的Snapdragon Ride SoC和Arriver下一 代视觉感知软件栈,并采用基于定制神经网络架构开发的800万像素广角摄像头。

就在英伟达发布 Thor 两天后,高通就推出"业内首个集成式汽车超算 SOC"Snapdragon Ride Flex,单颗算力 600TOPS 以上, 综合 AI 算力能够达到 2000TOPS。Snapdragon Ride Flex确切的说是一个SoC产品家族,其包括Mid、High、Premium三个级别。 最高级的Ride Flex Premium SoC再加上外挂的AI加速器(可能是NPU,MAC阵列)组合起来,就可以实现2000TOPS的综合AI算 力。Snapdragon Ride Flex作为一个超算芯片家族,其最大的目标是实现车内的中央计算------即同时为智能驾驶、智能座舱、通 信等能力提供计算支持,这也与英伟达Thor雷神芯片一致。
向先进制程延伸
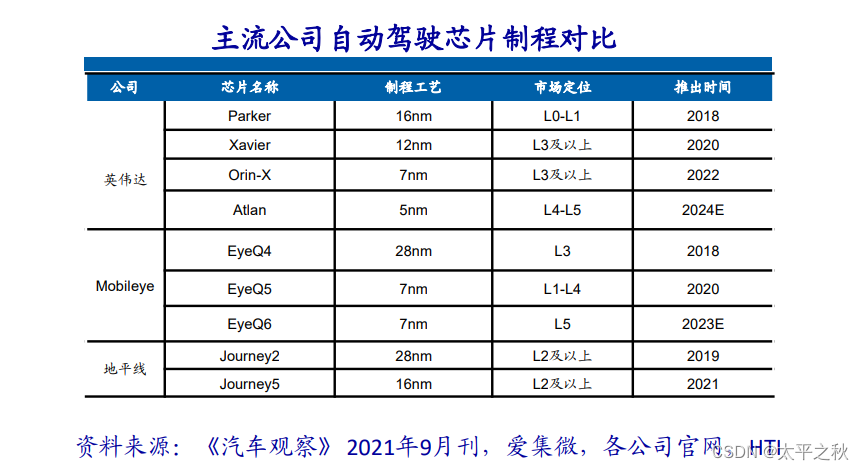
高端自动驾驶芯片向先进制程延申:用于L1-L2 自动驾驶的芯片只需要28nm制程即可制造,L3 及以上的高阶自动驾驶对算力 的要求越发苛刻,规划中针对L4/L5 自动驾驶的SoC芯片普遍需要7nm,甚至5nm的先进制程。先进的制程可以影响功耗,先 进的制程又可以影响集成度;而功耗则影响可靠性,集成度影响性能。 目前的 5nm制程芯片尚处于研发或发布状态,均未进入量产阶段;不过 7nm芯片中,已有 Orin、FSD、EyeQ5、8155 等芯片实 现量产,其他芯片则在未来几年陆续实现量产,这预示着先进制程车用芯片开始进入量产加速期。
高算力
三种主流架构
当前主流的AI芯片主要分为三类,GPU、FPGA、ASIC。GPU、FPGA均是前期较为成熟的芯片架构,属于通用型芯片。
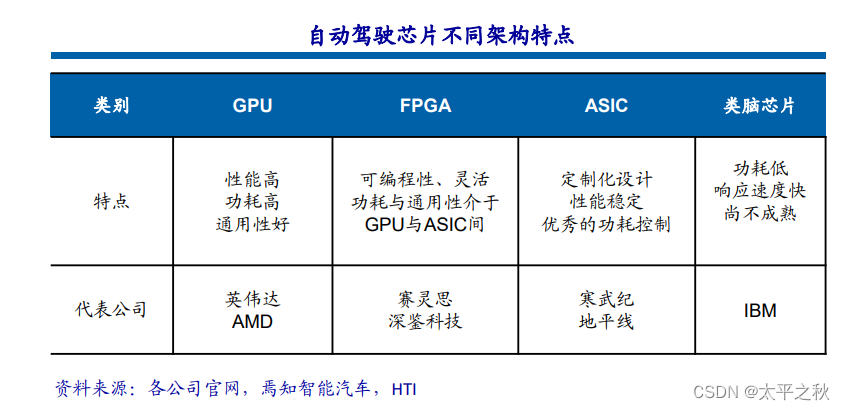
