Python学习从0开始------Kaggle机器学习004总结2
一、缺失值
三种处理方式:
1)删除缺失值:
方法描述:最简单直接的方法是删除含有缺失值的行或列。
适用场景:适用于缺失值占比较小,且删除后不会显著影响数据分布和模型性能的情况。
优点:快速,易于实现,不需要任何先验知识。
缺点:可能会导致数据信息的丢失,特别是对于缺失值占比较大的数据集不适用。
python
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
def score_dataset(X_train, X_valid, y_train, y_valid):
model = RandomForestRegressor(n_estimators=100, random_state=0)
model.fit(X_train, y_train)
preds = model.predict(X_valid)
return mean_absolute_error(y_valid, preds)
# 获取含缺失值的列
cols_with_missing = [col for col in X_train.columns
if X_train[col].isnull().any()]
# 从训练和验证数据中删除
reduced_X_train = X_train.drop(cols_with_missing, axis=1)
reduced_X_valid = X_valid.drop(cols_with_missing, axis=1)
print("MAE from Approach 1 (Drop columns with missing values):")
print(score_dataset(reduced_X_train, reduced_X_valid, y_train, y_valid))2)插值法:
方法描述:通过已知的数据来推断缺失值。常用的插值方法包括均值插值、中位数插值、众数插值、回归插值、KNN插值等。
适用场景:适用于数值型或类别型数据,可以根据数据的分布和特征选择合适的插值方法。
具体方法:
均值插值:用特征的均值来代替缺失值,适用于数值型数据。
中位数插值:用特征的中位数来代替缺失值,适用于数值型数据。
众数插值:用特征的众数来代替缺失值,适用于类别型数据。
回归插值:用已知的特征作为自变量,用回归模型来预测缺失值,适用于数值型数据。
KNN插值:用已知的特征作为自变量,使用KNN算法来预测缺失值,适用于数值型或类别型数据。
优点:能够保留数据的完整性,减少信息的丢失。
缺点:插值方法的选择需要基于数据的特征和分布,不当的插值方法可能导致数据失真。
python
from sklearn.impute import SimpleImputer
# Imputation
my_imputer = SimpleImputer()
imputed_X_train = pd.DataFrame(my_imputer.fit_transform(X_train))
imputed_X_valid = pd.DataFrame(my_imputer.transform(X_valid))
# Imputation removed column names; put them back
imputed_X_train.columns = X_train.columns
imputed_X_valid.columns = X_valid.columns
print("MAE from Approach 2 (Imputation):")
print(score_dataset(imputed_X_train, imputed_X_valid, y_train, y_valid))3)构建模型预测缺失值:
方法描述:使用缺失值所在的行或列作为目标变量,其他变量作为自变量来构建模型,然后用模型来预测缺失值。
适用场景:适用于数据集中缺失值占比较大,且其他变量与缺失值之间存在相关性的情况。
具体方法:可以使用各种机器学习算法(如线性回归、决策树、随机森林等)来构建预测模型。
优点:能够利用数据集中的信息来填补缺失值,减少信息的丢失。
缺点:对于数据集中缺失值占比较大的情况,可能会导致模型的偏差。
python
# Make copy to avoid changing original data (when imputing)
X_train_plus = X_train.copy()
X_valid_plus = X_valid.copy()
# Make new columns indicating what will be imputed
for col in cols_with_missing:
X_train_plus[col + '_was_missing'] = X_train_plus[col].isnull()
X_valid_plus[col + '_was_missing'] = X_valid_plus[col].isnull()
# Imputation
my_imputer = SimpleImputer()
imputed_X_train_plus = pd.DataFrame(my_imputer.fit_transform(X_train_plus))
imputed_X_valid_plus = pd.DataFrame(my_imputer.transform(X_valid_plus))
# Imputation removed column names; put them back
imputed_X_train_plus.columns = X_train_plus.columns
imputed_X_valid_plus.columns = X_valid_plus.columns
print("MAE from Approach 3 (An Extension to Imputation):")
print(score_dataset(imputed_X_train_plus, imputed_X_valid_plus, y_train, y_valid))通常,与简单地删除缺失值的列相比,输入缺失值会产生更好的结果。
二、分类变量
2.1介绍
分类变量(Categorical Variables)或称为类别变量,是那些具有离散值(或类别)的变量,而不是连续值。这些变量通常用于描述对象的属性或特征,其值通常是预定义的、有限的集合。例如调查多久吃一次早餐,并提供四个选项:"从不","很少","大多数天"或"每天",在这种情况下,数据是分类的,因为响应属于一组固定的类别。如果将这些变量直接插入Python中的大多数机器学习模型且不进行预处理,则会出现错误。在此将比较用于准备分类数据的三种方法。
1)删除分类变量
处理分类变量最简单的方法是从数据集中删除它们。这种方法只有在列不包含有用信息的情况下才有效。
2)序数编码
序数编码将每个唯一值分配给不同的整数。这种方法假设了一个类别的顺序:"从不"(0)<"很少"(1)<"大多数日子"(2)<"每天"(3)。
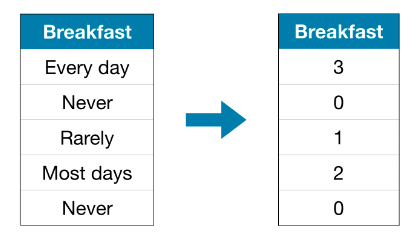
这个假设在这个例子中是有意义的,因为这些变量具有自然的顺序或等级,但并非非所有分类变量的值都有明确的顺序。我们将顺序明确的变量称为有序变量,将变量的类别之间没有明确的顺序如血型(A、B、O、AB)或颜色(红色、蓝色、绿色)称为无序分类变量。
3)独热编码
One-Hot Encoding为每个类别创建一个新的二进制列,并在相应的行中设置为1,其他行设置为0。这种方法适用于无序分类变量。
在原始数据集中,"Color"是一个分类变量,有三个类别:"Red","Yellow"和"Green"。对应的one-hot编码包含每个可能值的一列,原始数据集中的每一行。在原始值为"Red"的地方,我们在"Red"列中添加1;如果原始值为"Yellow",则在"Yellow"列中添加1,依此类推。
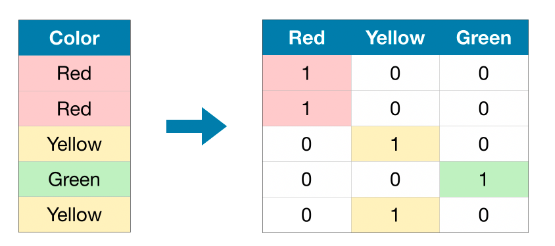
与序数编码相反,独热编码不假设类别的顺序。如果分类变量接受大量的值那么One-hot编码通常不会执行得很好(通常不会将它用于接受超过15个不同值的变量)。
2.2实现
假设现在已经有了X_train、X_valid、y_train和y_valid中的训练和验证数据。
1.获取训练数据中所有分类变量的列表。
通过检查每个列的数据类型(或dtype)来实现。对象dtype表示列有文本(理论上还可能有其他情况,但这对我们的目的不重要)。对于这个数据集,带有文本的列表示分类变量。
python
# 获取分类变量列表
s = (X_train.dtypes == 'object')
object_cols = list(s[s].index)
print("Categorical variables:")
print(object_cols)
-------------输出---------------------
Categorical variables:
['Type', 'Method', 'Regionname']2.比较每种方法
我们定义了一个函数score_dataset()来比较处理分类变量的三种不同方法。这个函数报告随机森林模型的平均绝对误差(MAE)。通常,我们希望MAE越低越好!