CPU遵循的是冯·诺依曼架构,其核心是存储程序/数据、串行顺序执行。因此CPU的架构中需要大量的空间去放置存储单 元(Cache)和控制单元(Control),相比之下计算单元(ALU)只占据了很小的一部分,所以CPU在进行大规模并行计 算方面受到限制,相对而言更擅长于处理逻辑控制。
GPU(GraphicsProcessing Unit),即图形处理器,是一种由大量运算单元组成的大规模并行计算架构,早先由CPU中分出 来专门用于处理图像并行计算数据,专为同时处理多重并行计算任务而设计。GPU中也包含基本的计算单元、控制单元 和存储单元,但GPU的架构与CPU有很大不同,其架构图如下所示。
与CPU相比,CPU芯片空间的不到20%是ALU,而GPU芯片空间的80%以上是ALU。即GPU拥有更多的ALU用于数据并行处理。
CPU 由专为顺序串行处理而优化的几个核心组成,而 GPU 则拥有一个由数以千计的更小、更高效的核心组成的大规模并 行计算架构,这些更小的核心专为同时处理多重任务而设计。
CPU和GPU之所以大不相同,是由于其设计目标的不同,它们分别针对了两种不同的应用场景。CPU需要很强的通用性来 处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理。这些都使得CPU的内部结构异常复 杂。而GPU面对的则是类型高度统一的、相互无依赖的大规模数据和不需要被打断的纯净的计算环境。
GPU 的众核体系结构包含几千个流处理器,可将运算并行化执行,大幅缩短模型的运算时间。 目前 GPU 已经发展到了较为成熟的阶段。利用 GPU 来训练深度神经网络,可以充分发挥其数以千计计算核心的高效并行 计算能力,在使用海量训练数据的场景下,所耗费的时间大幅缩短,占用的服务器也更少。如果针对适当的深度神经网络进行合理优化,一块 GPU 卡可相当于数十甚至上百台 CPU服务器的计算能力,因此 GPU 已经成为业界在深度学习模型 训练方面的首选解决方案。
芯片关键评估指标

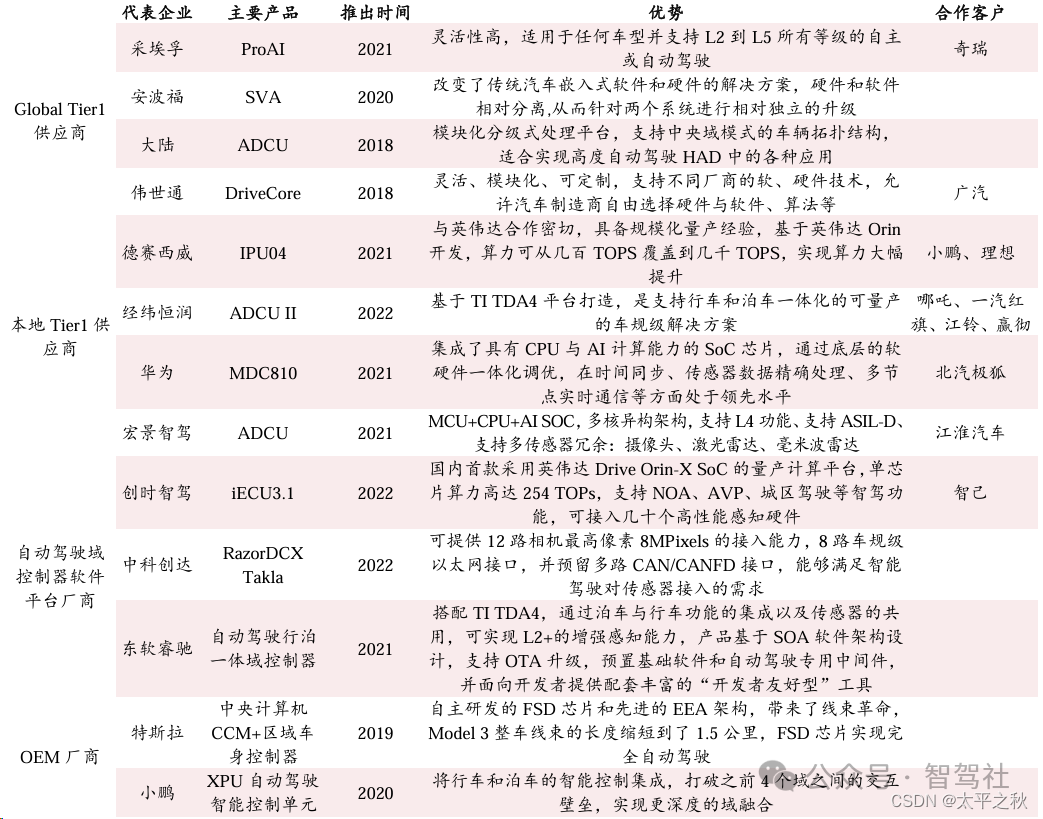
国内外智驾域控制器方案
资料引用:
海通国际-电子行业:自动驾驶芯片研究框架-230115.pdf (dfcfw.com)
英伟达官网