方法1(删除分类变量)
我们使用select_dtypes()方法删除对象列。
python
drop_X_train = X_train.select_dtypes(exclude=['object'])
drop_X_valid = X_valid.select_dtypes(exclude=['object'])
print("MAE from Approach 1 (Drop categorical variables):")
print(score_dataset(drop_X_train, drop_X_valid, y_train, y_valid))
------------输出-----------------------
MAE from Approach 1 (Drop categorical variables):
175703.48185157913方法2(序数编码)
Scikit-learn有一个OrdinalEncoder类,可用于获得有序编码。我们循环遍历分类变量,并分别对每个列应用顺序编码器。
python
from sklearn.preprocessing import OrdinalEncoder
# 生成副本,避免改变原始数据
label_X_train = X_train.copy()
label_X_valid = X_valid.copy()
# 对具有分类数据的每个列应用顺序编码器
ordinal_encoder = OrdinalEncoder()
label_X_train[object_cols] = ordinal_encoder.fit_transform(X_train[object_cols])
label_X_valid[object_cols] = ordinal_encoder.transform(X_valid[object_cols])
print("MAE from Approach 2 (Ordinal Encoding):")
print(score_dataset(label_X_train, label_X_valid, y_train, y_valid))
-----------------输出--------------------------
MAE from Approach 2 (Ordinal Encoding):
165936.40548390493在上面的代码单元格中,对于每一列,我们将每个唯一值随机分配给不同的整数。这是一种常见的方法,比提供自定义标签更简单;然而,如果我们为所有有序变量提供更好的标签,我们可以期望性能的额外提升。
方法3独热编码
我们使用scikit-learn中的OneHotEncoder类来获得One-Hot编码。
有许多参数可用于自定义其行为:
- 设置handle_unknown='ignore'以避免在验证数据中包含未在训练数据中表示的类时出现错误,
- 设置sparse=False确保编码列以numpy数组(而不是稀疏矩阵)的形式返回。
要使用编码器,我们只提供我们希望进行单热编码的分类列。例如,为了对训练数据进行编码,我们提供X_trainobject_cols。
python
from sklearn.preprocessing import OneHotEncoder
# 对具有分类数据的每个列应用独热编码器
OH_encoder = OneHotEncoder(handle_unknown='ignore', sparse=False)
OH_cols_train = pd.DataFrame(OH_encoder.fit_transform(X_train[object_cols]))
OH_cols_valid = pd.DataFrame(OH_encoder.transform(X_valid[object_cols]))
# One-hot encoding 删除索引并放回
OH_cols_train.index = X_train.index
OH_cols_valid.index = X_valid.index
# 删除分类列(将替换为one-hot编码)
num_X_train = X_train.drop(object_cols, axis=1)
num_X_valid = X_valid.drop(object_cols, axis=1)
# 向数字特征添加独热编码列
OH_X_train = pd.concat([num_X_train, OH_cols_train], axis=1)
OH_X_valid = pd.concat([num_X_valid, OH_cols_valid], axis=1)
# 确保所有列都是字符串类型
OH_X_train.columns = OH_X_train.columns.astype(str)
OH_X_valid.columns = OH_X_valid.columns.astype(str)
print("MAE from Approach 3 (One-Hot Encoding):")
print(score_dataset(OH_X_train, OH_X_valid, y_train, y_valid))
----------------------输出-------------------------
MAE from Approach 3 (One-Hot Encoding):
166089.4893009678哪种方法最好?
在这种情况下,删除分类列(方法1)表现最差,因为它具有最高的MAE分数。其他两种方法返回的MAE分数的值非常接近,似乎二者没有优劣。
但一般来说,独热编码通常表现最好,而删除分类列通常表现最差,具体视情况不同。
三、管道
3.1介绍
管道是保持数据预处理和建模代码组织的一种简单方法。具体来说,管道将预处理和建模步骤捆绑在一起,因此一个简单的步骤可以使用整个捆绑包。
管道有一些重要的好处包括
- 更简洁的代码:在预处理的每个步骤中计算数据可能会变得混乱。使用管道,将不需要在每个步骤手动跟踪训练和验证数据。
- 更少的bug:错误应用步骤或忘记预处理步骤的可能性更少。
- 更容易产品化:将模型从原型转换为可大规模部署的东西可能会非常困难,但管道可以提供帮助。
- 模型验证的更多选项:涵盖交叉验证。
3.2实现
假设现在已经有了X_train、X_valid、y_train和y_valid中的训练和验证数据。
步骤1:定义预处理步骤
与管道将预处理和建模步骤捆绑在一起的方式类似,我们使用ColumnTransformer类将不同的预处理步骤捆绑在一起。下面的代码在数值数据中输入缺失值,并对分类数据输入缺失值并应用独热编码。
python
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
# 数值数据的预处理
numerical_transformer = SimpleImputer(strategy='constant')
# 分类数据的预处理
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
# 数字和分类数据的绑定预处理
preprocessor = ColumnTransformer(
transformers=[
('num', numerical_transformer, numerical_cols),
('cat', categorical_transformer, categorical_cols)
])步骤2:定义模型
接下来,我们用熟悉的RandomForestRegressor类定义一个随机森林模型。
python
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=100, random_state=0)步骤3:创建和评估管道
最后,我们使用Pipeline类来定义一个管道,该管道将预处理和建模步骤捆绑在一起。有几件重要的事情需要注意:使用管道,我们预处理训练数据并在一行代码中拟合模型。(相比之下,如果没有管道,我们必须在单独的步骤中进行imputation, one-hot编码和模型训练。如果我们必须同时处理数值变量和分类变量,这会变得特别混乱!)使用管道,我们将X_valid中未处理的特征提供给predict()命令,并且管道在生成预测之前自动预处理这些特征。(但是,如果没有管道,我们必须记住在进行预测之前对验证数据进行预处理。)
管道对于清理机器学习代码和避免错误很有价值,对于具有复杂数据预处理的工作流尤其有用。
python
from sklearn.metrics import mean_absolute_error
#在管道中捆绑预处理和建模代码
my_pipeline = Pipeline(steps=[('preprocessor', preprocessor),
('model', model)])
# 训练数据预处理,拟合模型
my_pipeline.fit(X_train, y_train)
# 对验证数据进行预处理,得到预测
preds = my_pipeline.predict(X_valid)
# 评估模型
score = mean_absolute_error(y_valid, preds)
print('MAE:', score)
----------------------输出--------------------------------
MAE: 160679.18917034855管道对于清理机器学习代码和避免错误很有价值,对于具有复杂数据预处理的工作流尤其有用。
四、交叉验证
1.介绍
机器学习是一个迭代的过程,面临选择使用什么预测变量,使用什么类型的模型,为这些模型提供什么参数等等。到目前为止,已经通过使用验证(或保留)集度量模型质量,以数据驱动的方式做出了这些选择。但是这种方法也有一些缺点。
假设有一个5000行的数据集,通常会保留大约20%的数据作为验证数据集,或1000行。一个模型可能在一个1000行的集合上表现良好,即使它在另一个1000行的集合上是不准确的。在极端情况下,比如验证集中只有一行数据。如果比较不同的模型,哪一个在单个数据点上做出最好的预测将主要是运气问题!
一般来说,验证集越大,我们对模型质量的度量中的随机性(也就是"噪声")就越少,它就越可靠。不幸的是,我们只能通过从训练数据中删除行来获得一个大的验证集,而更小的训练数据集意味着更差的模型。
在交叉验证中,我们在数据的不同子集上运行建模过程,以获得模型质量的多个度量。
例如,可以将数据分成5个部分,每个部分占整个数据集的20%。在这种情况下,我们说我将数据分成5个"折"(fold)。

然后,我们为每个折叠运行一个实验:
- 在实验1中,我们使用第一折作为验证(或保留)集,其他所有内容作为训练数据。这给了我们一个基于20%拒绝集合的模型质量度量。
- 在实验2中,我们保留了第二折的数据(并使用除了第二次折叠的所有数据来训练模型)。然后使用保留集来获得模型质量的第二次估计。
- 重复这个过程,使用每一折作为保留集。把这些放在一起,100%的数据在某一点上被用作holdout,并且我们最终得到了基于数据集中所有行的模型质量度量(即使我们没有同时使用所有行)。
2.什么时候应该使用交叉验证?
交叉验证提供了更准确的模型质量度量,如果你要做很多建模决策,这一点尤为重要。然而,它可能需要更长的时间来运行,因为它估计多个模型(每折一个)。
对于小数据集,额外的计算负担不是什么大问题应该运行交叉验证。对于较大的数据集,单个验证集就足够了,有足够的数据几乎不需要为保留而重用其中的一些数据。大数据集和小数据集的构成并没有简单的界限。但是,如果模型需要几分钟或更少的时间来运行,那么切换到交叉验证是值得的。或者运行交叉验证,看看每个实验的分数是否接近。如果每个实验产生相同的结果,一个验证集可能就足够了。
3.使用
使用与上一节相同的数据,在X中加载输入数据,在y中加载输出数据。然后定义一个管道,该管道使用输入器填充缺失值,并使用随机森林模型进行预测。虽然可以在没有管道的情况下进行交叉验证,但这相当困难,使用管道将使代码非常简单。
python
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
my_pipeline = Pipeline(steps=[('preprocessor', SimpleImputer()),
('model', RandomForestRegressor(n_estimators=50,
random_state=0))])我们使用scikit-learn中的cross_val_score()函数获得交叉验证分数。我们用cv参数来设置折叠次数。
python
from sklearn.model_selection import cross_val_score
# 乘以-1,因为sklearn计算负MAE
scores = -1 * cross_val_score(my_pipeline, X, y,
cv=5,
scoring='neg_mean_absolute_error')
print("MAE scores:\n", scores)
-----------------输出-------------------
MAE scores:
[301628.7893587 303164.4782723 287298.331666 236061.84754543
260383.45111427]评分参数选择要报告的模型质量度量:在这种情况下,我们选择负平均绝对误差(MAE)。scikit-learn的文档显示了一个选项列表。
我们指定负MAE有点令人惊讶。Scikit-learn有一个约定,即定义所有参数,所以数值越高越好。这里使用负数可以使它们与惯例保持一致,尽管在其他地方几乎闻所未闻。
我们通常需要一个模型质量的单一度量来比较可选模型,如取所有实验的平均值。
python
print("Average MAE score (across experiments):")
print(scores.mean())
-----------------输出----------------------
Average MAE score (across experiments):
277707.3795913405使用交叉验证可以更好地度量模型质量,同时还可以清理代码:注意,我们不再需要跟踪单独的训练集和验证集。所以,特别是对于小数据集,这是一个很好的改进!
五、XGBoost
使用随机森林方法进行预测,比简单地通过平均许多决策树的预测来实现单个决策树更好的性能。我们把随机森林方法称为"集成方法"。根据定义,集成方法结合了几个模型的预测。
接下来,将学习另一种称为梯度增强的集成方法。
5.1介绍
梯度增强是一种通过循环迭代地将模型添加到集成中的方法。它首先用一个模型初始化集合,这个模型的预测可能相当原始。(即使它的预测非常不准确,后续对集合的补充也会解决这些错误。)
然后,我们开始循环:
- 首先,我们使用当前集合为数据集中的每个观测生成预测。为了进行预测,我们将集合中所有模型的预测结果相加。这些预测用于计算损失函数(例如均方误差)。
- 然后,我们使用损失函数来拟合一个新的模型,该模型将被添加到集成中。具体来说,我们确定了模型参数,以便将这个新模型添加到集成中可以减少损失。(旁注:"梯度增强"中的"梯度"指的是我们将在损失函数上使用梯度下降来确定这个新模型中的参数。)
- 最后,我们集成新模型等操作
- 重复以上步骤

5.2使用
XGBoost代表极端梯度增强,它是梯度增强的一种实现,具有几个专注于性能和速度的附加功能。导入XGBoost,就能像在scikit-learn中一样创建和训练模型,XGBRegressor类有许多可调参数。
python
from xgboost import XGBRegressor
my_model = XGBRegressor()
my_model.fit(X_train, y_train)对模型进行预测和评估。
python
from sklearn.metrics import mean_absolute_error
predictions = my_model.predict(X_valid)
print("Mean Absolute Error: " + str(mean_absolute_error(predictions, y_valid)))
----------------输出-----------------------
Mean Absolute Error: 241041.51603921215.3参数训练
XGBoost有几个参数可以极大地影响准确性和训练速度。
1)n_estimators:n_estimators指定通过上述建模周期的次数。它等于我们在集合中包含的模型的数量。过低的值会导致欠拟合,从而导致对训练数据和测试数据的预测不准确。过高的值会导致过拟合,这会导致对训练数据的准确预测,但对测试数据的不准确预测。典型的值范围是100-1000,尽管这在很大程度上取决于下面讨论的learning_rate参数。设置集合中模型数量:
python
my_model = XGBRegressor(n_estimators=500)
my_model.fit(X_train, y_train)2)early_stopping_rounds:early_stopping_rounds提供了一种自动查找n_estimators的理想值的方法。当验证分数停止改进时,提前停止导致模型停止迭代,即使我们没有在n_estimators的硬停止。聪明的做法是为n_estimators设置一个高值,然后使用early_stopping_rounds找到停止迭代的最佳时间。由于随机机会有时会导致单个回合的验证分数没有提高,因此需要指定在停止之前允许多少轮直接恶化的数字。设置early_stopping_rounds=5是一个合理的选择。在这种情况下,我们在连续5轮验证分数恶化后停止。在使用early_stopping_rounds时,还需要留出一些数据用于计算验证分数------这可以通过设置eval_set参数来完成。提前停止:
python
my_model = XGBRegressor(n_estimators=500)
my_model.fit(X_train, y_train,
early_stopping_rounds=5,
eval_set=[(X_valid, y_valid)],
verbose=False)3)learning_rate:如果以后想要用所有数据拟合一个模型,可以将n_estimators设置为在提前停止运行时发现的最佳值。我们不是简单地将每个组件模型的预测相加来获得预测,而是可以将每个模型的预测乘以一个小数字(称为学习率),然后再添加它们。这意味着每增加一棵树对我们的帮助就会减少。因此,我们可以在不过度拟合的情况下为n_estimators设置一个更高的值。如果采用提前停止,将自动确定合适的树数。一般来说,较小的学习率和大量的估计器将产生更准确的XGBoost模型,尽管它也将花费更长的时间来训练模型,因为它在循环中进行了更多的迭代。默认情况下,XGBoost设置learning_rate=0.1。改变学习率:
python
my_model = XGBRegressor(n_estimators=1000, learning_rate=0.05)
my_model.fit(X_train, y_train,
early_stopping_rounds=5,
eval_set=[(X_valid, y_valid)],
verbose=False)4)n_jobs:在考虑运行时间的大型数据集上,可以使用并行性来更快地构建模型。通常将参数n_jobs设置为机器上的核数。在较小的数据集上,这不起作用。最终的模型不会更好,所以对拟合时间的微优化通常只是一种干扰。但是,它在大型数据集中很有用,否则将在fit命令期间花费很长时间等待。下面是修改后的例子:
python
my_model = XGBRegressor(n_estimators=1000, learning_rate=0.05, n_jobs=4)
my_model.fit(X_train, y_train,
early_stopping_rounds=5,
eval_set=[(X_valid, y_valid)],
verbose=False)XGBoost是一个领先的软件库,用于处理标准表格数据(存储在Pandas dataframe中的数据类型,而不是图像和视频等更奇特的数据类型)。通过仔细的参数调整,可以训练高度精确的模型。
六、数据泄露
6.1产生
当训练数据包含有关目标的信息时,就会发生数据泄漏(或泄漏),但当模型用于预测时,将无法获得类似的数据。这将导致训练集(甚至可能是验证数据)上的高性能,但模型在生产中的性能将很差。换句话说,泄漏导致模型看起来很准确,直到开始使用模型做出决策,然后模型变得非常不准确。泄漏主要有两种类型:目标泄露和训练-测试集污染。
6.2目标泄漏
目标泄漏是当预测器包含在进行预测时不可用的数据时,就会发生目标泄漏。重要的是要根据数据可用的时间或时间顺序来考虑目标泄漏,而不仅仅是一个功能是否有助于做出正确的预测。举个例子会有帮助。假设你想预测谁会患肺炎。原始数据的前几行是这样的:
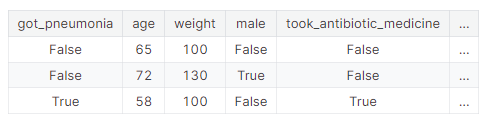
人们在感染肺炎后服用抗生素药物以恢复健康。原始数据显示这些列之间存在很强的关系,但是在确定got_pneumonia的值之后,tok_antibiotic _medicine经常发生变化。这是目标泄漏。该模型将会发现,任何took_antibiotic_medicine的值为False的人都没有肺炎。由于验证数据来自与训练数据相同的来源,模式将在验证中重复自己,并且模型将具有很高的验证(或交叉验证)分数。
但是,这个模型随后在现实世界中应用时将非常不准确,因为即使是患肺炎的病人,在我们需要预测他们未来的健康状况时,也还没有接受抗生素治疗。为了防止这种类型的数据泄漏,应该排除在实现目标值之后更新(或创建)的任何变量。
6.3训练-测试集污染
没有仔细区分训练数据和验证数据时,会发生另一种类型的泄漏。回想一下,验证的目的是衡量模型如何处理以前没有考虑过的数据。如果验证数据影响预处理行为,则会以微妙的方式破坏此过程。这有时被称为训练-测试集污染。
例如,假设在调用train_test_split()之前运行预处理(比如为缺失的值拟合一个输入器)。最终结果如何?模型可能得到很好的验证分数,但是当部署它来做决策时,表现很差。毕竟,我们将来自验证或测试数据的数据合并到如何进行预测中,因此即使无法推广到新数据,也可能在特定数据上做得很好。当进行更复杂的特征工程时,这个问题变得更加危险。
如果验证基于简单的训练-测试分割,请从任何类型的拟合(包括预处理步骤的拟合)中排除验证数据。如果使用scikit-learn管道,这将更容易。在使用交叉验证时,更重要的是在管道中进行预处理!
我们将使用关于信用卡应用程序的数据集,并跳过基本的数据设置代码。最终结果是关于每个信用卡应用程序的信息存储在DataFrame x中。我们将使用它来预测哪些应用程序在Series y中被接受。
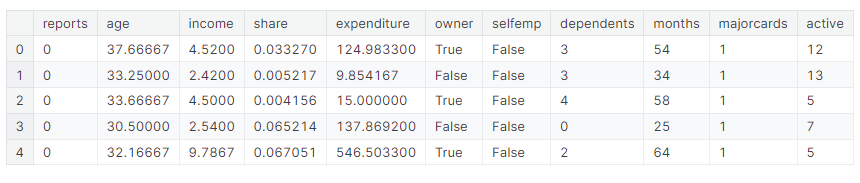
由于这是一个小数据集,我们将使用交叉验证来确保模型质量的准确度量。
python
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
# 由于没有预处理,我们不需要管道(无论如何作为最佳实践使用!)
my_pipeline = make_pipeline(RandomForestClassifier(n_estimators=100))
cv_scores = cross_val_score(my_pipeline, X, y,
cv=5,
scoring='accuracy')
print("Cross-validation accuracy: %f" % cv_scores.mean())
---------------------输出----------------------------------
Cross-validation accuracy: 0.981052根据经验,会发现很难找到98%的准确率的模型。这种情况时有发生,但并不常见,我们应该更仔细地检查数据是否有目标泄漏。
例如,支出是指在这张卡上的支出还是在申请前使用的卡上的支出?在这一点上,基本的数据比较是非常有用的:
python
expenditures_cardholders = X.expenditure[y]
expenditures_noncardholders = X.expenditure[~y]
print('Fraction of those who did not receive a card and had no expenditures: %.2f' \
%((expenditures_noncardholders == 0).mean()))
print('Fraction of those who received a card and had no expenditures: %.2f' \
%(( expenditures_cardholders == 0).mean()))
--------------------输出-----------------------
Fraction of those who did not receive a card and had no expenditures: 1.00
Fraction of those who received a card and had no expenditures: 0.02如上所示,所有没有收到卡片的人都没有支出,而只有2%的收到卡片的人没有支出。我们的模型似乎具有很高的准确性,但这似乎也是目标泄露的情况,其中的支出可能是指他们申请的信用卡上的支出。由于份额部分由支出决定,它也应该被排除在外。变量active和majorcards不太清楚,但从描述来看令人担忧。在大多数情况下,如果无法找到创建数据的人以了解更多信息,那么安全总比担忧好。我们将运行一个没有目标泄漏的模型如下:
python
# 从数据集中删除泄漏的预测器
potential_leaks = ['expenditure', 'share', 'active', 'majorcards']
X2 = X.drop(potential_leaks, axis=1)
# 在去掉有漏洞的预测因子后评估模型
cv_scores = cross_val_score(my_pipeline, X2, y,
cv=5,
scoring='accuracy')
print("Cross-val accuracy: %f" % cv_scores.mean())
----------------------输出---------------------
Cross-val accuracy: 0.830919这个精度相当低,这可能令人失望。然而,在新应用程序上使用时,我们可以期望它在80%的时间内是正确的,而泄漏模型可能会比这差得多(尽管它在交叉验证中明显得分更高)。
在许多数据科学应用程序中,数据泄露可能是一个价值数百万美元的错误。仔细分离训练数据和验证数据可以防止训练测试污染,而管道可以帮助实现这种分离。同样,谨慎、常识和数据探索的结合可以帮助识别目标泄漏。